Rethinking the Queue class to get full GPU utilization #393
Comments
|
Hi, @dmus. I haven't fully understood how this works, but it certainly looks promising. So would the samplers need to be reimplemented as well? How random is this? The way the current queue works is
This ensures that batches of patches come from different subjects. Is this also ensured? And would all the subjects be sampled as well? If this works well, we could synchronize it with the release of PyTorch 1.8. What tool do you use to visualize GPU utilization? |
|
The tool for GPU utilization is Grafana. This uses the existing samplers, no need for reimplementation. How this custom queue works is:
Each worker picks a random subject, so in that way patches come from different subjects. The buffer size should be large enough to have samples from different subjects I also tried with a map-style Dataset instead of an iterable dataset for the PatchesDataset. Then each subjects is sampled once, but I was getting (small) gaps in GPU utilization with this approach
In theory when you sample long enough you should have about the same number of samples from each subject |
|
Nice. Using a map-style dataset would ensure that patches are extracted from each subject once, and would let us define an epoch, right? I'm not sure why that approach would be less optimized than the iterable dataset. |
Yes that is right
I also don't know. Maybe because after each epoch things have to be initialized again, but not sure |
|
The buffered shuffle dataset seems to be available in the nightly version: I won't have much time in the next two months. Would you like to submit a PR with your proposal? I thought that |
|
I will test and work it out a bit more and then submit a PR |
|
To come back to this issue. The implementation now looks like this class BatchedPatchesDataset(IterableDataset):
def __init__(self, subjects_datasets, weights, sampler, samples_per_volume):
self.subjects_datasets = subjects_datasets
self.weights = weights
self.sampler = sampler
self.samples_per_volume = samples_per_volume
def __iter__(self):
while True:
sampled_dataset = random.choices(population=self.subjects_datasets, weights=self.weights)[0]
idx = random.randint(0, len(sampled_dataset) - 1)
sample = sampled_dataset[idx]
iterable = self.sampler(sample)
patches = list(islice(iterable, self.samples_per_volume))
yield patches
class UnbatchDataset(IterableDataset):
def __init__(
self,
dataset: Dataset,
num_workers: int = 0,
):
self.loader = DataLoader(dataset,
batch_size=None,
num_workers=num_workers)
def __iter__(self):
for batch in self.loader:
yield from batchTo use it: # This yields a dataset with non random batches of batch_size 'samples_per_volume'
to_patches = BatchedPatchesDataset(subjects_datasets=[dataset],
weights=[1], # Only relevant when sampling from multiple subject datasets
sampler=sampler,
samples_per_volume=samples_per_volume)
# Unbatch the batches
patches_unbatched = UnbatchDataset(to_patches, num_workers)
# Shuffle to get the patches in a random order
queue = BufferedShuffleDataset(patches_unbatched, max_queue_length)
patches_loader = DataLoader(queue, batch_size=batch_size)
for i, patches_batch in enumerate(patches_loader):
inputs = patches_batch['ct'][tio.DATA].numpy()
targets = patches_batch['labels'][tio.DATA].numpy()For my use case this gives good gpu utilization and a big speed up. But it would be good to also know about other use cases. Shall I submit a pull request? |
|
Hi, @dmus. This looks interesting. It's nice to be able to leverage newer PyTorch classes. I have some questions:
In summary, it would be great to make this sample once from each subject at each epoch and to understand a bit what each class is doing. |
|
|
As found by dmus, we have also encoutered this "issue" (i.e. not full use of GPU). Is there a way to use TorchIO with queues optimized for GPU ? |
|
no solution has been incorporated into current torchio, |
|
I've tried to use dmus's solution. GPU is fully used but the training does not end ! To avoid the gaps mentioned by dmus, within current TorchIO, what do you recommend ?
|
|
Hi, @rousseau. I do recommend a long queue, multiple workers (sometimes fewer than the maximum is faster, for example I typically use 12/40 in a DGX after benchmarking), many samples per volume, and fast transforms (avoid RandomElasticDeformation, RandomMotion, maybe RandomBiasField). If you have a lot of storage, you can store your images uncompressed (e.g. |
|
Building on top of what @dmus suggested and following what @fepegar implemented on the import random
from itertools import islice
import torch
import torchio as tio
from torch.utils.data import IterableDataset
class Queue(IterableDataset):
def __init__(
self,
subjects_dataset: tio.SubjectsDataset,
sampler: tio.data.PatchSampler,
samples_per_volume: int,
shuffle_subjects: bool = True,
shuffle_patches: bool = True,
buffer_size: int = 0,
):
if shuffle_patches and not buffer_size:
m = "The `buffer_size` parameter must be defined when shuffling patches."
raise ValueError(m)
self.subjects_dataset = subjects_dataset
self.sampler = sampler
self.samples_per_volume = samples_per_volume
self.shuffle_subjects = shuffle_subjects
self.shuffle_patches = shuffle_patches
self.buffer_size = buffer_size
@property
def num_subjects(self) -> int:
return len(self.subjects_dataset)
@property
def iterations_per_epoch(self) -> int:
return self.num_subjects * self.samples_per_volume
def __len__(self):
return self.iterations_per_epoch
def __iter__(self):
worker_info = torch.utils.data.get_worker_info()
num_workers, worker_id = 1, 0
if worker_info is not None:
num_workers, worker_id = worker_info.num_workers, worker_info.id
# Subject indices to get from the dataset.
indices = self.split_among_workers(self.num_subjects, num_workers, worker_id)
# For the buffer size we split the total buffer size among each worker.
buffer_rng = self.split_among_workers(self.buffer_size, num_workers, worker_id)
buffer_size = buffer_rng.stop - buffer_rng.start # Need the size not range
buffer = []
if self.shuffle_subjects:
indices = random.sample(indices, indices.stop - indices.start)
for index in indices:
subject = self.subjects_dataset[index]
patches = islice(self.sampler(subject), self.samples_per_volume)
if not self.shuffle_patches:
yield from patches
continue
for patch in patches:
if len(buffer) == buffer_size:
idx = random.randint(0, buffer_size - 1)
yield buffer[idx]
buffer[idx] = patch
else:
buffer.append(patch)
random.shuffle(buffer)
while buffer:
yield buffer.pop()
@staticmethod
def split_among_workers(n: int, num_workers: int, worker_id: int) -> range:
"""
Generates a range of indices up to `n` assigned to worker with id `worker_id`
from a total pool of `num_workers`.
For a single worker it will be composed of the full range:
>>> Queue.split_among_workers(5, 1, 0)
range(0, 5)
For multiple workers it will depend on the id assigned to the worker. In case
the total number is not divisible by the number of workers the remaining m
values, for m < num_workers, will be assigned to the first m workers:
>>> Queue.split_among_workers(5, 2, 0)
range(0, 3)
>>> Queue.split_among_workers(5, 2, 1)
range(2, 5)
"""
if worker_id >= num_workers:
m = (
f"The worker id provided `{worker_id}` must be less than the total "
f"number of workers `{num_workers}`"
)
raise ValueError(m)
per_worker, remaining = divmod(n, num_workers)
start = per_worker * worker_id + min(remaining, worker_id)
end = start + per_worker + remaining // (worker_id + 1)
return range(start, end)This implementation will ensure each of the subjects is sampled once and only once per epoch with the given number of
Any suggestions are welcome and If anyone manages to try it out and measure their GPU utilization let me know 🙌 The other approach with the class Queue(IterableDataset):
def __init__(
self,
subjects_dataset: tio.SubjectsDataset,
sampler: tio.sampler.PatchSampler,
samples_per_volume: int,
shuffle_subjects: bool = True,
):
self.subjects_dataset = subjects_dataset
self.sampler = sampler
self.samples_per_volume = samples_per_volume
self.shuffle_subjects = shuffle_subjects
indices = range(len(self.subjects_dataset))
if self.shuffle_subjects:
indices = random.sample(indices, indices.stop - indices.start)
self._indices_queue = SimpleQueue()
for index in indices:
self._indices_queue.put(index)
def __iter__(self):
while not self._indices_queue.empty():
index = self._indices_queue.get()
subject = self.subjects_dataset[index]
yield from islice(self.sampler(subject), self.samples_per_volume)Note that it needs recreating the |
|
Implementation is updated in the meantime to use the Torch DataPipes (see https://github.com/pytorch/data): from itertools import islice
import torchio as tio
from torch.utils.data import DataLoader
from torch.utils.data import IterDataPipe
from torch.utils.data.datapipes.iter import Shuffler, UnBatcher
batch_size = 32
num_workers = 8
samples_per_volume = 20
sampler = tio.UniformSampler(patch_size=64)
class PatchesSampler(IterDataPipe):
def __init__(self, datapipe, sampler, samples_per_volume):
self.datapipe = datapipe
self.sampler = sampler
self.samples_per_volume = samples_per_volume
def __iter__(self):
for subject in self.datapipe:
iterable = self.sampler(subject)
yield list(islice(iterable, self.samples_per_volume)) # in my experience this turned out to be faster than using yield from islice(iterable, self.samples_per_volume)) and removing the UnBatcher
datapipe = PatchesSampler(my_dataset, sampler, samples_per_volume)
datapipe = DataLoader(datapipe, batch_size=None, num_workers=num_workers)
datapipe = UnBatcher(datapipe)
datapipe = Shuffler(datapipe, buffer_size=batch_size * samples_per_volume)
dataloader = DataLoader(datapipe, batch_size=batch_size)
while True:
for batch in dataloader:
... |
Hi, Thank you very much! This does increase the utilization. However, It seems that I have to always set num_workers=0 in this case, and could you please explain a bit why the first batchsize in DataLoader is None and buffer size is batch_size * samples_per_volume? Thanks a lot! |
|
First of all, thank you for this wrapper package and to @dmus to assess this issue as this has been a major limit in my case. However, using the last proposition, if I use num_workers > 0 in However, this is not raise with num_workers = 0 or if num_workers > 0 and pin_memory = True but the latter leads to memory leak. This is not a memory issue as I have access to 255 CPUs and a NVIDIA-SMI 510.47.03 with 40Gb of memory. Have you encounter such issue? Chears, -- Edit -- Chears, Tiago |
This is a really nice framework, however a serious issue for me is (the lack of) GPU utilization. This is an issue even with only a simple ZNormalization and a left right flip of the data as augmentation. This results in the following GPU utilization:
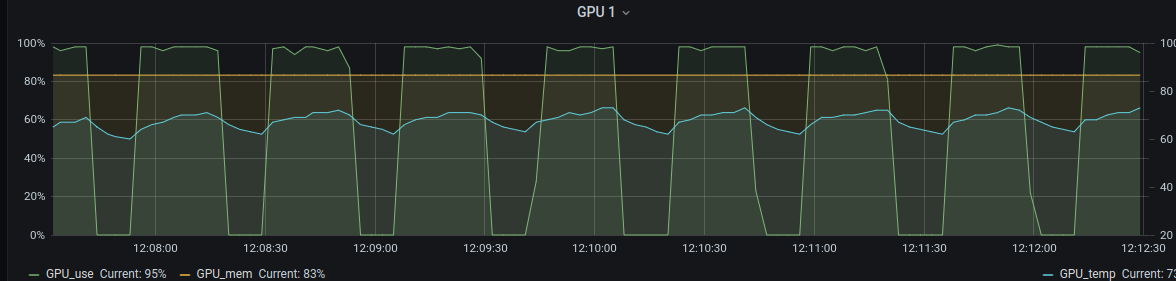
This is a training with 5 subjects and sampling 40 patches per volume and batch size 8. After every 25 iterations (which means 200 patches) there is a gap and the GPU utilization is 0.
What I did is building a custom Queue class in which I tried to get full GPU utilization. The result is as follows:
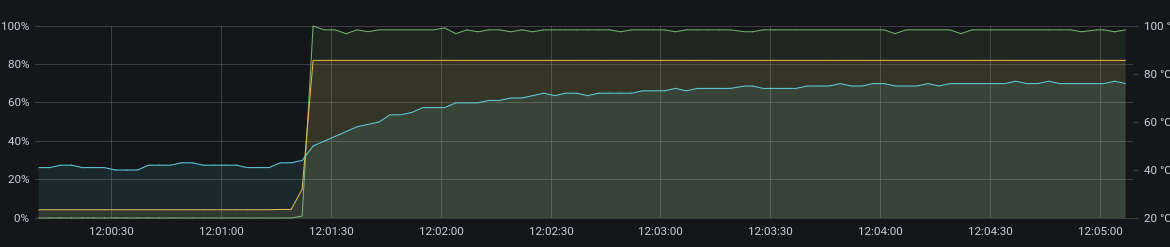
As you can see this has a GPU utilization of ~100% without gaps (0 utilization is before the start).
I tried to use the existing PyTorch data functionalities as much as possible. The BufferedShuffleDataset is something that is not yet in the release, but seems to be in the next release. The idea behind it is the same as for the shuffle() in Tensorflow data.
Here is the code that I made:
As you can see I had to do:
because otherwise I got this error: RuntimeError: received 0 items of ancdata
This may be something in the system that I use, but it seems to be a more common thing, see:
pytorch/pytorch#973
With using this custom implementation I could use:
What do you think of this? Could this replace or exist next to the existing tio.Queue?
The text was updated successfully, but these errors were encountered: