Comparison of reading time in pySpark #27
Replies: 8 comments
-
|
Comparison of reading files one by one vs all together in pySpark. We can see that reading them all together is much faster.
|
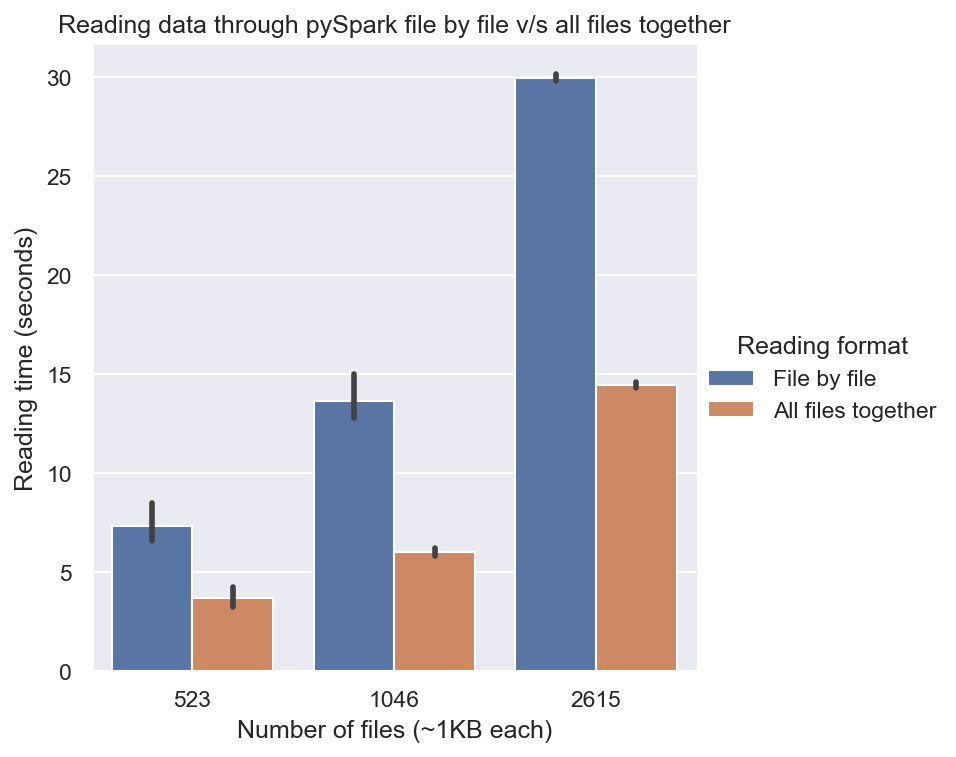
Beta Was this translation helpful? Give feedback.
-
|
Comparison of reading files with vs without schema in pySpark. We can see that reading them with schema is much faster.
|

Beta Was this translation helpful? Give feedback.
-
|
v nice work @thepushkarp
presume this is with schema e.g. 2615KB in ~15 sec? Even though it seems faster than the equivalent 2615KB read in the (schema vs no-schema) plot ~20 sec. |
Beta Was this translation helpful? Give feedback.
-
Yes, it was done with schema. In fact, the one with schema, and the one where all files are read together have the same lines of code.
Thanks for pointing it out. I computed this locally on my PC, and the plot shows the mean score of 10 runs, with variance as the black bar. I guess this difference might be due to some background process, as the plot with 2615KB read has a larger variance compared to other plots. Still, I will try to simulate it again in an isolated environment such as Google Colab and re-report the findings. |
Beta Was this translation helpful? Give feedback.
-
|
Updated comparison graphs run on Google Colab. The times with schema and with all files together are now similar in both graphs. I think some background processes on my local machine would have been the culprit behind the discrepancy! Link to Colab Notebook: https://colab.research.google.com/drive/19gXQfZ2feazau4rXlG17qbDAoj_6csD_?usp=sharing
|
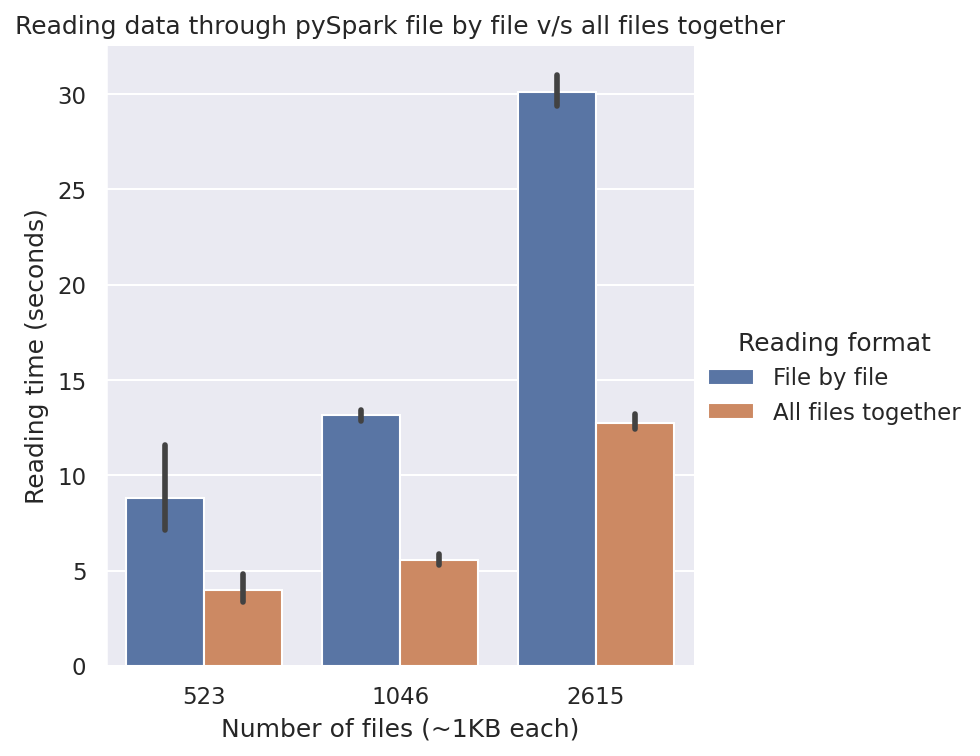
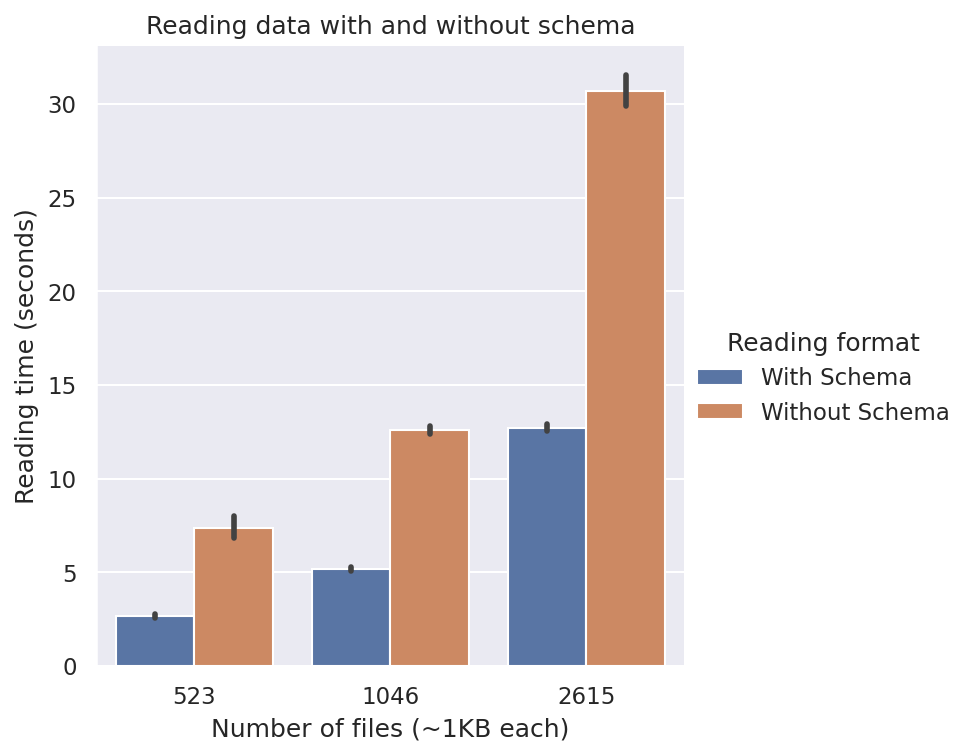
Beta Was this translation helpful? Give feedback.
-
|
Would be interesting to see if the speedup is constant or not, as you scale up. Naively I might expect an increase in efficiency as you presumably need to read the data completely before inferring the schema in the 'no-schema' read. But might eyeballing the set maybe this isn't the case? |
Beta Was this translation helpful? Give feedback.
-
|
Yeah, would be a good experiment to see how much reading time changes when you scale up. I think we could use a study data to do it once the i/o module is done. |
Beta Was this translation helpful? Give feedback.
-
|
Sure, it would be interesting to run this analysis on data of the scale of real-world data.
Cool! |
Beta Was this translation helpful? Give feedback.
-
Make a detailed comparison between the following to make an informed decision about the choice of DataFrame to use:
Beta Was this translation helpful? Give feedback.
All reactions