DNS 是一種可以將 URL 轉成 IP 位置的機制,舉例來說,我們會輸入「github.com」網址來找 Github 官網,背後原理就是向 DNS 詢問,藉此得到它的 IP 位置來進行跳轉,下圖的 Remote Address 即是 Github 的位址,我們使用 DNS 提供的服務來解析 URL 成數字

網際網路上的所有電腦,從手機或筆電到其他提供內容服務的伺服器,其實是使用數字找到彼此並互相通訊,這些數字稱為 IP 地址。
但就像人們的手機號碼一樣,一串長長的數字穰人難以記憶和辨識,才會出現電話簿這種東西來解決我們識別的問題,管理名稱和數字之間的關係,DNS 就如同早期的 104 查號台,報出名字及地址可以得到正確的位址,說穿了 DNS 就是一個轉換服務,讓有意義的、人們較容易記憶的主機名稱,轉譯成為電腦所熟悉的 IP 位址,因為路由器只認得 IP 位址、不認得網址,免去了強記號碼的麻煩。
使用網址來連接網路主要是為了方便人類記憶
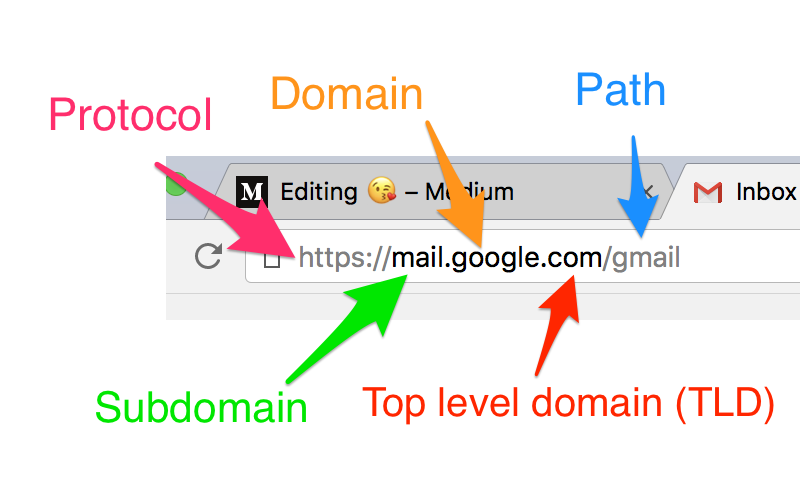
這世界的網址那麼多,一台 DNS 伺服器怎麼可能知道這麼多網址對應的 IP 位址呢?於是全世界所有的網址,被區分為許多不同的「網域(Domain)」
- 根網域(Root domain):根網域是 DNS 架構最上層的伺服器,全球共約 16 台,當下層的任何一台 DNS 伺服器無法查出某個網址對應的 IP 位址時,則會向最上層負責根網域的 DNS 伺服器查詢
- 頂層網域(Top level domain):使用國際標準組織(ISO)所制定的國碼(Country code)來區分頂層網域 例如:美國使用「us」、台灣使用「tw」、中國大陸使用「cn」、日本使用「jp」
- 第二層網域(Second level domain):由使用單位向各國的網址註冊中心申請
- 主機網域(Host domain):由各使用單位之網管人員,依照實際需要自行細分成許多主機使用,每一台主機可以設定一個網域名稱
- 使用者開啟瀏覽器,在網址列輸入
www.example.com,然後按 Enter www.example.com請求路由會到 DNS 解析程式,將轉送到 DNS 根名稱伺服器- 再次轉送,這次轉送到
.com網域的其中一個 TLD 名稱伺服器 - 伺服器會在 example.com 託管區域中尋找
www.example.com記錄,取得關聯的 IP 位置 - DNS 解析程式最終取得使用者需要的 IP 地址,將該值傳回瀏覽器,也會將其 IP 地址快取(存放)一段時間
Google Public DNS 是 Google 對大眾推出的一個公共免費域名解析服務。
DNS 是一個很大的表格,在網路世界分成了十幾個伺服器,再分成國家、網際網路服務商與公司,區分成不同層級的 DNS,而全世界的 DNS 是層層回報、做同步的動作,可想而知,若能直接使用最上層的根(Root)層級的 DNS,就比較能快速掌握正確的網站位址,而網路巨擘 Google 所提供的 DNS 服務,當然上網速度、更新速度更快。
但是,為什麼 Google 要提供免費公開的 DNS? 使用者選擇 Google Public DNS,不外乎就是因為它的服務好、操作快速和安全性佳,至於 Google 的目的是什麼?參考 Quara 上的回答 Why does Google provide free open DNS servers?,在使用者看不到的背後,其實藏了強大的商機── 數遽與流量。
a free offering is really an ingenious way to get free data
這些可以帶來什麼?搜尋結果可以分析趨勢、了解使用者行為,Google 廣告和Google 地圖都是大量數據帶來的結果。
在說明 lock 之前,需要先認識什麼是 Transaction,Transaction 在關聯式資料庫(Relational Database)裡面是一個很重要的特性,它是指用戶端傳送給資料庫引擎所要執行的動作,卻不單單只是一個動作,準確的說是「一組動作」,以轉帳為例:A 要轉 100 塊給 B,這中間包含
- 從 A 的戶頭扣除 100
- 把 B 戶頭加上 100
- 上面兩者都完成,轉帳成功
所謂轉帳,實際上包含了好幾步,但是他們的成敗都必須算在一起,以一系列的操作為一個單位,任一失敗都會導致整個交易失敗(總不能 A 沒扣到錢,但是 B 收到錢了吧?),在我們以前用過的 sql 語法裡,其實已經碰過 Transaction 概念了,例如 UPDATE 指令
這個語法會告訴資料庫引擎去尋找 table 表格,然後再將這個表格裡 column 欄位的內容改成 'something'
UPDATE table SET column= 'something'
它本身就是一個 Transaction,其特性需要有足夠的單獨性、一致性、持續性以及不被干擾的特質,也就是常聽到的 ACID(下一題會討論),所以 Transaction 並沒有想像中難懂,它就是一個單元工作 unit of work,裡面包括了數個步驟來完成,多個步驟全部執行成功,才算交易成功並會提交變更,如果當中有一個失敗,整個交易宣告失敗並回復所有變更,Transaction 的結果只有兩種,一個是成功 Commit,另一個是放棄 Abort。
知道了 Transaction,現在來講講資料庫的鎖定,我們延續上面轉帳的問題來思考,為什麼需要做資料庫鎖定? 轉出扣款與存入帳號兩個操作,他們必須有一致的結果,不是全部成功、進行資料庫變更,就是全部失敗、回復原始狀態,不可以出現部分成功或部分失敗的情況,這樣會違背 Transaction 特性。 想一想,多筆交易在進行資料的讀取與寫入的時候,彼此實際上是會相互影響的,如果兩個交易請求同時抵達資料庫、同時存取到,Server 一起處理,但是我們不知道哪個會先執行成功,或是 Transaction A 執行到一半的結果被 Transaction B 存取到,但最終 Transaction A 最終沒有執行成功而回復狀態,而 Transaction B 輸出了錯的結果。
說明了我們為什麼需要 lock 鎖定機制,因為保證交易不受干擾。
資料在讀取或是寫入的時候,會被做一個記號,這個記號用來告知該資料正在被讀取或是被寫入的狀態,其他後存取到的交易則會根據這個記號,來決定是否要等待到該交易結束或直接讀取,該「記號」就是所謂的 Lock
資料庫的 lock,就像我們去五金行買的鎖一樣,分等級和種類。
想像一下,如果資料庫是一個大房間,那你就會明白區分 Lock Granularity(層級)為什麼重要,如果一整個大資料庫限制每次只能有一個使用者的話,當一個人拿到房間鑰匙進去,其他人就必須要在外面等待,等到他完成、放回鑰匙,下一個人拿了鑰匙再進去操作,其他人繼續乾等,這樣的資料庫實務上並不好用。
在考慮了交易資料完整性的前提下,怎麼讓多人存取到才是重點,Lock 不應該對整個 table 或檔案進行鎖定,而是要進一步細分它的的最小單位:
Row Locks —> Key Locks –> Page Locks –> Extents Locks –> Table Locks
依據鎖定的範圍可以分成 Row 列級鎖定(每一筆的紀錄,也是最小單位)、Key 索引鎖定、Page 頁級鎖定、Extent 擴展鎖定(每八個 Page 為一個 extent,用於 SQL Server 儲存空間的分配,例如 index 重建時)、Table 表級鎖定,以及 Database 資料庫級鎖定。
鎖定的範圍越小,耗用的資源越大;鎖定的範圍越大,耗用的資源越小,其實也很好理解,Table lock 範圍下我們只需要一個鎖和一個管理員就能管好資料庫,現在大房間的鎖拆了,裡面多出了一格格的上鎖盒子,自然需要耗費更多心力來控管。
如果資料上有 lock,是不是別人就不能夠讀取及寫入?這個問題,參考 資料庫的交易鎖定 Locks,某些狀態下的鎖仍然能進行讀取,就像鎖的範圍有區別,鎖的安全性同樣也有區別,一般 lock 鎖定機制模式有三種狀態:
- Shared Mode 共用鎖定
- Update Mode 更新鎖定
- Exclusive Mode 獨占鎖定
- 用於讀取資料
- SQL 語法:SELECT
-- Query 1
Select gender FROM table1
-- Query 2
Select gender, CustomerID FROM table1
一旦 name 被讀取,就會進入 Shared lock,可以同時兩筆交易讀取 Name 欄位,讀取完畢後會立刻釋放 Shared lock,不需要等到 Transaction 整個結束
- 用於資料更新或是寫入,是 Update 的第一步驟
- SQL 語法:UPDATE
-- Query 1
UPDATE gender FROM table1
-- Query 2
Select gender FROM table1
資料更新的步驟是
- 先讀取資料庫找到對應欄位,進入 Update Mode
- 等到要進行寫入時,才將模式轉為 Exclusive Mode,這也是為何我說它只是第一步驟。
它的特性是,對於同一資源只能有一個 Update lock 存在,但其他 Shared locks 仍可以同步進行讀取,這是因為鎖定機制主要影響的是在同步寫入的階段,而不是同步讀取的問題。
- 用在當資料修改、寫入時,避免其他交易請求的同步存取
- SQL 語法:Insert, Update, DELETE 都會產生
- 確保其他交易不會同時讀取或寫入「正在修改」的資料
INSERT 與 DELETE 都會在交易一開始就取得 Exclusive lock,在交易結束之前,其他的鎖定請求都會被拒絕,因為一個資源同時只能有一個 Exclusive lock 。 而 UPDATE 一開始先做 Update lock,等待要寫入時再轉換。
對於資料庫 lock 的認識,先到這裡,當我們知道了 transactino 交易的特性之後,自然可以理解為什麼有 lock 機制出現與其重要性,其他專有名詞如 Lock Escalation、Intent Shared、Intent Exclusive、鎖的相容性,就留待之後有機會補充啦!
首先要搞清楚,SQL 並不是指資料庫系統,而是指一種程式語言,只是很多系統是使用 SQL 來查詢的資料庫,像是 Oracle 的 MySQL 、Microsoft 的 SQL Server 等。SQL(Structured Query Language)是一套層次分明、規定清楚的查資料指令,而 NoSQL(Not Only SQL)指的是除了 SQL 以外的查詢方法。
以 SQL 為基礎的資料庫系統,有兩個重要特性:
- 格式確定 是在建立之初就定義好資料表格,Schema 像是資料庫的規格書,有哪些欄位、每個欄位的型態都是先決定好,
- 關聯式資料 (Relational Database) 為了要讓資料儲存跟取得容易,以一個或是多個資料表 (table) 的方式存放,負責紀錄不同的資料,卻又彼此關聯
NoSQL 是不限定為「關聯式資料庫」的資料庫系統統稱,和 SQL 最大的差別,是沒有 schema 這種東西,不必事先知道要存哪些資料(schema-free),比較彈性,通常儲存格式是 JSON。
- 不講求資料同步,只求結果一致
- 用於搜集數據,因各家資訊不同,用 NoSQL 直接把資料存進去而不用考慮欄位問題
隨著網路、應用程式的普及,流量大幅增長,進入了以「使用者生產內容(user generated content)」為主流的時代,對 Youtube、Facebook 這些大型社交網站來說,每分每秒需要處理的資料量是過去一般網站的數倍。
而對使用者來說,他們對於資料需求也跟過去不一樣。資料庫的主要功能,從過去的「能夠無錯誤同步處理結構清楚的資料」,到現在慢慢有新需求誕生:「能處理高速且大量產生的資料」不需要即時同步,也不需絕對零錯誤,才會有像 NoSQL 資料庫的興起誕生。
ACID,指的是 transaction 四個基本要求:原子性(Atomicity)、一致性 (Consistency)、隔離行為(Isolation behavior)與持續性(Durability)
一個交易是一個單元工作,當中包括數個步驟,這些步驟要嘛全部執行成功、整筆交易就成功,如有一個失敗,則宣告失敗,其它本來成功的步驟也必須撤消、回復到交易前的狀態,
在 Transaction 執行前後,資料皆處於合乎所有規則的狀態,不能發生整個資料集合,部份有變更、而部份沒變更的狀態
不同的 Transaction 之間執行時不能被彼此干擾,假設有兩個 Transaction 在同一時間對相同的資料進行更新,而其中一個 Transaction 在更新到一半時產生錯誤,於是進行資料回復,然而,另一個 Transaction 是完成的.可想而知最後的資料狀態一定是無法預測。
實現隔離性,可以參考資料庫的鎖定機制(lock)。
交易一旦成功,則所有的變更必須保存下來,即使系統掛了、電力中斷,交易結果也不能遺失,這個功能是建立在資料庫或相關資源伺服器之上,運作後的資料都必須存在於儲存媒介,例如硬碟裡。
一個資料庫的效能往往也由它對 ACID 特性的執行效率來決定.所以發生問題都會是在寫入動作上.寫入代表刪除或更新,會改變資料庫內的資料狀態.如果你有一個資料庫只需要提供讀取而沒有寫入,那麼 ACID 特性對資料庫引擎而言就沒什麼意義。