- 특정 기사를 입력한다.
- 해당 기사가 어떤 category에 속하는지 classification 한다
- 해당 category에 맞는 model을 load
- 해당 모델로 제목을 예측
get_url.py -> get_content.py -> data_normalize.py -> extract_nouns.py -> get_TFIDF_top20.py -> generate_word_dict.py
-> generator_train_model.py ->
-> generate_pikle_for_category_classification.py -> category_classification.py -> generator_test_model.py -> word_to_index_and_padding.py -> test.py -> execute.py
- get_url.py -> get_content.py
- data_normalize.py -> extract_nouns.py -> get_TFIDF_top20.py -> generate_word_dict.py
- generate_pikle_for_category_classification.py -> category_classification.py
- getnerator_test_model.py -> word_to_index_and_padding.py -> test.py -> execute.py
- Form Data 형식을 입력하여 빅카인즈에 입력하여 해당 형식에 맞는 기사들의 url을 가져와서 저장한다.
- get_url로 만든 csv파일을 이용하여 해당 url에 접속하여 기사 내용을 긁어온다.
- 해당 url에 접속했는데 데이터가 비어있는 경우가 있어서 함수 형태로 만들고 try, exception 조건을 부여함
def insert_df(num):
cnt_fx = num
next_num = cnt_fx
try:
for i in range(cnt_fx,len(data)):
url = df.iloc[:,-1][i]
response = requests.get(url)
test = response.text
test = test.replace('false','"false"')
dic = eval(test)
# url에 접속하면 dictionary 구조
tmp = eval(str(dic['detail']))
data.loc[i] = [tmp['DATE'], tmp['CATEGORY_MAIN'],
tmp['TMS_RAW_STREAM'], tmp['TITLE'],
tmp['CONTENT']]
print(str(cnt_fx)+"번 완료")
cnt_fx += 1
next_num = cnt_fx+1
except SyntaxError:
print(next_num)
insert_df(next_num)- 정규화 진행 (https://github.com/lovit/soy/blob/4c97e35cd78f2079897857c4ad4ec4a4d6a7c0f1/soy/nlp/hangle/_hangle.py)
- 조사, 부사를 제거하고 단어 통일화 작업
- 예를들어 노트북, 노트북이, 노트북을 이라는 단어들이 있다면 노트북 으로 통일화
- Okt를 이용해서 명사만 추출
- 명사 추출 결과를 열로 저장
- 단어 사전 생성
- Komaran을 이용
- NA(분석 불능 범주), NR(수사), NNB(의존명사로 시작하는 단어), IC(감탄사)는 단어 사전에서 제외
- 자음 or 모음만 있는 단어 제외
words.insert(0, ['<PAD>']) # 패딩
words.insert(1, ['<UNK>']) # unknown 단어
if title :
words.insert(2, ['<S>']) # start
words.insert(3, ['<E>']) # end- 공통적으로 padding, unknown을 dict에 추가하고 타이틀에는 start, end 신호를 추가함
- train 모델 생성

- 모델의 구조는 위의 그림과 같음
- 정수 index를 밀집 vector로 mapping 하기 위해서 embedding 층 추가
- 정수를 입력으로 받으면 내부 dict에서 이 정수에 연관된 벡터를 찾아서 반환해 준다.
- 3층의 LSTM을 구성함
- https://arxiv.org/abs/1609.07959
- 위 논문을 참고하면 text prediction에서 single lstm보다 multi LSTM을 사용하면 더 높은 수준으로 수행 할 수 있고 특정 뉴런에 mapping 되는 것을 확인 가능
- 입력 시퀀스가 길어지면 정확도가 떨어지기 때문에 이 부분을 보정하고자 attention layer를 추가 함
- 기사를 입력받으면 해당 기사가 어떤 category인지 분류하기 위한 dictionary 생성
- 수집해놓은 기사들에서 각 기사마다 TFIDF top 20을 추출하여 만든다
- 7번에서 만든 pkl 파일을 load해서 각 단어 수의 count로 판별함
- 가장 단순하게 count만 하지만 정확도가 87% 나왔음
- 오히려 randomforest, LighGBM 모델 정확도가 더 떨어졌음
- test 모델 생성
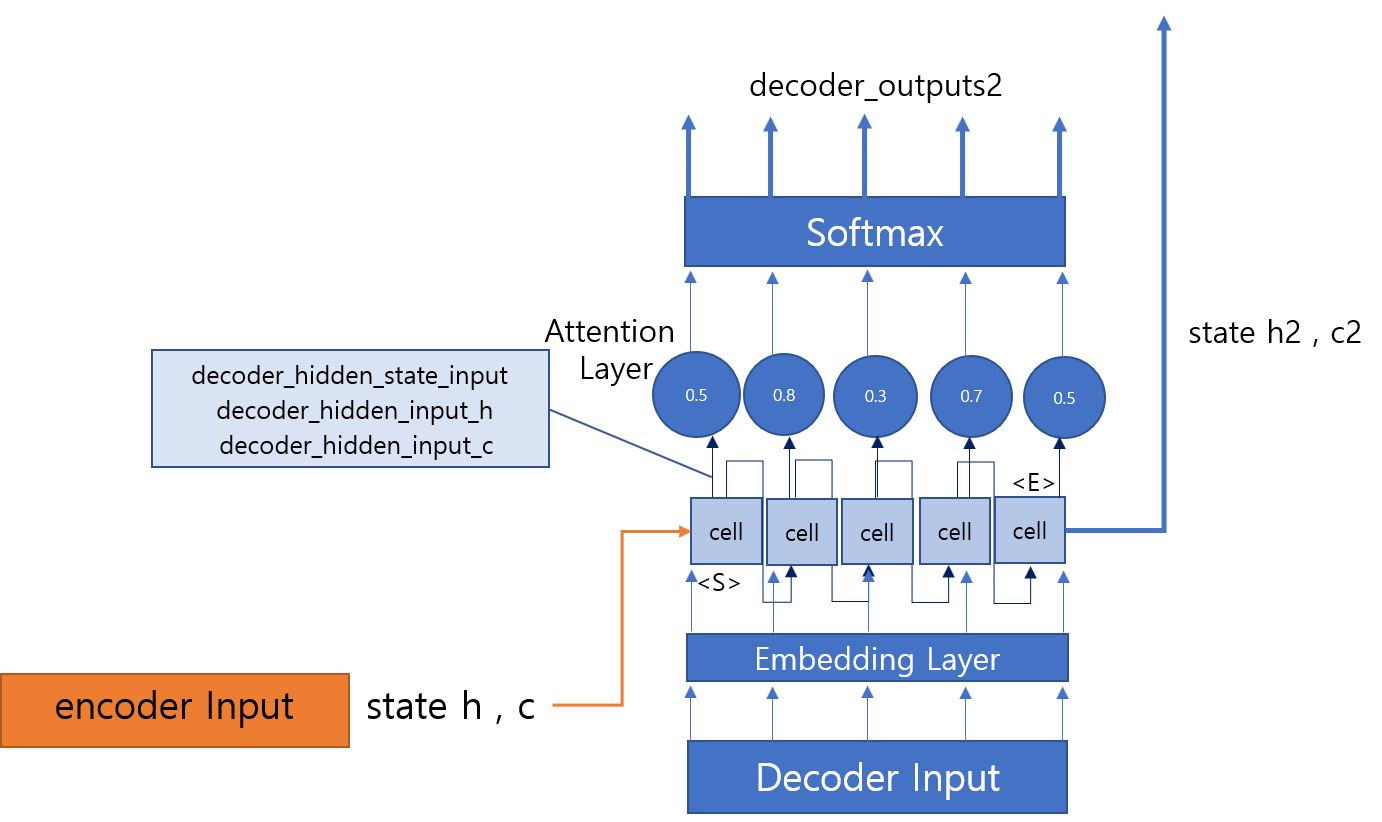
- 6번을 통해 만든 train model에 기사를 넣어 나온 결과를 decode 하기 위한 model
- encoder Input에서 state h,c를 전달받아 decoder lstm층에 전달해준다.
- 기사를 입력하면 정규화하는데 정규화한 기사를 만들어 놓은 dictionary를 통해 벡터화 시킨다.
- title일 경우 다음에 본문을 입력하고 신호를 넣어 입력 종료를 알려준다.
- 기존에 만든 단어사전에 없는 단어일 경우 Unknown이고 가장 긴 기사에 비해 짧게 끝날경우 남은 여백은 padding처리를 한다.
- 실행하기 위한 파일

- H/W
- 테스트를 했던 gpu는 rtx-2070인데 gpu memory가 부족해서 hidden size를 계속 줄여서 테스트를 진행했어야 함
- 이 부분을 해결하고자 colab pro로 진행했으나 역시 한계가 있었다.
- 더 다양한 옵션들로 테스트를 못한게 아쉽다.
- Category 선정
- 날씨를 예로 들면 너무 똑같은 기사가 반복이 된다. 이에 따라 똑같은 제목이 나옴
- 최근 3년 기사를 분석하면 황사의 영향으로 흐린 날씨가 너무 많이 나오는데 날씨 관련 기사마다 흐리다라는 결론으로 많이 나옴
- 비리 분야도 마찬가지로 대통령 탄핵과 관련된 기사가 많이 나와서 다양하게 분석이 안됨
- 기반 지식
- 실제 논문을 검색해본 결과 한글 NLP를 진행할때는 음운단위로 분해해서 조립해야 좋은 결과가 나온다고 한다.
- 음운 단위로 분해한 후에 조립할때 문법의 영향을 많이 받는데 해당 분야 지식이 없어서 할 수 없던게 아쉽다.
- 한글과 관련된 문법등을 적용하면 더 매끄럽게 글이 나오게 할 수 있음
- 기사를 크롤링할때 기사의 양이 한쪽에만 너무 집중되지 않도록 한다.