Split bijector #101
Assignees


Labels
enhancement
New feature or request
Comments
|
Comment of the above: class ReshapeBijector(Bijector):
def __init__(self, bijector):
...
self.bijector = bijector
def _forward(self, x):
x_reshape = self._reshape_op(x)
y_reshape = self.bijector(y_reshape)
y = self._inv_reshape_op(y_reshape)
return y
def _inverse(self, y):
y_reshape = self._reshape_op(y)
x_reshape = self.bijector.inverse(y_reshape)
x = self._inv_reshape_op(x_reshape)
return xAgain the advantage is clarity: we don't have bijectors with input and output domain that differ. |
Open
11 tasks
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
A splitting bijector splits an input
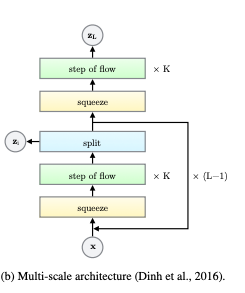
xin two equal parts,x1andx2(see for instance Glow paper):Of those, only
x1is passed to the remaining part of the flow.x2on the other hand is "normalized" by a location and scale determined byx1.The transform usually looks like this
The
_inverseis done like thisHowever, I personally find this coding very confusing:
First and foremost, it messes up with the logic
y = flow(x) -> dist.log_prob(y). What if we don't want a normal? That seems orthogonal to the bijector responsibility to me.Second, it includes in the LADJ a normal log-likelihood, which should come from the prior. Third, it makes the
_inversestochastic, but that should not be the case. Finally, it has an input of -- say -- dimensiondand an output ofd/2(and conversely for_inverse).For some models (e.g. Glow), when generating data, we don't sample from a Gaussian with unit variance but from a Gaussian with some decreased temperature (e.g. an SD of 0.9 or something). With this logic, we'd have to tell every split layer in a flow to modify the
self.normalscale!What I would suggest is this:
we could use
SplitBijectoras a wrapper around another bijector. The way that would work is this:The
_inversewould follow.Of course
bijectormust have the same input and output space!That way, we solve all of our problems: input and output space match, no weird stuff happen with a nested normal log-density, the prior density is only called out of the bijector, and one can tweak it at will without caring about what will happen in the bijector.
The text was updated successfully, but these errors were encountered: