Releases: bentoml/BentoML
BentoML - v1.0.18
🍱 BentoML v1.0.18 brings a new way of creating the server and client natively from Python.
-
Start an HTTP or gRPC server and client asynchronously with a context manager.
server = HTTPServer("iris_classifier:latest", production=True, port=3000) # Start the server in a separate process and connect to it using a client with server.start() as client: res = client.classify(np.array([[4.9, 3.0, 1.4, 0.2]]))
-
Start an HTTP or gRPC server synchronously.
server = HTTPServer("iris_classifier:latest", production=True, port=3000) server.start(blocking=True)
-
As always, a client can be created and connected to an running server.
client = Client.from_url("http://localhost:3000") res = client.classify(np.array([[4.9, 3.0, 1.4, 0.2]]))
What's Changed
- chore(deps): bump coverage[toml] from 7.2.2 to 7.2.3 by @dependabot in #3746
- bugs: Fix an f-string bug in Tranformers framework. by @ssheng in #3753
- chore(deps): bump pytest from 7.2.2 to 7.3.0 by @dependabot in #3751
- chore(deps): bump bufbuild/buf-setup-action from 1.16.0 to 1.17.0 by @dependabot in #3750
- fix: BufferError when pushing model to BentoCloud by @aarnphm in #3737
- chore: remove codecov dependencies by @aarnphm in #3754
- feat: implement new serve API by @sauyon in #3696
- examples: Add a client example to quickstart by @ssheng in #3752
Full Changelog: v1.0.17...v1.0.18
Contributors
Assets 4
BentoML - v1.0.17
🍱 We are excited to announce the release of BentoML v1.0.17, which includes support for 🤗 Hugging Face Transformers pre-trained instances. Prior to this release, only pipelines could be saved and loaded using the bentoml.transformers APIs. However, based on the community's demand to work with pre-trained models, tokenizers, preprocessors, etc., without pipelines, we have expanded our capabilities in bentoml.transformers APIs. With this release, all pre-trained instances can be saved and loaded into either built-in Transformers framework runners or custom runners. This update opens up new possibilities for users to work with pre-trained models, and we are thrilled to see what the community will create using this feature. To learn more, visit BentoML Transformers framework documentation.
-
Pre-trained models and instances, such as tokenizers, preprocessors, and feature extractors, can also be saved as standalone models using the
bentoml.transformers.save_modelAPI.import bentoml from transformers import AutoTokenizer processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts") model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts") vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan") bentoml.transformers.save_model("speecht5_tts_processor", processor) bentoml.transformers.save_model("speecht5_tts_model", model, signatures={"generate_speech": {"batchable": False}}) bentoml.transformers.save_model("speecht5_tts_vocoder", vocoder)
-
Pre-trained models and instances can be run either independently as Transformers framework runners or jointly in a custom runner. To use pre-trained models and instances as individual framework runners, simply get the models reference and convert them to runners using the
to_runnermethod.import bentoml import torch from bentoml.io import Text, NumpyNdarray from datasets import load_dataset proccessor_runner = bentoml.transformers.get("speecht5_tts_processor").to_runner() model_runner = bentoml.transformers.get("speecht5_tts_model").to_runner() vocoder_runner = bentoml.transformers.get("speecht5_tts_vocoder").to_runner() embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation") speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0) svc = bentoml.Service("text2speech", runners=[proccessor_runner, model_runner, vocoder_runner]) @svc.api(input=Text(), output=NumpyNdarray()) def generate_speech(inp: str): inputs = proccessor_runner.run(text=inp, return_tensors="pt") speech = model_runner.generate_speech.run(input_ids=inputs["input_ids"], speaker_embeddings=speaker_embeddings, vocoder=vocoder_runner.run) return speech.numpy()
-
To use the pre-trained models and instances together in a custom runner, use the
bentoml.transformers.getAPI to get the models references and load them in a custom runner. The pretrained instances can then be used for inference in the custom runner.import bentoml import torch from datasets import load_dataset processor_ref = bentoml.models.get("speecht5_tts_processor:latest") model_ref = bentoml.models.get("speecht5_tts_model:latest") vocoder_ref = bentoml.models.get("speecht5_tts_vocoder:latest") class SpeechT5Runnable(bentoml.Runnable): def __init__(self): self.processor = bentoml.transformers.load_model(processor_ref) self.model = bentoml.transformers.load_model(model_ref) self.vocoder = bentoml.transformers.load_model(vocoder_ref) self.embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation") self.speaker_embeddings = torch.tensor(self.embeddings_dataset[7306]["xvector"]).unsqueeze(0) @bentoml.Runnable.method(batchable=False) def generate_speech(self, inp: str): inputs = self.processor(text=inp, return_tensors="pt") speech = self.model.generate_speech(inputs["input_ids"], self.speaker_embeddings, vocoder=self.vocoder) return speech.numpy() text2speech_runner = bentoml.Runner(SpeechT5Runnable, name="speecht5_runner", models=[processor_ref, model_ref, vocoder_ref]) svc = bentoml.Service("talk_gpt", runners=[text2speech_runner]) @svc.api(input=bentoml.io.Text(), output=bentoml.io.NumpyNdarray()) async def generate_speech(inp: str): return await text2speech_runner.generate_speech.async_run(inp)
What's Changed
- feat(containerize): caching pip/conda installation layers by @smidm in #3673
- docs(batching): update docs to 503 by @sauyon in #3677
- chore(deps): bump ruff from 0.0.255 to 0.0.256 by @dependabot in #3676
- fix(type): annotate PdSeries with pandas-stubs by @aarnphm in #3466
- chore(dispatcher): refactor out training code by @sauyon in #3663
- fix: makes containerize for triton examples to all amd64 by @aarnphm in #3678
- chore(deps): bump coverage[toml] from 7.2.1 to 7.2.2 by @dependabot in #3679
- revert: "chore(dispatcher): refactor out training code (#3663)" by @sauyon in #3680
- doc: add more links to Bentoml/examples by @larme in #3631
- perf: serialization optimization by @larme in #3606
- examples: Kubeflow by @ssheng in #3656
- chore(deps): bump pytest-asyncio from 0.20.3 to 0.21.0 by @dependabot in #3688
- chore(deps): bump ruff from 0.0.256 to 0.0.257 by @dependabot in #3689
- chore(deps): bump imageio from 2.26.0 to 2.26.1 by @dependabot in #3690
- chore(deps): bump yamllint from 1.29.0 to 1.30.0 by @dependabot in #3694
- fix: remove duplicate dependabot check for pip by @aarnphm in #3691
- chore(deps): bump ruff from 0.0.257 to 0.0.258 by @dependabot in #3699
- docs: Update the Kubeflow example by @ssheng in #3703
- chore(deps): bump ruff from 0.0.258 to 0.0.259 by @dependabot in #3709
- docs: add link to pyfilesystem plugins by @sauyon in #3716
- docs: Kubeflow integration documentation by @ssheng in #3704
- docs: replace load_runner() to get().to_runner() by @KimSoungRyoul in #3715
- chore(deps): bump imageio from 2.26.1 to 2.27.0 by @dependabot in #3720
- fix(readme): format markdown table by @aarnphm in #3722
- fix: copy files before running
setup_scriptby @aarnphm in #3713 - chore: remove experimental warning for
bentoml.metricsby @aarnphm in #3725 - ci: temporary disable coverage by @aarnphm in #3726
- chore(deps): bump ruff from 0.0.259 to 0.0.260 by @dependabot in #3734
- chore(deps): bump tritonclient[all] from 2.31.0 to 2.32.0 by @dependabot in #3730
- fix(type):
bentoml.container.buildshould accept multipleimage_tagby @pmayd in #3719 - chore(deps): bump bufbuild/buf-setup-action from 1.15.1 to 1.16.0 by @dependabot in #3738
- feat: add query params to request context by @sauyon in #3717
- chore(dispatcher): use attr class instead of a tuple by @sauyon in #3731
- fix: Make it so the configured max_batch_size is respected when batching inference requests together by @RShang97 in #3741
- feat(transformers): pretrained protocol support by @aarnphm in #3684
- fix(tests): broken CI by @aarnphm in #3742
- chore(deps): bump ruff from 0.0.260 to 0.0.261 by @dependabot in #3744
- docs: Transformers documentation on pre-trained instances support by @ssheng in #3745
New Contributors
- @smidm made their first contribution in #3673
- @pmayd made their first contribution in #3719
- @RShang97 made their first contribution in #3741
Full Changelog: v1.0.16...v1.0.17
Contributors
Assets 4
BentoML - v1.0.16
🍱 BentoML v1.0.16 release is here featuring the introduction of the bentoml.triton framework. With this integration, BentoML now supports running NVIDIA Triton Inference Server as a Runner. See Triton Inference Server documentation to learn more!
-
Triton Inference Server can be configured as a Runner in BentoML with its model repository and CLI arguments specified as parameters.
import bentoml triton_runner = bentoml.triton.Runner( "triton_runner", model_repository="s3://bucket/path/to/model_repository", cli_args=["--load-model=torchscrip_yolov5s", "--model-control-mode=explicit"], )
-
Models served by the Triton Inference Server Runner can be called as a method on the runner handle both synchronously and asynchronously.
@svc.api( input=bentoml.io.Image.from_sample("./data/0.png"), output=bentoml.io.NumpyNdarray() ) async def bentoml_torchscript_mnist_infer(im: Image) -> NDArray[t.Any]: arr = np.array(im) / 255.0 arr = np.expand_dims(arr, (0, 1)).astype("float32") InferResult = await triton_runner.torchscript_mnist.async_run(arr) return InferResult.as_numpy("OUTPUT__0")
-
Build bentos and containerize images with Triton Runners by specifying
nvcr.io/nvidia/tritonserverbase image inbentofile.yaml.service: service:svc include: - /model_repository - /data/*.png - /*.py exclude: - /__pycache__ - /venv - /train.py - /build_bento.py - /containerize_bento.py python: packages: - bentoml[triton] docker: base_image: nvcr.io/nvidia/tritonserver:22.12-py3
💡 If you are an existing Triton user, the integration provides simpler ways to add custom logics in Python, deploy distributed multi-model inference graph, unify model management across different ML frameworks and workflows, and standardize model packaging format with versioning and collaboration features. If you are an existing BentoML user, the integration improves the runner efficiency and throughput under high load thanks to Triton’s efficient C++ runtime.
What's Changed
- fix(container): podman virtual machine healthcheck (#3575) by @timc in #3576
- chore(aiohttp): remove deprecated verify_ssl to ssl by @aarnphm in #3574
- feat(triton): support HTTP client by @aarnphm in #3502
- fix(grpc): handle backward protocol version by @aarnphm in #3332
- chore(deps): bump ruff from 0.0.246 to 0.0.247 by @dependabot in #3579
- chore(test): using container API for testing by @aarnphm in #3582
- fix(serve-cli): Make sure to use BENTOML_CONFIG value by @aarnphm in #3597
- docs: Update documentation with an examples link by @ssheng in #3599
- chore: lock starlette version by @sauyon in #3600
- feature(diffusers): support
enable_attention_slicingby @larme in #3598 - chore(cli): figlet to show on CLI only by @aarnphm in #3603
- chore(cli): using default background as color by @aarnphm in #3608
- feat: Flax by @aarnphm in #3123
- feat(gRPC): client implementation by @aarnphm in #3280
- fix: invalid option dtype=True for pd.read_csv by @parano in #3601
- chore(deps): bump coverage[toml] from 7.1.0 to 7.2.0 by @dependabot in #3616
- chore(deps): bump ruff from 0.0.247 to 0.0.252 by @dependabot in #3617
- docs: containerisation API by @aarnphm in #3518
- chore(deps): bump coverage[toml] from 7.2.0 to 7.2.1 by @dependabot in #3621
- chore(deps): bump imageio from 2.25.1 to 2.26.0 by @dependabot in #3620
- fix(docs): missing space bug causes table not to render by @aarnphm in #3622
- chore(deps): bump ruff from 0.0.252 to 0.0.253 by @dependabot in #3624
- feat: enable cork for non-batched workloads by @sauyon in #3602
- docs: Fix typo in concepts/service by @FelixSchuSi in #3627
- chore(deps): bump tritonclient[all] from 2.30.0 to 2.31.0 by @dependabot in #3628
- fix(docs): broken inline docstring by @aarnphm in #3538
- fix: use a semaphore to limit runner connections by @sauyon in #3607
- fix: make inference_api handle None type by @aarnphm in #3611
- fix: make sure not to override user set values for from_sample by @aarnphm in #3610
- docs: add exceptions API section by @aarnphm in #3609
- revert(pyproject): add back pytest plugins by @aarnphm in #3633
- fix(configuration): CORS docs,
allow_originsandallow_headersby @larme in #3643 - chore(deps): bump ruff from 0.0.253 to 0.0.254 by @dependabot in #3641
- chore(deps): bump pytest from 7.2.1 to 7.2.2 by @dependabot in #3642
- chore: http client healthcheck by @denyszhak in #3636
- docs: typo in configuration.rst by @davkime in #3644
- docs: correct links to configuration source code by @davkime in #3645
- example: add fraud detection and benchmark examples by @parano in #3647
- fix(containerize): remove autoconfig for buildctl by @aarnphm in #3484
- feat: name in bentofile.yaml by @aarnphm in #3604
- chore: ensure all labels are dict[str,str] by @aarnphm in #3605
- fix(triton): enable runtime options by @aarnphm in #3649
- docs: Triton Inference Server by @aarnphm in #3519
- example: Triton Inference Server by @aarnphm in #3471
- chore(deps): bump pytest from 7.2.1 to 7.2.2 in /requirements by @dependabot in #3639
- chore(deps): bump bufbuild/buf-setup-action from 1.14.0 to 1.15.0 by @dependabot in #3638
- fix: some missing logics for triton examples by @aarnphm in #3650
- fix: use async implementation by @characat0 in #3654
- feat: add ray deploy support by @parano in #3632
- chore(deps): bump pytest-xdist[psutil] from 3.2.0 to 3.2.1 by @dependabot in #3659
- chore(deps): bump bufbuild/buf-setup-action from 1.15.0 to 1.15.1 by @dependabot in #3655
- fix: update scheme logic using ssl.enabled by @aarnphm in #3660
- feat:
from_sampledocstring by @aarnphm in #3318 - fix(ci): locking starlette for container tests by @aarnphm in #3666
- chore: better exception for numpy by @sauyon in #3665
- feat: make file io descriptor allow any mime type by default by @sauyon in #3626
- fix(docs): broken link by @aarnphm in #3537
- chore(stubs): remove unused by @aarnphm in #3612
- docs: Update Triton documentation and examples by @ssheng in #3668
- chore(deps): bump ruff from 0.0.254 to 0.0.255 by @dependabot in #3671
- docs: Update integration docs by @ssheng in #3672
New Contributors
- @FelixSchuSi made their first contribution in #3627
- @denyszhak made their first contribution in #3636
- @davkime made their first contribution in #3644
Full Changelog: v1.0.15...v1.0.16
Contributors
Assets 4
BentoML - v1.0.15
🍱 BentoML v1.0.15 release is here featuring the introduction of the bentoml.diffusers framework.
-
Learn more about the capabilities of the
bentoml.diffusersframework in the Creating Stable Diffusion 2.0 Service With BentoML And Diffusers blog and BentoML Diffusers example project. -
Import a diffusion model with the
bentoml.diffusers.import_modelAPI.import bentoml bentoml.diffusers.import_model( "sd2", "stabilityai/stable-diffusion-2", )
-
Create a
text2imgservice using a Stable Diffusion 2.0 model runner with the familiarto_runnerAPI from thebentoml.diffuserframework.import torch from diffusers import StableDiffusionPipeline import bentoml from bentoml.io import Image, JSON, Multipart bento_model = bentoml.diffusers.get("sd2:latest") stable_diffusion_runner = bento_model.to_runner() svc = bentoml.Service("stable_diffusion_v2", runners=[stable_diffusion_runner]) @svc.api(input=JSON(), output=Image()) def txt2img(input_data): images, _ = stable_diffusion_runner.run(**input_data) return images[0]
🍱 Fixed a incompatibility change introduced in starlette==0.25.0 result in the type MultiPartMessage not being found in starlette.formparsers.
ImportError: cannot import name 'MultiPartMessage' from 'starlette.formparsers' (/opt/miniconda3/envs/bentoml/lib/python3.10/site-packages/starlette/formparsers.py)
What's Changed
- chore(deps): bump pytest-xdist[psutil] from 3.1.0 to 3.2.0 by @dependabot in #3536
- fix: include dockerfile_template to Bento for containerize by @aarnphm in #3501
- chore: add missing logger and fix types by @aarnphm in #3453
- chore(rtd): disable epub and pdf as format by @aarnphm in #3544
- feat(torchscript): support
_extra_filesby @aarnphm in #3480 - refactor(ci): make sure to run types on py,pyi files by @aarnphm in #3545
- fix(server): deprecate client and cache get_client by @aarnphm in #3547
- chore(serve): update options for triton_options by @aarnphm in #3503
- tools(linter): Ruff by @aarnphm in #3539
- chore(deps): bump ruff from 0.0.243 to 0.0.244 by @dependabot in #3548
- chore(type): remove cattr type ignore by @aarnphm in #3550
- chore: bumping otlp deps to 1.15 by @aarnphm in #3351
- docs: Add an example index by @ssheng in #3551
- revert: "chore: bumping otlp deps to 1.15" by @bojiang in #3553
- chore(deps): bump bufbuild/buf-setup-action from 1.13.1 to 1.14.0 by @dependabot in #3554
- chore(deps): bump ruff from 0.0.244 to 0.0.246 by @dependabot in #3559
- chore(deps): bump imageio from 2.25.0 to 2.25.1 by @dependabot in #3557
- chore: update README.md by @timliubentoml in #3565
- feat(containerization): support 11.7 by @aarnphm in #3567
- chore: remove deprecation warning when building bentos by @CheeksTheGeek in #3566
- feature(framework): diffusers by @larme in #3534
- fix: update formparser for new starlette by @sauyon in #3569
New Contributors
- @CheeksTheGeek made their first contribution in #3566
Full Changelog: v1.0.14...v1.0.15
Contributors
Assets 4
BentoML - v1.0.14
🍱 Fixed the backward incompatibility introduced in starlette version 0.24.0. Upgrade BentoML to v1.0.14 if you encounter the error related to content_type like below.
Traceback (most recent call last):
File "/usr/local/lib/python3.8/dist-packages/bentoml/_internal/server/service_app.py", line 305, in api_func
input_data = await api.input.from_http_request(request)
File "/usr/local/lib/python3.8/dist-packages/bentoml/_internal/io_descriptors/multipart.py", line 208, in from_http_request
reqs = await populate_multipart_requests(request)
File "/usr/local/lib/python3.8/dist-packages/bentoml/_internal/utils/formparser.py", line 188, in populate_multipart_requests
form = await multipart_parser.parse()
File "/usr/local/lib/python3.8/dist-packages/bentoml/_internal/utils/formparser.py", line 158, in parse
multipart_file = UploadFile(
TypeError: __init__() got an unexpected keyword argument 'content_type'
BentoML - v1.0.13
🍱 BentoML v1.0.13 is released featuring a preview of batch inference with Spark.
-
Run the batch inference job using the
bentoml.batch.run_in_spark()method. This method takes the API name, the Spark DataFrame containing the input data, and the Spark session itself as parameters, and it returns a DataFrame containing the results of the batch inference job.import bentoml # Import the bento from a repository or get the bento from the bento store bento = bentoml.import_bento("s3://bentoml/quickstart") # Run the run_in_spark function with the bento, API name, and Spark session results_df = bentoml.batch.run_in_spark(bento, "classify", df, spark)
-
Internally, what happens when you run
run_in_sparkis as follows:- First, the bento is distributed to the cluster. Note that if the bento has already been distributed, i.e. you have already run a computation with that bento, this step is skipped.
- Next, a process function is created, which starts a BentoML server on each of the Spark workers, then uses a client to process all the data. This is done so that the workers take advantage of the batch processing features of the BentoML server. PySpark pickles this process function and dispatches it, along with the relevant data, to the workers.
- Finally, the function is evaluated on the given dataframe. Once all methods that the user defined in the script have been executed, the data is returned to the master node.
bentoml.batch API may undergo incompatible changes until general availability announced in a later minor version release.
🥂 Shout out to jeffthebear, KimSoungRyoul, Robert Fernandez, Marco Vela, Quan Nguyen, and y1450 from the community for their contributions in this release.
What's Changed
- docs: add inline notes and better exception by @bojiang in #3296
- chore(deps): bump pytest-asyncio from 0.20.2 to 0.20.3 by @dependabot in #3334
- feat: bentoserver client by @qu8n in #3321
- fix(transformers): check for task aliases by @jeffthebear in #3337
- chore(framework): add partial_kwargs to picklable and pytorch runners by @bojiang in #3338
- feat: protobuf shim by @aarnphm in #3333
- fix: CI breakage by @aarnphm in #3350
- chore(deps): bump black[jupyter] from 22.10.0 to 22.12.0 by @dependabot in #3354
- chore(deps): bump isort from 5.10.1 to 5.11.1 by @dependabot in #3355
- feat(http server): pass-through openapi of mounted apps by @bojiang in #3358
- fix(pytorch): runnable method collision by @bojiang in #3357
- fix(torchscript): runnable method collision by @bojiang in #3364
- chore(deps): bump isort from 5.11.1 to 5.11.2 by @dependabot in #3361
- chore(deps): bump isort from 5.11.2 to 5.11.3 in /requirements by @dependabot in #3374
- chore(deps): bump bufbuild/buf-setup-action from 1.9.0 to 1.10.0 by @dependabot in #3370
- chore(deps): bump coverage[toml] from 6.5.0 to 7.0.0 in /requirements by @dependabot in #3373
- chore(deps): bump pylint from 2.15.8 to 2.15.9 in /requirements by @dependabot in #3372
- chore(deps): bump imageio from 2.22.4 to 2.23.0 in /requirements by @dependabot in #3371
- fix: make sure to handle relative path for templates by @aarnphm in #3375
- fix(containerize): fs path format on windows by @bojiang in #3378
- chore(deps): bump isort from 5.11.3 to 5.11.4 by @dependabot in #3380
- docs: tracing and configuration by @aarnphm in #3067
- fix: use relative urls in swagger UI by @sauyon in #3381
- chore(deps): bump bufbuild/buf-setup-action from 1.10.0 to 1.11.0 by @dependabot in #3382
- chore(deps): bump coverage[toml] from 7.0.0 to 7.0.1 by @dependabot in #3383
- chore(config): ignore blank lines in bentoml config options by @bojiang in #3385
- chore(deps): bump coverage[toml] from 7.0.1 to 7.0.2 by @dependabot in #3386
- fix: log error when runnable instantiation fails by @sauyon in #3388
- chore(deps): bump coverage[toml] from 7.0.2 to 7.0.3 by @dependabot in #3390
- fix: don't use logger for CLI output by @sauyon in #3395
- fix: allow passing server URLs with paths by @sauyon in #3394
- fix(sdk): handling container platform from CLI separately by @aarnphm in #3366
- fix: wrong self annotations by @aarnphm in #3397
- chore(deps): bump imageio from 2.23.0 to 2.24.0 by @dependabot in #3410
- chore(deps): bump coverage[toml] from 7.0.3 to 7.0.4 by @dependabot in #3409
- chore(deps): bump pylint from 2.15.9 to 2.15.10 by @dependabot in #3407
- fix: serve missing logic from #3321 by @aarnphm in #3336
- chore(deps): bump coverage[toml] from 7.0.4 to 7.0.5 by @dependabot in #3413
- chore(deps): bump yamllint from 1.28.0 to 1.29.0 by @dependabot in #3414
- fix: regression f-string by @aarnphm in #3416
- fix(runner): log correct error types during model validation by @characat0 in #3421
- fix(client): make sure tags is available in specs by @KimSoungRyoul in #3359
- fix: handling KeyError when accessing IODescriptor spec by @aarnphm in #3398
- chore(deps): bump build[virtualenv] from 0.9.0 to 0.10.0 by @dependabot in #3419
- feat: support bentos and tags in bentoml.bentos.serve by @sauyon in #3424
- feat: add endpoints list to client by @sauyon in #3423
- fix: #3399 during
containerizeby @aarnphm in #3400 - feat: add context manager support for
bentoml.clientby @y1450 in #3402 - chore: migrate to newer API in docstring by @KimSoungRyoul in #3429
- chore(deps): bump bufbuild/buf-setup-action from 1.11.0 to 1.12.0 by @dependabot in #3430
- chore(deps): bump pytest from 7.2.0 to 7.2.1 by @dependabot in #3433
- feat: openapi_components method for Multipart by @RobbieFernandez in #3438
- ci: disable 3.10 e2e for gRPC on Mac X86 by @aarnphm in #3441
- chore(exportable): update exception message and errors imports by @aarnphm in #3435
- feat: make
load_bentotake Tag and Bento by @sauyon in #3444 - chore: add setuptools-scm as dev deps by @aarnphm in #3443
- fix: load_bento Tag import by @sauyon in #3445
- feat: support batch inference with Spark by @sauyon in #3425
- chore: add pandas-stubs as dev-dependencies by @aarnphm in #3442
- fix: raise more specific error in
from_specby @sauyon in #3447 - fix(cli): overriding memoized options via
--optby @aarnphm in #3401 - fix(exception): wrong variable reference by @aarnphm in #3450
- fix: make sure to run migration for envvar by @aarnphm in #3339
- feat: YataiClient context to communicate with multiple Yatai instances by @ssheng in #3448
New Contributors
- @characat0 made their first contribution in #3421
- @y1450 made their first contribution in #3402
- @RobbieFernandez made their first contribution in #3438
Full Changelog: v1.0.12...v1.0.13
Contributors
Assets 4
BentoML - v1.0.12
Important bug fixes.
- Fixed runner call failures with keyword arguments.
- Fixed incorrect user base image override .
What's Changed
- fix(runner): content-type error by @aarnphm in #3302
- feat: grpc servicer implementation per version by @aarnphm in #3316
- feat(grpc): adding service metadata by @aarnphm in #3278
- docs: Update monitoring docs format by @ssheng in #3324
- fix(runner): remote run_method with kwargs by @larme in #3326
- fix: don't overwrite user base image by @aarnphm in #3329
- fix: add upper bound for packaging version by @aarnphm in #3331
- fix(container): podman health result string parsing by @aarnphm in #3330
- fix: io descriptor backward compatibility by @sauyon in #3327
Full Changelog: v1.0.11...v1.0.12
Contributors
Assets 4
BentoML - v1.0.11
🍱 BentoML v1.0.11 is here featuring the introduction of an inference collection and model monitoring API that can be easily integrated with any model monitoring frameworks.
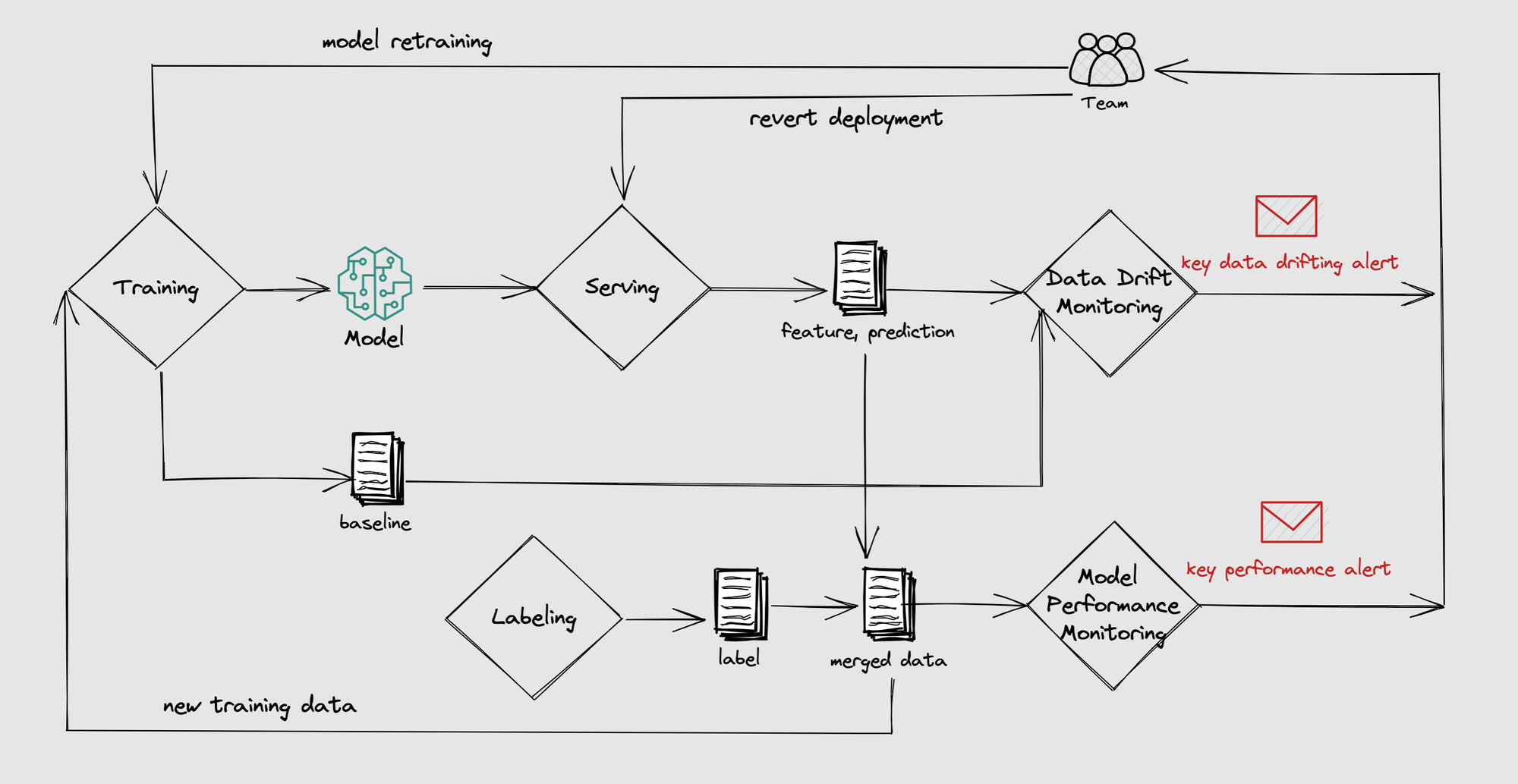
-
Introduced the
bentoml.monitorAPI for monitoring any features, predictions, and target data in numerical, categorical, and numerical sequence types.import bentoml from bentoml.io import Text from bentoml.io import NumpyNdarray CLASS_NAMES = ["setosa", "versicolor", "virginica"] iris_clf_runner = bentoml.sklearn.get("iris_clf:latest").to_runner() svc = bentoml.Service("iris_classifier", runners=[iris_clf_runner]) @svc.api( input=NumpyNdarray.from_sample(np.array([4.9, 3.0, 1.4, 0.2], dtype=np.double)), output=Text(), ) async def classify(features: np.ndarray) -> str: with bentoml.monitor("iris_classifier_prediction") as mon: mon.log(features[0], name="sepal length", role="feature", data_type="numerical") mon.log(features[1], name="sepal width", role="feature", data_type="numerical") mon.log(features[2], name="petal length", role="feature", data_type="numerical") mon.log(features[3], name="petal width", role="feature", data_type="numerical") results = await iris_clf_runner.predict.async_run([features]) result = results[0] category = CLASS_NAMES[result] mon.log(category, name="pred", role="prediction", data_type="categorical") return category
-
Enabled monitoring data collection through log file forwarding using any forwarders (fluentbit, filebeat, logstash) or OTLP exporter implementations.
-
Configuration for monitoring data collection through log files.
monitoring: enabled: true type: default options: log_path: path/to/log/file
-
Configuration for monitoring data collection through an OTLP exporter.
monitoring: enable: true type: otlp options: endpoint: http://localhost:5000 insecure: true credentials: null headers: null timeout: 10 compression: null meta_sample_rate: 1.0
-
-
Supported third-party monitoring data collector integrations through BentoML Plugins. See bentoml/plugins repository for more details.
🐳 Improved containerization SDK and CLI options, read more in #3164.
-
Added support for multiple backend builder options (Docker, nerdctl, Podman, Buildah, Buildx) in addition to buildctl (standalone buildkit builder).
-
Improved Python SDK for containerization with different backend builder options.
import bentoml bentoml.container.build("iris_classifier:latest", backend="podman", features=["grpc","grpc-reflection"], **kwargs)
-
Improved CLI to include the newly added options.
bentoml containerize --help
-
Standardized the generated Dockerfile in bentos to be compatible with all build tools for use cases that require building from a Dockerfile directly.
💡 We continue to update the documentation and examples on every release to help the community unlock the full power of BentoML.
- Learn more about inference data collection and model monitoring capabilities in BentoML.
- Learn more about the default metrics that comes out-of-the-box and how to add custom metrics in BentoML.
What's Changed
- chore: add framework utils functions directory by @larme in #3203
- fix: missing f-string in tag validation error message by @csh3695 in #3205
- chore(build_config): bypass exception when cuda and conda is specified by @aarnphm in #3188
- docs: Update asynchronous API documentation by @ssheng in #3204
- style: use relative import inside _internal/ by @larme in #3209
- style: fix
monitoringtype error by @aarnphm in #3208 - chore(build): add dependabot for pyproject.toml by @aarnphm in #3139
- chore(deps): bump black[jupyter] from 22.8.0 to 22.10.0 in /requirements by @dependabot in #3217
- chore(deps): bump pylint from 2.15.3 to 2.15.5 in /requirements by @dependabot in #3212
- chore(deps): bump pytest-asyncio from 0.19.0 to 0.20.1 in /requirements by @dependabot in #3216
- chore(deps): bump imageio from 2.22.1 to 2.22.4 in /requirements by @dependabot in #3211
- fix: don't index ContextVar at runtime by @sauyon in #3221
- chore(deps): bump pyarrow from 9.0.0 to 10.0.0 in /requirements by @dependabot in #3214
- chore: configuration check for development by @aarnphm in #3223
- fix bento create by @quandollar in #3220
- fix(docs): missing
tabletag by @nyongja in #3231 - docs: grammar corrections by @tbazin in #3234
- chore(deps): bump pytest-asyncio from 0.20.1 to 0.20.2 in /requirements by @dependabot in #3238
- chore(deps): bump pytest-xdist[psutil] from 2.5.0 to 3.0.2 by @dependabot in #3245
- chore(deps): bump pytest from 7.1.3 to 7.2.0 in /requirements by @dependabot in #3237
- chore(deps): bump build[virtualenv] from 0.8.0 to 0.9.0 in /requirements by @dependabot in #3240
- deps: bumping gRPC and OTLP dependencies by @aarnphm in #3228
- feat(file): support custom mime type for file proto by @aarnphm in #3095
- fix: multipart for client by @sauyon in #3253
- fix(json): make sure to parse a list of dict for_sample by @aarnphm in #3229
- chore: move test proto to internal tests only by @aarnphm in #3255
- fix(framework): external_modules for loading pytorch by @bojiang in #3254
- feat(container): builder implementation by @aarnphm in #3164
- feat(sdk): implement otlp monitoring exporter by @bojiang in #3257
- chore(grpc): add missing init.py by @aarnphm in #3259
- docs(metrics): Update docs for the default metrics by @ssheng in #3262
- chore: generate plain dockerfile without buildkit syntax by @aarnphm in #3261
- style: remove
# type: ignoreby @aarnphm in #3265 - fix: lazy load ONNX utils by @aarnphm in #3266
- fix(pytorch): pickle is the unpickler of cloudpickle by @bojiang in #3269
- fix: instructions for missing sklearn dependency by @benjamintanweihao in #3271
- docs: ONNX signature docs by @larme in #3272
- chore(deps): bump pyarrow from 10.0.0 to 10.0.1 by @dependabot in #3273
- chore(deps): bump pylint from 2.15.5 to 2.15.6 by @dependabot in #3274
- fix(pandas): only set columns when
apply_column_namesis set by @mqk in #3275 - feat: configuration versioning by @aarnphm in #3052
- fix(container): support comma in docker env by @larme in #3285
- chore(stub):
import filetypeby @aarnphm in #3260 - fix(container): ensure to stream logs when
DOCKER_BUILDKIT=0by @aarnphm in #3294 - docs: update instructions for containerize message by @aarnphm in #3289
- fix: unset
NVIDIA_VISIBLE_DEVICESwhen cuda image is used by @aarnphm in #3298 - fix: multipart logic by @sauyon in #3297
- chore(deps): bump pylint from 2.15.6 to 2.15.7 by @dependabot in #3291
- docs: wrong arguments when saving by @KimSoungRyoul in #3306
- chore(deps): bump pylint from 2.15.7 to 2.15.8 in /requirements by @dependabot in #3308
- chore(deps): bump pytest-xdist[psutil] from 3.0.2 to 3.1.0 in /requirements by @dependabot in #3309
- chore(pyproject): bumping python version typeshed to 3.11 by @aarnphm in https://github.com/bentoml/Bento...
Contributors
Assets 4
BentoML - v1.0.10
🍱 BentoML v1.0.10 is released to address a recurring broken pipe reported by the community. Also included in this release, is a list of improvements we’d like to share with the community.
-
Fixed an
aiohttp.client_exceptions.ClientOSErrorcaused by asymmetrical keep alive timeout settings between the API Server and Runner.aiohttp.client_exceptions.ClientOSError: [Errno 32] Broken pipe
-
Added multi-output support for ONNX and TensorFlow frameworks.
-
Added
from_samplesupport to all IO Descriptors in addition to justbentoml.io.NumpyNdarrayand the sample is reflected in the Swagger UI.# Pandas Example @svc.api( input=PandasDataFrame.from_sample( pd.DataFrame([1,2,3,4]) ), output=PandasDataFrame(), ) # JSON Example @svc.api( input=JSON.from_sample( {"foo": 1, "bar": 2} ), output=JSON(), )

💡 We continue to update the documentation and examples on every release to help the community unlock the full power of BentoML.
- Check out the updated multi-model inference graph guide and example to learn how to compose multiple models in the same Bento service.
- Did you know BentoML support OpenTelemetry tracing out-of-the-box? Checkout the Tracing guide for tracing support for OTLP, Jaeger, and Zipkin.
What's Changed
- feat(cli): log conditional environment variables by @aarnphm in #3156
- fix: ensure conda not use pipefail and unset variables by @aarnphm in #3171
- fix(templates): ensure to use python3 and pip3 by @aarnphm in #3170
- fix(sdk): montioring log output by @bojiang in #3175
- feat: make quickstart batchable by @sauyon in #3172
- fix: lazy check for stubs via path when install local wheels by @aarnphm in #3180
- fix(openapi): remove summary field under Info by @aarnphm in #3178
- docs: Inference graph example by @ssheng in #3183
- docs: remove whitespaces in migration guides by @wellshs in #3185
- fix(build_config): validation when NoneType by @aarnphm in #3187
- fix(docs): indentation in migration.rst by @aarnphm in #3186
- doc(example): monitoring example for classification tasks by @bojiang in #3176
- refactor(sdk): separate default monitoring impl by @bojiang in #3189
- fix(ssl): provide default values in configuration by @aarnphm in #3191
- fix: don't ignore logging conf by @sauyon in #3192
- feat: tensorflow multi outputs support by @larme in #3115
- docs: cleanup whitespace and typo by @aarnphm in #3195
- chore: cleanup deadcode by @aarnphm in #3196
- fix(runner): set uvicorn keep-alive by @sauyon in #3198
- perf: refine onnx implementation by @larme in #3166
- feat:
from_samplefor IO descriptor by @aarnphm in #3143
New Contributors
Full Changelog: v1.0.8...v1.0.9
What's Changed
Full Changelog: v1.0.9...v1.0.10
Contributors
Assets 4
BentoML - v1.0.8
🍱 BentoML v1.0.8 is released with a list of improvement we hope that you’ll find useful.
-
Introduced Bento Client for easy access to the BentoML service over HTTP. Both sync and async calls are supported. See the Bento Client Guide for more details.
from bentoml.client import Client client = Client.from_url("http://localhost:3000") # Sync call response = client.classify(np.array([[4.9, 3.0, 1.4, 0.2]])) # Async call response = await client.async_classify(np.array([[4.9, 3.0, 1.4, 0.2]]))
-
Introduced custom metrics support for easy instrumentation of custom metrics over Prometheus. See Metrics Guide for more details.
# Histogram metric inference_duration = bentoml.metrics.Histogram( name="inference_duration", documentation="Duration of inference", labelnames=["nltk_version", "sentiment_cls"], ) # Counter metric polarity_counter = bentoml.metrics.Counter( name="polarity_total", documentation="Count total number of analysis by polarity scores", labelnames=["polarity"], )
Full Prometheus style syntax is supported for instrumenting custom metrics inside API and Runner definitions.
# Histogram inference_duration.labels( nltk_version=nltk.__version__, sentiment_cls=self.sia.__class__.__name__ ).observe(time.perf_counter() - start) # Counter polarity_counter.labels(polarity=is_positive).inc()
-
Improved health checking to also cover the status of runners to avoid returning a healthy status before runners are ready.
-
Added SSL/TLS support to gRPC serving.
bentoml serve-grpc --ssl-certfile=credentials/cert.pem --ssl-keyfile=credentials/key.pem --production --enable-reflection
-
Added channelz support for easy debugging gRPC serving.
-
Allowed nested requirements with the
-rsyntax.# requirements.txt -r nested/requirements.txt pydantic Pillow fastapi -
Improved the adaptive batching dispatcher auto-tuning ability to avoid sporadic request failures due to batching in the beginning of the runner lifecycle.
-
Fixed a bug such that runners will raise a
TypeErrorwhen overloaded. Now anHTTP 503 Service Unavailablewill be returned when runner is overloaded.File "python3.9/site-packages/bentoml/_internal/runner/runner_handle/remote.py", line 188, in async_run_method return tuple(AutoContainer.from_payload(payload) for payload in payloads) TypeError: 'Response' object is not iterable
💡 We continue to update the documentation and examples on every release to help the community unlock the full power of BentoML.
- Check out the updated PyTorch Framework Guide on how to use
external_modulesto save classes or utility functions required by the model. - See the Metrics Guide on how to add custom metrics to your API and custom Runners.
- Learn more about how to use the Bento Client to call your BentoML service with Python easily.
- Check out the latest blog post on why model serving over gRPC matters to data scientists.
🥂 We’d like to thank the community for your continued support and engagement.
- Shout out to @judahrand for multiple contributions to BentoML and bentoctl.
- Shout out to @phildamore-phdata, @quandollar, @2JooYeon, and @fortunto2 for their first contribution to BentoML.