Grafana Logs "database is locked" #16638
Comments
|
Can you describe your setup more, options, number of users, alerts, dashboards, provisioned dashboards, alert evaluation frequency etc. |
|
I have the same issue too. Graphite, Grafana, Postgresql 9.6. |
|
Another services working correctly with the same db. |
|
I am having a similar issue using influxdb. Grafana works well for a while then all of sudden crashes and logs out. Grafana v6.1.6 (commit: cf9cb45), Ubuntu 16.04. t=2019-05-14T00:36:04-0600 lvl=eror msg="Failed to get system stats" logger=metrics error="database is locked" |
|
Same issue here. Running on an EC2 instance: prometheus, grafana, and a couple of my own services. Browser open to grafana, and that's it. No other services hitting grafana. Everything is fine for a few minutes, then at some point grafana craps itself with "database is locked" errors, and then it doesn't work, and it won't start back up. |
|
When it says "database" is locked, is it referring to the influxdb data source or to the grafana database which I believe contains information about the dashboard, settings, etc and is an SQLite database by default? I am running influxdb on a KVM VM and grafana on a separate KVM VM. It would be nice to know if I should be trying to tune influx or grafana. |
|
@cuxcrider This is a problem with grafana's default sqlite db. |
|
Any idea if switching to postgres or mysql solves the problem? |
|
No, and I don't really have any interest in that, because part of what I'm working on is zero-config (or near-zero-config) setup for dev environments. Having to configure a different DB as a backend is a non-starter for me. |
|
I hear ya there. Would much prefer it to just "work". I might give it a shot, I found some info here: |
|
fyi I just set up grafana on a new VM and setup mysql using the guide I pasted above. I then exported my dashboards as JSON and inserted them into my new grafana and so far, so good. No crashing. You can maybe convert your SQLite to mysql if you have a ton of stuff already setup, but my grafana was pretty minimal so I just exported my dashboards as json and then manually reconnected to data sources. |
|
I have similar issue when garafana suddenly stop working, and restarting doesn't fix this problem :( |
|
Same problem here. t=2019-05-17T11:41:00-0300 lvl=eror msg="failed to look up user based on cookie" logger=context error="database is locked" Starts to happen when upgraded to Grafana 6. |
|
I've got same issue. Grafana 6.1.6 @ Debian 4.9.168 in docker (image grafana/grafana:6.1.6) |
|
Same issue here v.6.1.6 |
|
This seems to be an issue with sqlite itself, one way to recover the sqlite databse is to follow the procedure here: https://community.grafana.com/t/database-is-locked-unable-to-use-grafana-anymore/16557/2 The “database is locked” error indicates a problem with your sqlite database. This can happen if the database is left in an inconsistent state after a crash, or if there are problems with the disk. One thing you can try is to dump the data from your existing db file into a new one, then swap it out. From inside your Grafana data directory (after shutting down Grafana): |
#17276) Adds an additional sqlite error code 5 (SQLITE_BUSY) to the transaction retry handler to add retries when sqlite returns database is locked error. More info: https://www.sqlite.org/rescode.html#busy Ref #17247 #16638
|
We have that a lot sinci grafana 6.2 (we use auth proxy) |
|
I ran into the same issue while using app service in azure. I solved the issue by changing the app planning parameter Capacity from 2 to 1. Hope this helps someone else too.... |
WHere exactly it is this setting in app service??? |
Hi there, It is in the "app service plan" In the portal you can find this parameter under the app service plan menu-->settings-->properties. Just to be clear, you should also first change the connection string to: However, for me it started to work only after I also change the capacity parameter as I mentioned. Good luck and let me know if it is working |
|
We are also facing same issue. Error occurred for both cloud-watch (5 rules) and influx-db (25 rules) as data source. Grafana 8.2.1 |

Considering that is it not possible to `limit` the number of units which may be started in a Juju application, it's possible for more than one Grafana unit to be initialized. MOST of the data which is present is propagated though libraries and across relation interfaces as dashboards/datasources, but user interaction and logins with the Grafana UI itself may result in changes. Without a shared database, scaling the application up or down could result in units with different administrative passwords, dashboards imported from the marketplace, manually added users/groups, or more. When a charm is elected as the leader, it will now start `litestream` to serve changes over GRPC/HTTP. This additionally requires changing the a sqlite pragma to Grafana. However, this is a long-requested feature for Grafana itself, with hundreds of users reporting that it actually reduced the frequency of database locking [see the issue](grafana/grafana#16638), so this is reasonably safe.
|
Same issue here.
This also causes various alerts to fire with no values. I have not yet found a pattern in which alerts will be affected. |
As I understand it setting wal in the db should be persistent and can't be changed by any application/connection. |
|
Yes, I was unclear. I meant the change is permanent indeed and it should apply (by default) to all new Grafana connections, unless Grafana explicitly specifies a different connection method (overriding this new permanent default). BTW the issue never reappeared here so the sqlite3 method did the trick. I just can't explain why the issue persisted a few days after the fix. |
|
I just did the wal change and still get this in the logs: I recently started to investigate if Grafana ngalert could be a contender to Alertmanager since I feel that Grafana has a nice UI however I'm running in to weird problems. One issue particular where all my alerts would get resolved and then a couple of minutes later gets in alert/firing mode again. I have the same alerts configured in Alertmanager and they stay in alert/firing mode there which is the correct state. I'm suspecting this is caused by database locks but not sure really |
|
Update: It's now been 4days since I changed the DB to use wal and it seems to have solved the issue I had where all my alerts would suddenly get in resolved state. I can still see this in the logs however it does not seem to affect anything since I don't have any issues. |
|
For a Grafana that deployed into Kubernetes cluster is not possible to execute 'sqlite3' command. https://github.com/grafana/grafana/blob/main/conf/defaults.ini#L123 |
* Add sqlite streaming from primaries to secondaries Considering that is it not possible to `limit` the number of units which may be started in a Juju application, it's possible for more than one Grafana unit to be initialized. MOST of the data which is present is propagated though libraries and across relation interfaces as dashboards/datasources, but user interaction and logins with the Grafana UI itself may result in changes. Without a shared database, scaling the application up or down could result in units with different administrative passwords, dashboards imported from the marketplace, manually added users/groups, or more. When a charm is elected as the leader, it will now start `litestream` to serve changes over GRPC/HTTP. This additionally requires changing the a sqlite pragma to Grafana. However, this is a long-requested feature for Grafana itself, with hundreds of users reporting that it actually reduced the frequency of database locking [see the issue](grafana/grafana#16638), so this is reasonably safe. * Update integration tests, fetch+push static sqlite so we can stay airgapped * Add traefik v1, use litestream 0.4.0, update deployment doc * Restructure leader arg/check, add comments about necessity of peer data change events * Use a single password function for all units, since it's replicated * Use the newest image * Improve restart reliablility -- refresh dashboards faster, no need to restart; don't restart replicas on datasource change; force the types in _build_layer() to match the types from a running layer (Pebble should do this anyway, but does not) * Update unit test * Specify a refresh_event for prometheus with multiple containers, add unit tests, update integration tests action properties * Add the litestream resource to the resource limits integration test, too * Fix arg from merge * Add a container poller * Don't try to set peer data if we're not the leader
|
Any suggestions on how to fix this in k8s deployment? |
|
|
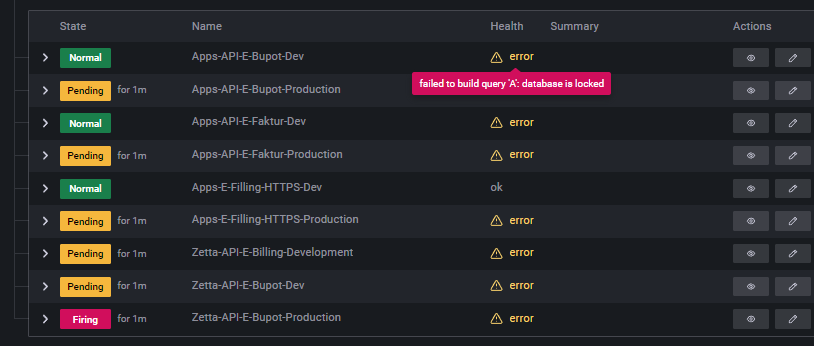
|
I have the same issue, happens on save but also on alert evaluation Version is 9.3.2 logger=ngalert.scheduler rule_uid=aLHc4khVz org_id=1 version=3 attempt=0 now=2023-01-05T11:03:00Z t=2023-01-05T11:03:10.014606251Z level=error msg="Failed to build rule evaluator" error="failed to build query 'A': database is locked"
|
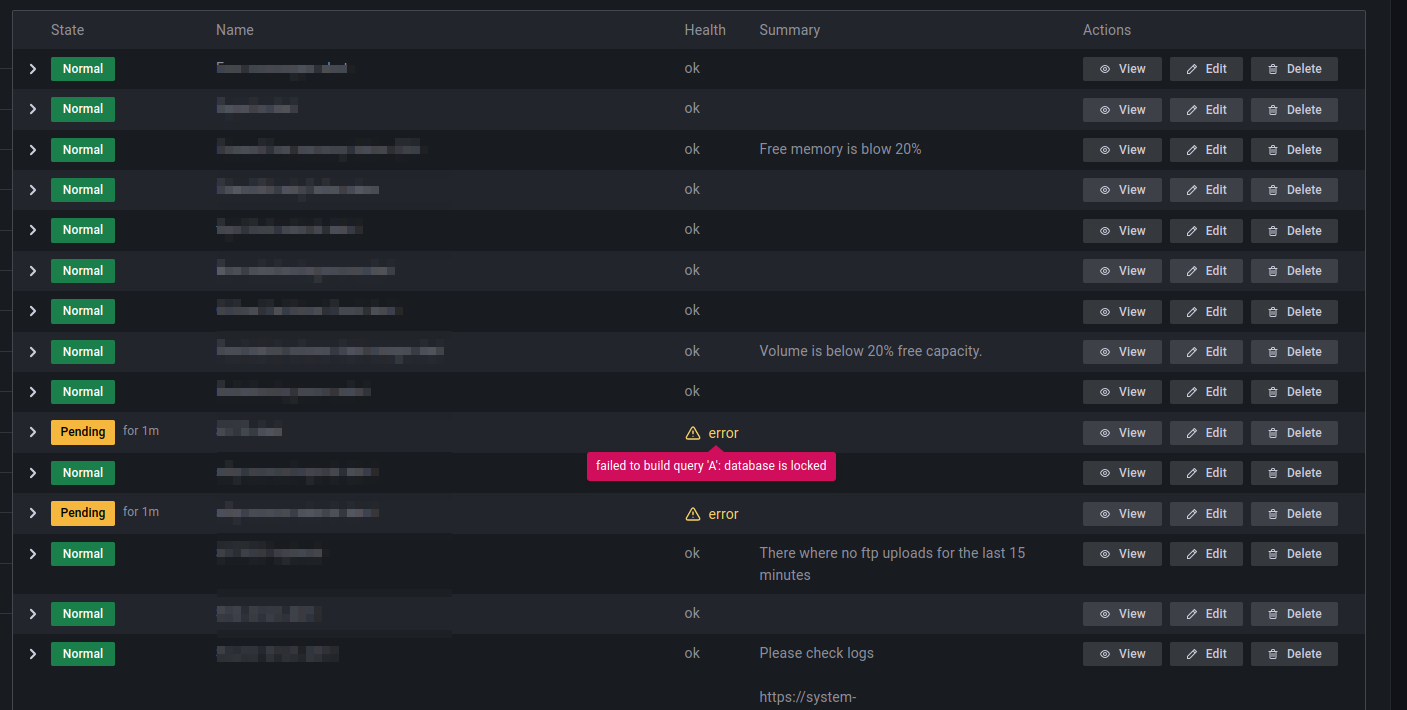
|
Version 9.3.6 is also faceing the same issue, when building alert rules with Prometheus datasource. |
This seems to fix the issue on version 9.3.1 |
|
From Grafana v9.4.0 you'll be able to enable |
|
Hi, I have got similar problem in postgresql 14 + timescaledb 2.9.1 with grafana 9.3.1. Every midnight I get DatasourceError alerts (some repeats every day, others show occasionally, but it always happens at midnight). When examining the data, it does not look like there would be anything missing. However I once caught it exactly at midnight when I tried to run alert query and I have got this error in grafana window: I was not sure if the issue is on timescaledb side or grafana, but I have noticed grafana has some troubles with this already. |
also solved by |
|
Today we found majority of our dashboards somehow anonymously reverted to a previous version. Under version history, the Updated by field is blank and the Notes field is blank. It does not state "Restored from version xx". I had to manually go to every dashboard and restore from previous version. The only thing I could find in the logs were a few vague "database is locked" messages. What process could do this? I need to ensure this doesn't happen again. |
|
We're also seeing a similar problem. Setting the Environment:
|

|
I had the same issue and found that my storage provider Azure File was not working with the Helm Chart. Switching to Azure Disk storage resolved the issue |
|
It's still relevant. |
|
Same issue for me with the latest release |
|
At the time of writing this is still unresolved. I've got a samba server containing the A solution seems to be to migrate to postgreSQL, for which this tool exists: https://github.com/wbh1/grafana-sqlite-to-postgres |
|
While WAL mode is helpful, it seems like the _busy_timeout parameter may also help alleviate the issues. It sets the sqlite busy timeout to the specified value, which will cause sqlite to retry transactions before giving up and returning the busy aka "database is locked" error. You can set that and WAL mode (note that once you switch a given sqlite db to WAL mode you cannot switch back) via the following database config: Other sqlite-specific settings like |
What happened:
At some point, Grafana gets an error.
Log out with the error "database is locked."
The following are some of Grafana's logs:
lvl=eror msg="failed to look up user based on cookie" logger=context error="database is locked"Environment:
The text was updated successfully, but these errors were encountered: