Allow dash - for entering ISBN-13 when submitting an edition of a book
#4343
Comments
|
@serv I would like to work on this issue |
|
that would be awesome and then it can automatically convert it to a number without the hyphen |
|
@serv instead of adding only dashes, I think we should add a proper validation function to check whether it satisfies the condition of isbn 13 or not as shown in the following snippet: |
|
@Sabreen-Parveen that looks great - adding the validation check after the hyphen/spaces are gone. I would actually recommend adding a comma and period to the list of characters to remove, as sometimes when copying/pasting, people may accidentally highlight those. Also you could add in letters too (except for X) as ones to remove, as maybe someone is putting that into the copy/paste too. The rest of the characters are fine to give a warning (unless I missed one). |
|
It’s great to test that it is a numerically-allowed isbn13, but not every such number corresponds to a published book. That can only be tested by searching for libraries holding it or vendors with available inventory. |
|
@LeadSongDog I would also say it would be ridiculous for someone to wait while the computer verifies if their ISBN is valid. What really is better is if someone puts in an ISBN (10 or 13), that the one they don't have magically appears. The reason is that it's so hard to look for a book with just one ISBN - whether it's the searcher or the search engine. To me, that's way more important than caring if the ISBN is correct or not - as that can be corrected. I may be wrong here, but from the user side - having more is better than less - as you can always remove, but being without during that time is hard. I'm not saying that your issue isn't valid, I'm saying the first priority is having 2 ISBNs at the same time and then the second priority is to have a crawler double check the ISBNs. I personally use BookFinder for all my stuff. |
|
@Sabreen-Parveen My sense is that we have two operations.
Please put these into two separate PRs because:
|
|
@cclauss good idea, as bookfinder doesn't have a way to download all their isbn's. |
|
I just wanted to say I'm really glad people are thinking about and are working on this issue. It's a common issue that I bet a lot of people face. |
|
I have noticed in the add books page there is no checking whether it has 13 digits or not so, we can simply add the isbn and the input element accepts the value. Should I add validation function in add books page also? The function will only check if the isbn has 13 digits or not and check for the dashes too. |
|
@Sabreen-Parveen everywhere is preferable - provided the dashes don't appear in what the public sees - it's important to keep the data consistent and concise for the data dumps - all those extra dashes are going to only increase the gb's there, which will make it much harder to use and store. It also costs more money. |
|
I don't think LeadSongDog was suggesting that the lookup actually be done, but before calling things "ridiculous," it would probably be worth weighing the benefit vs the cost. If an invalid ISBN could be flagged in 100 msec, that'd be totally worth the wait. This whole thing seems to have gone very far astray though. Dashes are actually good not only because they allow for cut-and-paste of real world data, but because they present the information in the form that users are familiar with. In my opinion, they should be preserved. The only place they need to be removed (or normalized) is in the normalized search field -- and there only needs to be one of those, you don't need both 10 & 13 digit forms since they're equivalent. So, the protocol should be:
And just for clarity, 50M ISBNs with a few dashes each is <0.2 GB and fractions of a penny. This work should be directed by someone that understands ISBNs, their usage in publishing, and search technology. |
Agreed.
Who would you recommend? |
|
@seabelis understands ISBNs. I'm not sure who you'd look to for search, but 95% of what you need is in my 2017 comment #609 (comment) Between the ol-tech mailing list, Github issues, etc there's plenty of institutional knowledge about how to do this correctly. It's just not present in this thread, so I'm trying to keep things from being hijacked. |
|
@tfmorris There are several reasonable options for external validation of ISBNs. It may be worth comparing response times. Possibilities include Google, Baidu, and other generic search engine giants, but we should consider more specific options too: |
|
@tfmorris I think there's some confusion, but I'm referring to the end-product, that the dashes don't appear in the data sets (unrelated to the website). I didn't bring up everything (as I don't want to derail, as I could, but I won't), but what I said can be problematic making everyone aware of every angle while working on this is supposed to help us stay on track. |
|
Strongly agree with @tfmorris "warn on, but don't disallow (since they're sometimes printed wrong), ISBNs with invalid check digits". |
Describe the problem that you'd like solved
When entering ISBN-13 when submitting an edition of a book, can you allow dashes? Currently only numbers allowed.

When I try to copy over the value from Amazon which has a dash in the value, the UI throws an error.
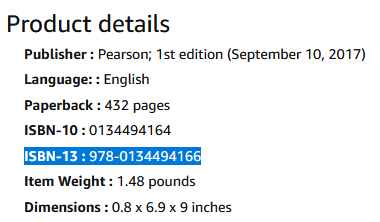
Proposal & Constraints
Allow dashes
Additional context
It seems like dashes are also allowed by https://www.isbn-13.info/
Stakeholders
The text was updated successfully, but these errors were encountered: