ERROR: core/context_gpu.cu:343: out of memory Error from operator #61
Comments
|
This is the wrong message(from 7th line): json_stats: {"accuracy_cls": 0.893479, "eta": "4 days, 10:07:39", "iter": 740, "loss": 1.423568, "loss_bbox": 0.228167, "loss_cls": 0.507030, "loss_mask": 0.479276, "loss_rpn_bbox_fpn2": 0.027880, "loss_rpn_bbox_fpn3": 0.013740, "loss_rpn_bbox_fpn4": 0.012587, "loss_rpn_bbox_fpn5": 0.007560, "loss_rpn_bbox_fpn6": 0.010346, "loss_rpn_cls_fpn2": 0.041581, "loss_rpn_cls_fpn3": 0.019604, "loss_rpn_cls_fpn4": 0.017486, "loss_rpn_cls_fpn5": 0.009906, "loss_rpn_cls_fpn6": 0.001322, "lr": 0.005000, "mb_qsize": 64, "mem": 10198, "time": 1.063462} |
|
Memory usage for this model is right on the edge of what can fit in a 12GB GPU. When I run it, I observe lower GPU memory usage (10498MiB / 11443MiB on an M40). I'm using a newer version of cuDNN (6.0.21), which maybe has more memory efficient implementations for some ops? You could try upgrading. Otherwise, you can reduce memory by ~50% by setting |
|
Hi @rbgirshick and tried on 4gpus (each 6G mem); the training is okay without out of mem; however, when it proceeds to testing, OOM occurs. Why such a discrepancy? |
|
Closing as the original was issue addressed. |
Hi!
I tried to train the mask_rcnn with e2e_mask_rcnn_R-101-FPN_2x.yaml and 4 gpu, running the code
python2 tools/train_net.py
--multi-gpu-testing
--cfg configs/12_2017_baselines/e2e_mask_rcnn_R-101-FPN_2x.yaml
OUTPUT_DIR result/m_4gpu
But I encouontered an error as follows.

I already checked the subprocess.py in my files refered to problem "c941633" and the code had already fixed. According to the following picture, which printed just few seconds before the network running error, I used {CUDA_VISIBLE_DEVICES 4,5,6,7}. And seems that truly it about ran out of memory.
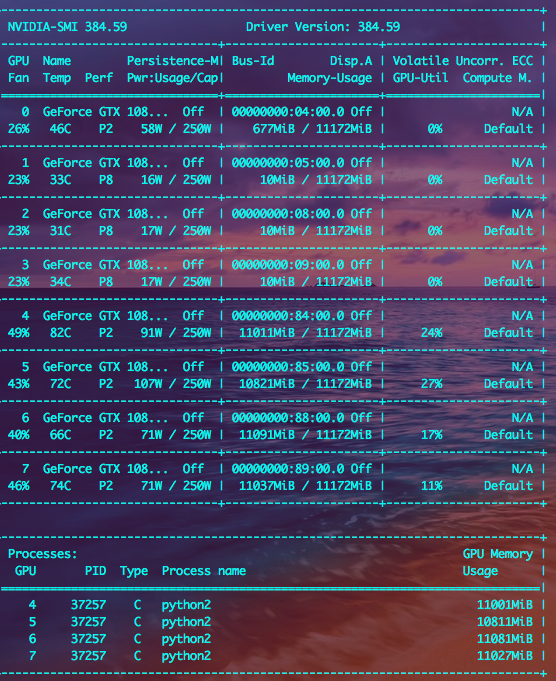
Is there anything wrong with my settings?Or maybe the project truly needs large memory?
My OS:Ubuntu 14.04.5 LTS (GNU/Linux 4.4.0-31-generic x86_64)
My cuda:Cuda compilation tools, release 8.0, V8.0.44
My cudnn:v5.1.5
Hope you can reply me soon.Thanks a lot!
The text was updated successfully, but these errors were encountered: