Dimension errors when using sklearn OneHotEncoder with min_frequency parameter #545
Comments
|
Hi @dclaz -- This appears to be a question for the interpret-community repo. Transferring your issue there. |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
The documentation suggests that the sklearn
OneHotEncodershould be a viable transformation when using theMimicExplainer, but I'm getting errors if I use it and set themin_frequencyparameter to remove category levels with low counts.If I set up my data preprocessor like this
(where I have ~7 categorical features, each with many levels)
I get the following error
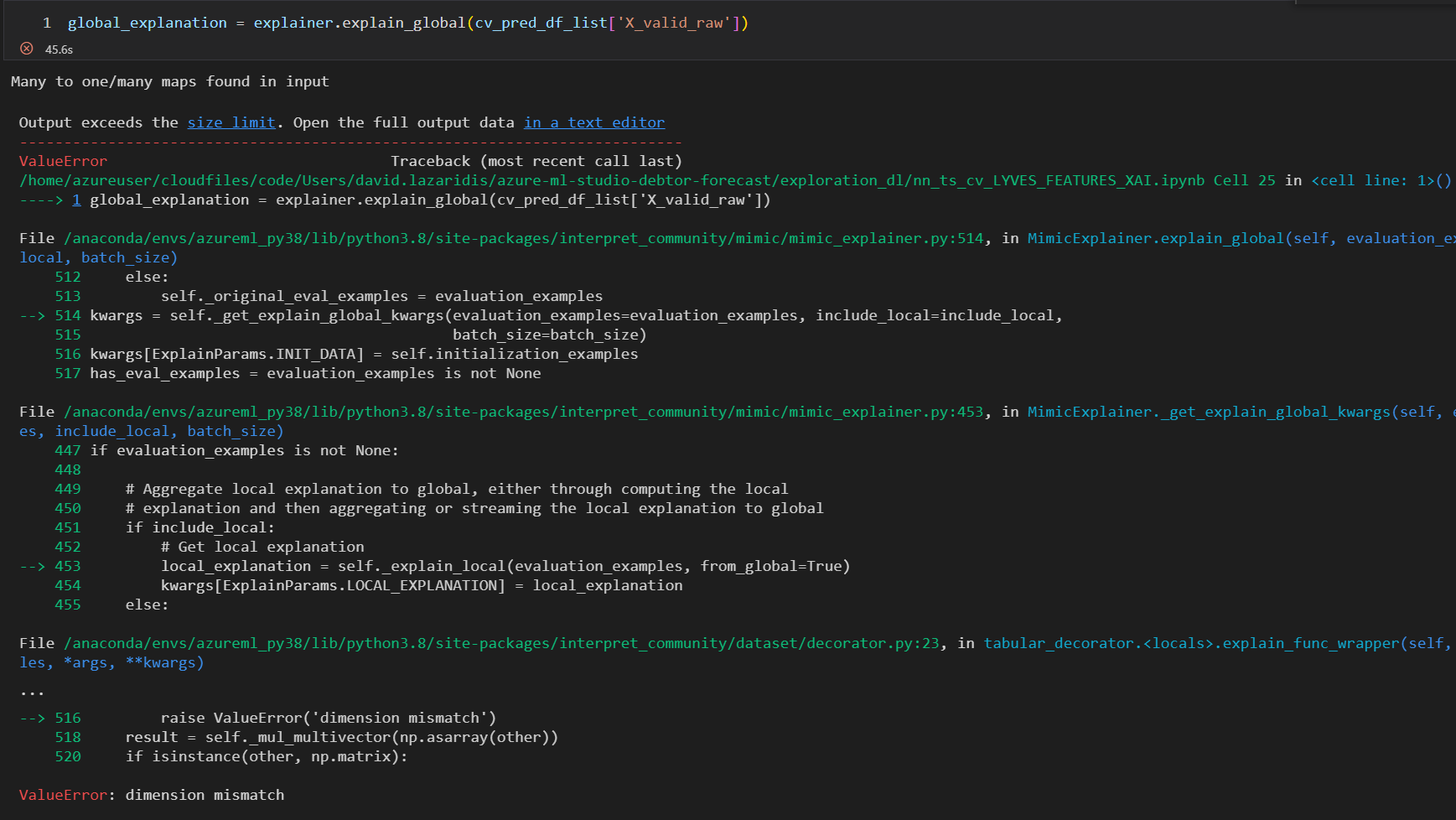
However, if I set a different transformer for each categorical feature, the Explainer works, albeit with a
Many to one/many maps found in inputwarning and produces outputs that don't really make sense (Half the features end up having very, very similar SHAP values).The text was updated successfully, but these errors were encountered: