| title | date | order | categories | tags | permalink | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
RPC 基础篇 |
2020-06-10 09:00:00 -0700 |
1 |
|
|
/pages/ab9f64/ |
RPC 的全称是 Remote Procedure Call,即远程过程调用。
RPC 的主要作用是:
- 屏蔽远程调用跟本地调用的差异,让用户像调用本地一样去调用远程方法。
- 隐藏底层网络通信的复杂性,让用户更聚焦于业务逻辑。
RPC 是微服务架构的基石,它提供了一种应用间通信的方式。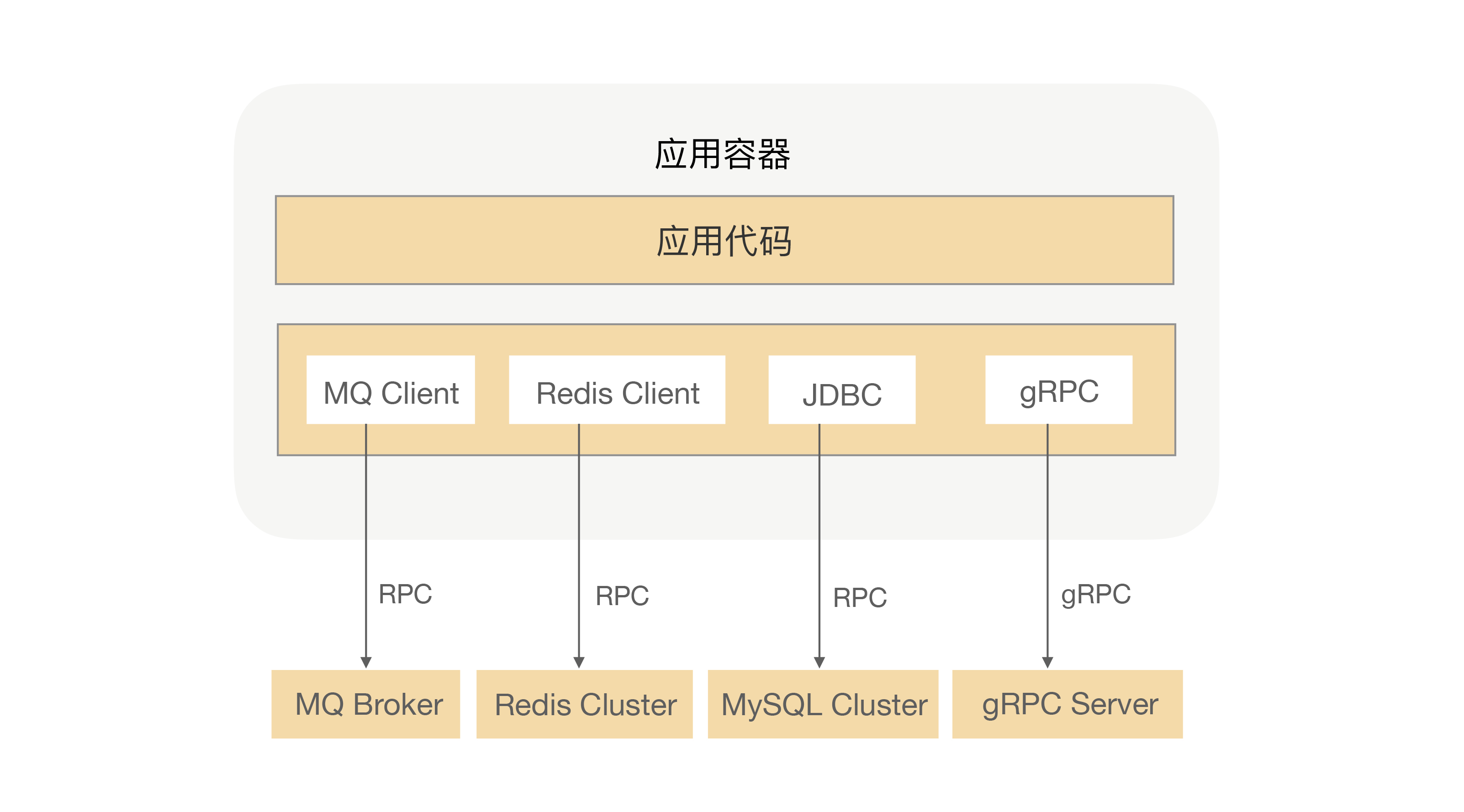
RPC 是一种应用间通信的方式,它的通信流程中需要注意以下环节:
- 传输方式:RPC 是一个远程调用,因此必然需要通过网络传输数据,且 RPC 常用于业务系统之间的数据交互,需要保证其可靠性,所以 RPC 一般默认采用 TCP 来传输。
- 序列化:在网络中传输的数据只能是二进制数据,而 RPC 请求时,发送的都是对象。因此,请求方需要将请求参数转为二进制数据,即序列化。
- 反序列化:RPC 响应方接受到请求,要将二进制数据转换为请求参数,需要反序列化。
- 协议:请求方和响应方要互相识别彼此的信息,需要约定好彼此数据的格式,即协议。大多数的协议至少分成两部分,分别是数据头和消息体。数据头一般用于身份识别,包括协议标识、数据大小、请求类型、序列化类型等信息;消息体主要是请求的业务参数信息和扩展属性等。
- 动态代理:为了屏蔽底层通信细节,使用户聚焦自身业务,因此 RPC 框架一般引入了动态代理,通过依赖注入等技术,拦截方法调用,完成远程调用的通信逻辑。
下图诠释了以上环节是如何串联起来的:
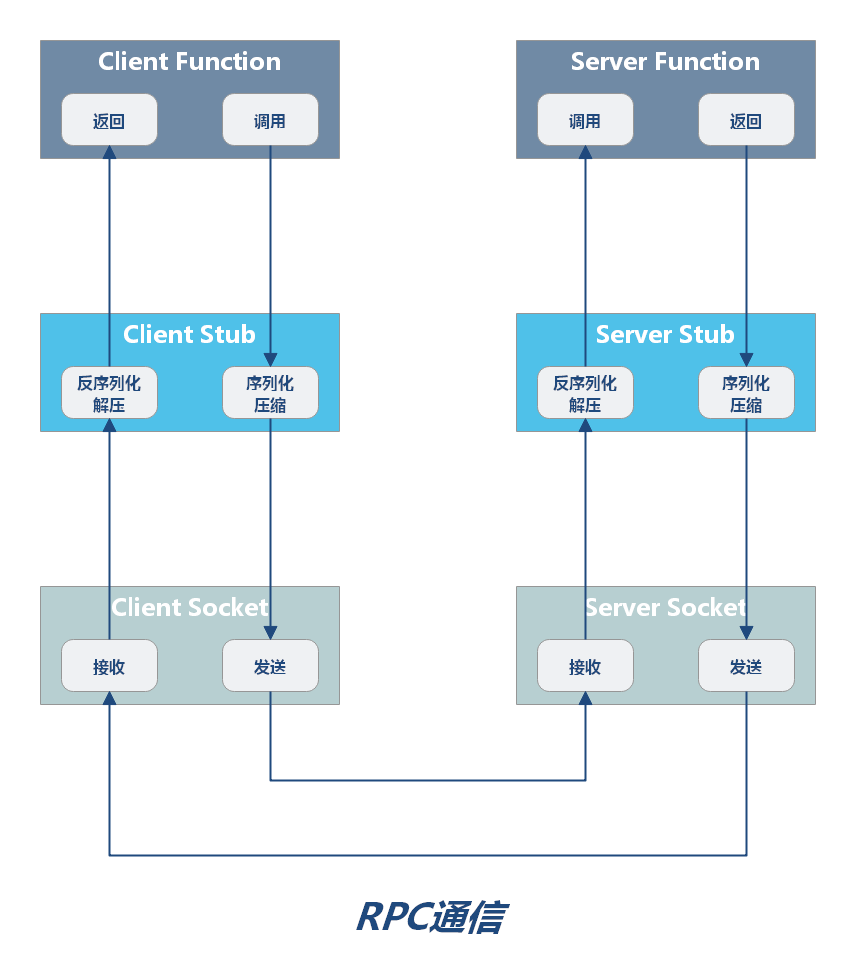
只有二进制才能在网络中传输,所以 RPC 请求在发送到网络中之前,他需要把方法调用的请求参数转成二进制;转成二进制后,写入本地 Socket 中,然后被网卡发送到网络设备中。
在传输过程中,RPC 并不会把请求参数的所有二进制数据整体一下子发送到对端机器上,中间可能会拆分成好几个数据包,也可能会合并其他请求的数据包(合并的前提是同一个 TCP 连接上的数据),至于怎么拆分合并,这其中的细节会涉及到系统参数配置和 TCP 窗口大小。对于服务提供方应用来说,他会从 TCP 通道里面收到很多的二进制数据,那这时候怎么识别出哪些二进制是第一个请求的呢?
这就好比让你读一篇没有标点符号的文章,你要怎么识别出每一句话到哪里结束呢?很简单啊,我们加上标点,完成断句就好了。
为了避免语义不一致的事情发生,我们就需要在发送请求的时候设定一个边界,然后在收到请求的时候按照这个设定的边界进行数据分割。这个边界语义的表达,就是我们所说的协议。
既然有了现成的 HTTP 协议,还有必要设计 RPC 协议吗?
有必要。因为 HTTP 这些通信标准协议,数据包中的实际请求数据相对于数据包本身要小很多,有很多无用的内容;并且 HTTP 属于无状态协议,无法将请求和响应关联,每次请求要重新建立连接。这对于高性能的 RPC 来说,HTTP 协议难以满足需求,所以有必要设计一个紧凑的私有协议。
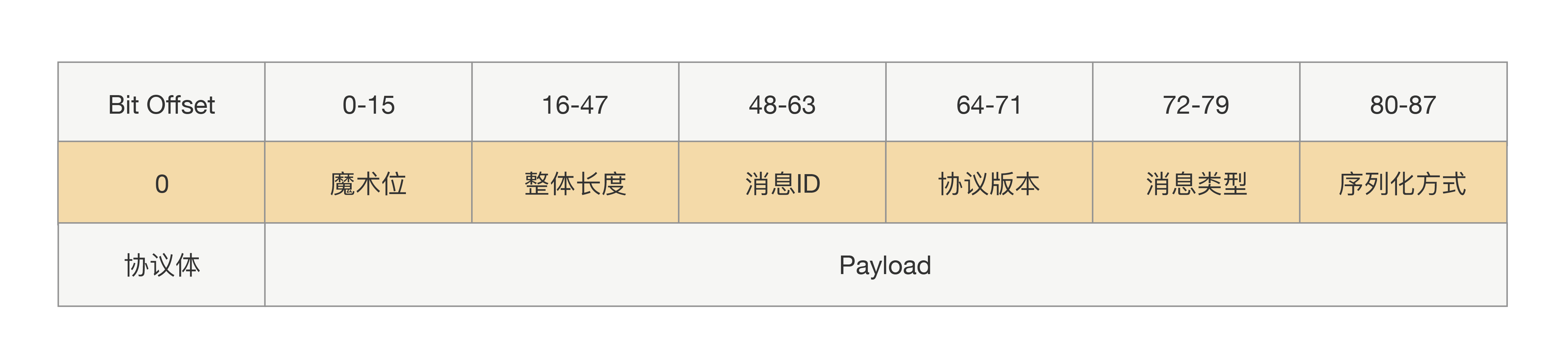
首先,必须先明确消息的边界,即确定消息的长度。因此,至少要分为:消息长度+消息内容两部分。
接下来,我们会发现,在使用过程中,仅消息长度,不足以明确通信中的很多细节:如序列化方式是怎样的?是否消息压缩?压缩格式是怎样的?如果协议发生变化,需要明确协议版本等等。
综上,一个 RPC 协议大概会由下图中的这些参数组成:
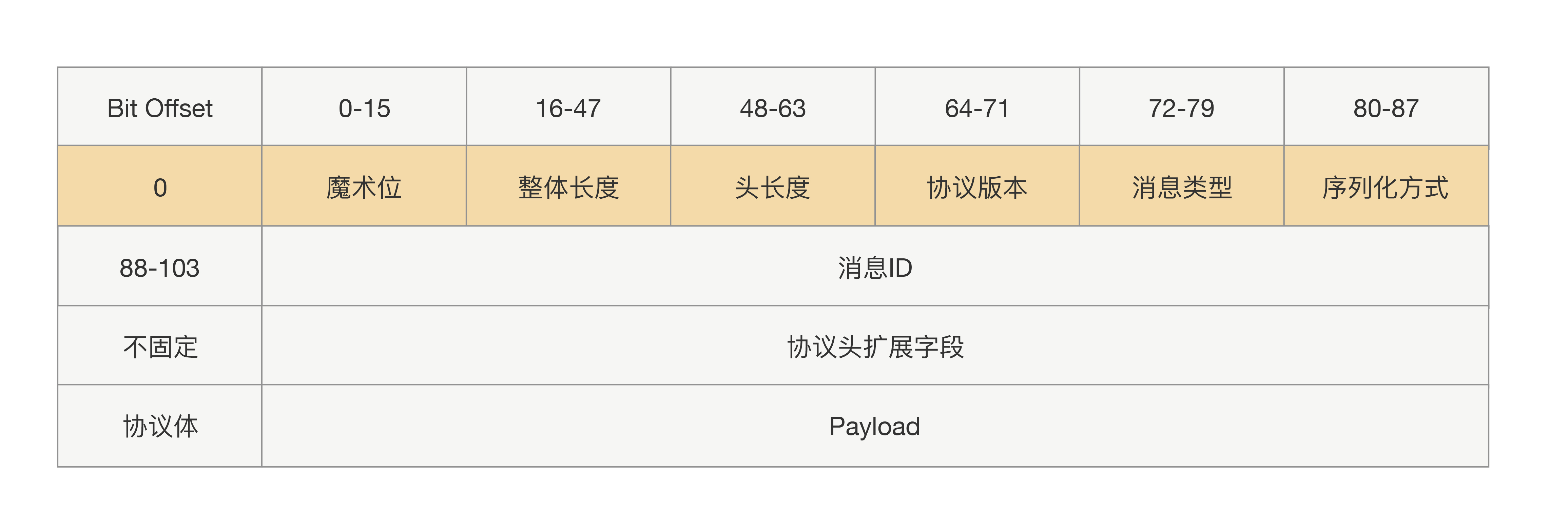
前面所述的协议属于定长协议头,那也就是说往后就不能再往协议头里加新参数了,如果加参 数就会导致线上兼容问题。
为了保证能平滑地升级改造前后的协议,我们有必要设计一种支持可扩展的协议。其关键在于让协议头支持可扩展,扩展后协议头的长度就不能定长了。那要实现读取不定长的协议头里面的内容,在这之前肯定需要一个固定的地方读取长度,所以我们需要一个固定的写入协议头的长度。整体协议就变成了三部分内容:固定部分、协议头内容、协议体内容。
有兴趣深入了解 JDK 序列化方式,可以参考:Java 序列化
由于,网络传输的数据必须是二进制数据,而调用方请求的出参、入参都是对象。因此,必须将对象转换可传输的二进制,并且要求转换算法是可逆的。
- 序列化(serialize):序列化是将对象转换为二进制数据。
- 反序列化(deserialize):反序列化是将二进制数据转换为对象。

序列化就是将对象转换成二进制数据的过程,而反序列就是反过来将二进制转换为对象的过程。
Java 领域,常见的序列化技术如下
市面上有如此多的序列化技术,那么我们在应用时如何选择呢?
序列化技术选型,需要考量的维度,根据重要性从高到低,依次有:
- 安全性:是否存在漏洞。如果存在漏洞,就有被攻击的可能性。
- 兼容性:版本升级后的兼容性是否很好,是否支持更多的对象类型,是否是跨平台、跨语言的。服务调用的稳定性与可靠性,要比服务的性能更加重要。
- 性能
- 时间开销:序列化、反序列化的耗时性能自然越小越好。
- 空间开销:序列化后的数据越小越好,这样网络传输效率就高。
- 易用性:类库是否轻量化,API 是否简单易懂。
鉴于以上的考量,序列化技术的选型建议如下:
- JDK 序列化:性能较差,且有很多使用限制,不建议使用。
- Thrift、Protobuf:适用于对性能敏感,对开发体验要求不高。
- Hessian:适用于对开发体验敏感,性能有要求。
- Jackson、Gson、Fastjson:适用于对序列化后的数据要求有良好的可读性(转为 json 、xml 形式)。
由于 RPC 每次通信,都要经过序列化、反序列化的过程,所以序列化方式,会直接影响 RPC 通信的性能。除了选择合适的序列化技术,如何合理使用序列化也非常重要。
RPC 序列化常见的使用不当的情况如下:
-
对象过于复杂、庞大 - 对象过于复杂、庞大,会降低序列化、反序列化的效率,并增加传输开销,从而导致响应时延增大。
- 过于复杂:存在多层的嵌套,比如 A 对象关联 B 对象,B 对象又聚合 C 对象,C 对象又关联聚合很多其他对象
- 过于庞大:比如一个大 List 或者大 Map
-
对象有复杂的继承关系 - 对象关系越复杂,就越浪费性能,同时又很容易出现序列化上的问题。大多数序列化框架在进行序列化时,如果发现类有继承关系,会不停地寻找父类,遍历属性。
-
使用序列化框架不支持的类作为入参类 - 比如 Hessian 框架,他天然是不支持 LinkHashMap、LinkedHashSet 等,而且大多数情况下最好不要使用第三方集合类,如 Guava 中的集合类,很多开源的序列化框架都是优先支持编程语言原生的对象。因此如果入参是集合类,应尽量选用原生的、最为常用的集合类,如 HashMap、ArrayList。
前面已经列举了常见的序列化问题,既然明确了问题,就要针对性预防。RPC 序列化时要注意以下几点:
- 对象要尽量简单,没有太多的依赖关系,属性不要太多,尽量高内聚;
- 入参对象与返回值对象体积不要太大,更不要传太大的集合;
- 尽量使用简单的、常用的、开发语言原生的对象,尤其是集合类;
- 对象不要有复杂的继承关系,最好不要有父子类的情况。
一次 RPC 调用,本质就是服务消费者与服务提供者间的一次网络信息交换的过程。可见,通信时 RPC 实现的核心。
常见的网络 IO 模型有:同步阻塞(BIO)、同步非阻塞(NIO)、异步非阻塞(AIO)。
IO 多路复用(Reactor 模式)在高并发场景下使用最为广泛,很多知名软件都应用了这一技术,如:Netty、Redis、Nginx 等。
IO 多路复用分为 select,poll 和 epoll。
什么是 IO 多路复用?字面上的理解,多路就是指多个通道,也就是多个网络连接的 IO,而复用就是指多个通道复用在一个复用器上。
系统内核处理 IO 操作分为两个阶段——等待数据和拷贝数据。等待数据,就是系统内核在等待网卡接收到数据后,把数据写到内核中;而拷贝数据,就是系统内核在获取到数据后,将数据拷贝到用户进程的空间中。
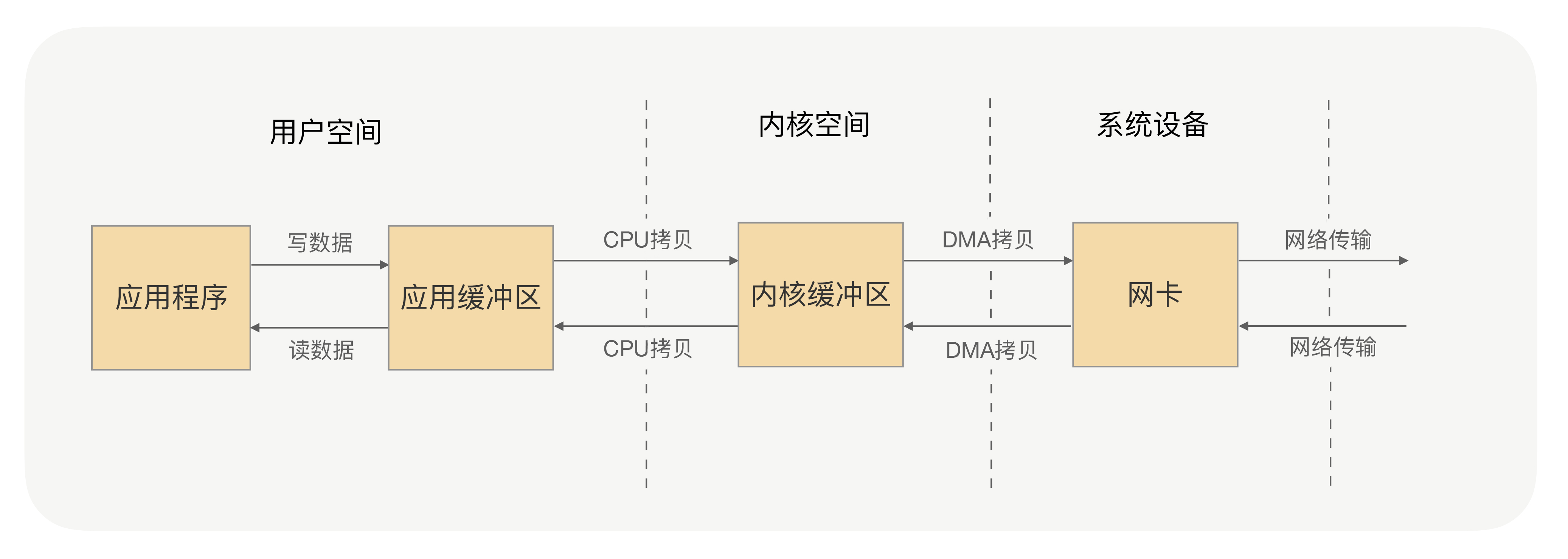
应用进程的每一次写操作,都会把数据写到用户空间的缓冲区中,再由 CPU 将数据拷贝到系统内核的缓冲区中,之后再由 DMA 将这份数据拷贝到网卡中,最后由网卡发送出去。这里我们可以看到,一次写操作数据要拷贝两次才能通过网卡发送出去,而用户进程的读操作则是将整个流程反过来,数据同样会拷贝两次才能让应用程序读取到数据。
应用进程的一次完整的读写操作,都需要在用户空间与内核空间中来回拷贝,并且每一次拷贝,都需要 CPU 进行一次上下文切换(由用户进程切换到系统内核,或由系统内核切换到用户进程),这样很浪费 CPU 和性能。
所谓的零拷贝,就是取消用户空间与内核空间之间的数据拷贝操作,应用进程每一次的读写操作,可以通过一种方式,直接将数据写入内核或从内核中读取数据,再通过 DMA 将内核中的数据拷贝到网卡,或将网卡中的数据 copy 到内核。
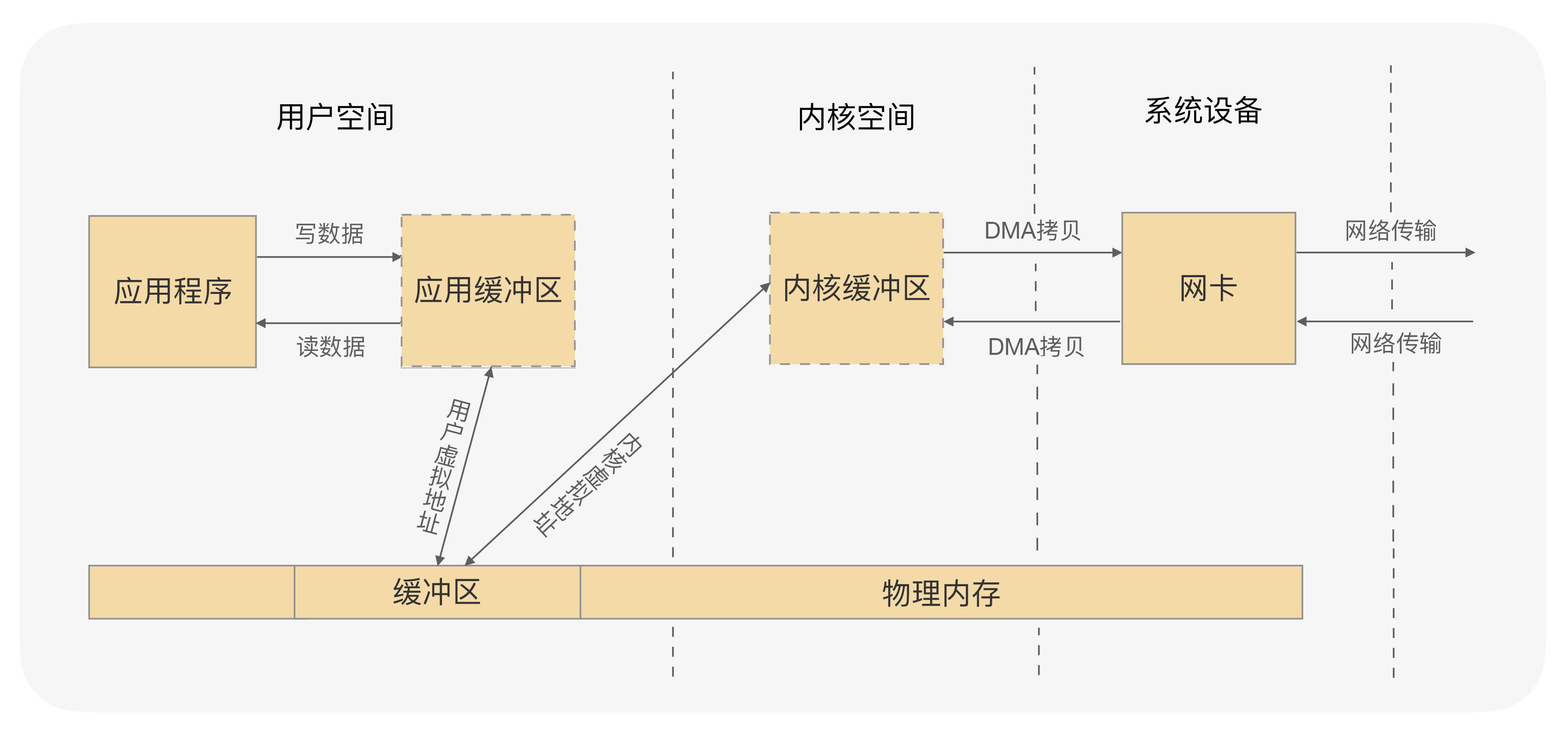
Netty 的零拷贝偏向于用户空间中对数据操作的优化,这对处理 TCP 传输中的拆包粘包问题有着重要的意义,对应用程序处理请求数据与返回数据也有重要的意义。
Netty 框架中很多内部的 ChannelHandler 实现类,都是通过 CompositeByteBuf、slice、wrap 操作来处理 TCP 传输中的拆包与粘包问题的。
Netty 的 ByteBuffer 可以采用 Direct Buffers,使用堆外直接内存进行 Socketd 的读写 操作,最终的效果与我刚才讲解的虚拟内存所实现的效果是一样的。
Netty 还提供 FileRegion 中包装 NIO 的 FileChannel.transferTo() 方法实现了零拷 贝,这与 Linux 中的 sendfile 方式在原理上也是一样的。
RPC 的远程过程调用是通过反射+动态代理实现的。
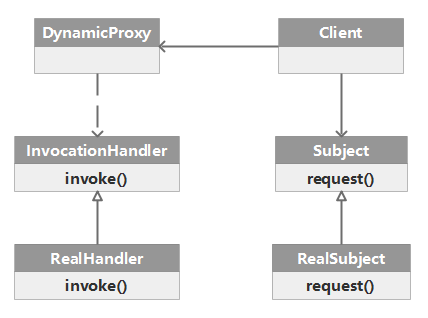
RPC 框架会自动为要调用的接口生成一个代理类。当在项目中注入接口的时候,运行过程中实际绑定的就是这个接口生成的代理类。在接口方法被调用时,会被代理类拦截,这样,就可以在生成的代理类中,加入远程调用逻辑。
除了 JDK 默认的 InvocationHandler 能完成代理功能,还有很多其他的第三方框架也可以,比如像 Javassist、Byte Buddy 这样的框架。
反射+动态代理更多详情可以参考:深入理解 Java 反射和动态代理