https://leetcode-cn.com/problems/word-search-ii/
给定一个二维网格 board 和一个字典中的单词列表 words,找出所有同时在二维网格和字典中出现的单词。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。
示例:
输入:
words = ["oath","pea","eat","rain"] and board =
[
['o','a','a','n'],
['e','t','a','e'],
['i','h','k','r'],
['i','f','l','v']
]
输出: ["eat","oath"]
说明:
你可以假设所有输入都由小写字母 a-z 组成。
提示:
你需要优化回溯算法以通过更大数据量的测试。你能否早点停止回溯?
如果当前单词不存在于所有单词的前缀中,则可以立即停止回溯。什么样的数据结构可以有效地执行这样的操作?散列表是否可行?为什么? 前缀树如何?如果你想学习如何实现一个基本的前缀树,请先查看这个问题: 实现Trie(前缀树)。
- 百度
- 字节
我们需要对矩阵中每一项都进行深度优先遍历(DFS)。 递归的终点是
- 超出边界
- 递归路径上组成的单词不在 words 的前缀。
比如题目示例:words = ["oath","pea","eat","rain"],那么对于 oa,oat 满足条件,因为他们都是 oath 的前缀。因此对于 a,oat 来说,它们有希望能找到 oath,但是 oaa 就不满足条件。这是一个关键点,我们的算法就是基于这个前提进行剪枝的,如果不剪枝则无法通过所有的测试用例。
这是一个典型的二维表格 DFS,和小岛专题套路一样:
- 四个方向 DFS。
- 为了防止环的出现,我们需要记录访问过的节点。
- 必须的时候考虑原地修改,减少 visited 的空间开销。
而返回结果是需要去重的。出于简单考虑,我们使用集合(set),最后返回的时候重新转化为 list。
刚才我提到了一个关键词“前缀”,我们考虑使用前缀树来优化。使得复杂度降低为$O(h)$, 其中 h 是前缀树深度,也就是最长的字符串长度。
关于前缀树,可以参考我的前缀树 专题。
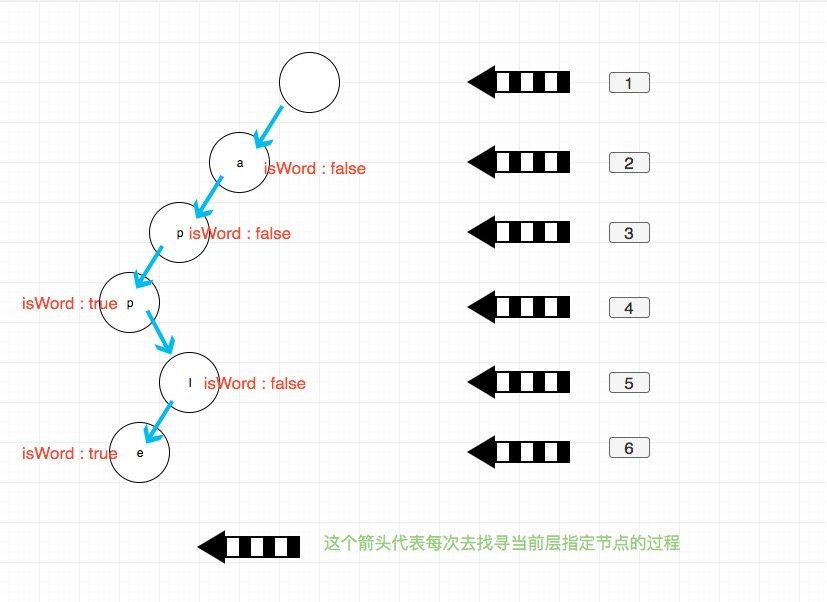
值得注意的是如果每次 dfs 都使用 startsWith 来判断,那么会超时。我们可以将当前遍历到的 trie 节点 以参数传递到 dfs 中,这样可以进一步减少复杂度。
- 前缀树(也叫字典树),英文名 Trie(读作 tree 或者 try)
- DFS
- 剪枝的技巧
- 语言支持:Python3
Python3 Code:
关于 Trie 的代码:
from collections import defaultdict
class Trie:
def __init__(self):
self.children = defaultdict(Trie)
self.word = ""
def insert(self, word):
cur = self
for c in word:
cur = cur.children[c]
cur.word = word主逻辑代码:
class Solution:
def findWords(self, board: List[List[str]], words: List[str]) -> List[str]:
def dfs(row, col, cur):
if row < 0 or row >= m or col < 0 or col >= n or board[row][col] == '.' or board[row][col] not in cur.children: return
c = board[row][col]
cur = cur.children[c]
if cur.word != '': ans.add(cur.word)
board[row][col] = '.'
dfs(row+1,col, cur)
dfs(row-1,col, cur)
dfs(row,col+1, cur)
dfs(row,col-1, cur)
board[row][col] = c
m, n = len(board), len(board[0])
ans = set()
trie = Trie()
words = set(words)
for word in words:
trie.insert(word)
for i in range(m):
for j in range(n):
dfs(i, j, trie)
return list(ans)