Improve performance of fact propagation through the Rete graph #200
Comments
|
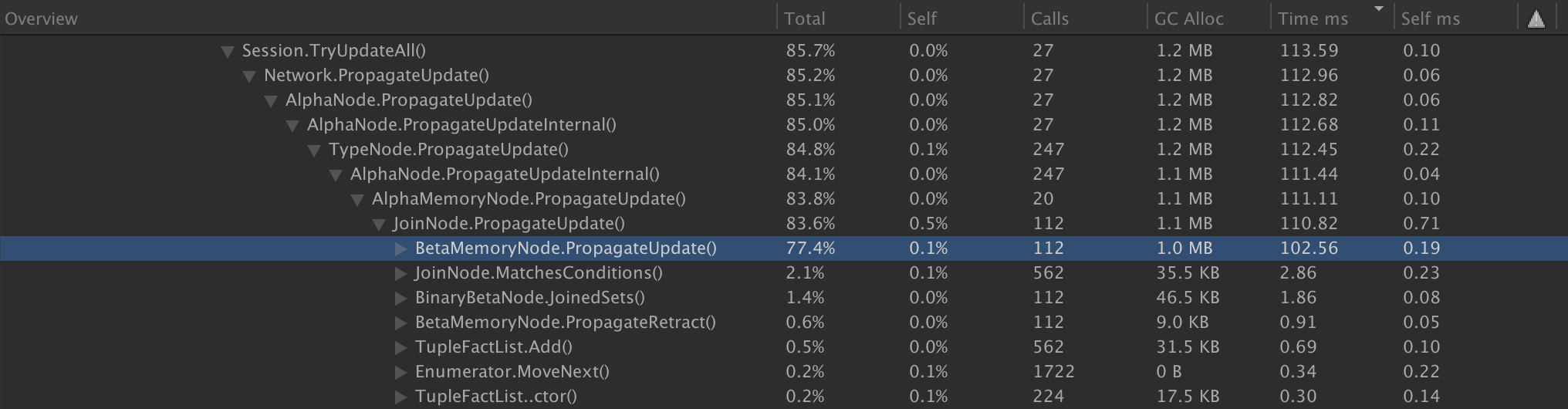
I've done a bit of analysis using the Unity3D profiler and our NRules codebase. This is running NRules as of: branch: develop Our codebase has approximately 110 rules spread among multiple NRules sessions. Many have Ors, multiplying the complexity of the Rete nets. At the point of this snapshot, there were on the order of hundreds of facts in the sessions. All sessions contain the same set of facts. As you can see by looking at the profile images, the largest offender for allocations is JoinNode.PropogateUpdate, which in this snapshot allocated 1.1MB.
Drilling into that a bit, the most allocation-intensive spots are:
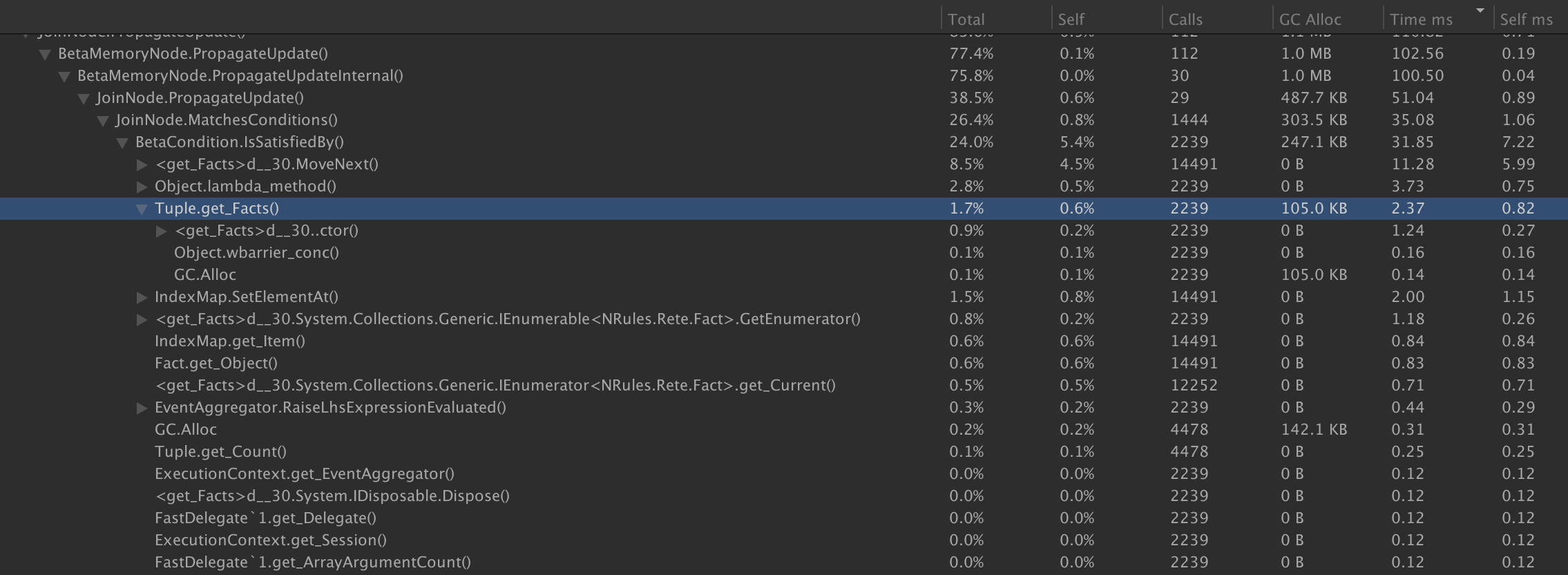
BetaCondition.IsSatisfiedBy() is definitely the most intensive point of allocations in JoinNode.PropagateUpdate, NotNode.PropagateUpdate and ExistsNode.PropagateUpdate. In this instance, JoinNode.PropagateUpdate.MatchesConditions allocates 247.1KB in its calls to BetaCondition.IsSatisfiedBy(). Of that, 105KB is allocated in calls to Tuple.get_Facts(), which constructs new Tuple instances. The remainder is not specifically detected as can be seen by the unspecified GC.Alloc line of 142.1KB. Unity's profiler is not able to precisely identify which of the other calls the allocations are associated with.
NotNode and ExistsNode show a similar pattern of allocations:
|






|
@snikolayev I'm bringing our conversation from gitter over here for context, and I've switched accounts to one that's more appropriate for me. snikolayev: larry: The object arrays created in the LHSExpression Invoke methods look like they'd be pretty straightforward to pool. Do you believe that swapping these arrays out for List that are cleared and repopulated each time would offer an allocation advantage? If that won't help significantly, I could also imagine caching a Dictionary<ITuple, object[]> to be used by these LHSExpression methods. I believe this would work because the object[] will always be the same size for the Tuple. Obviously, this cache would need to be updated whenever a given tuple's facts change. That could either be done by iterating through them and updating them on each call to Invoke, or by checking for a "dirty" flag on the tuple which would indicate that the facts have changed since the last invoke, though that'd be more complex. For the Tuple.Facts IEnumerable, I could give each Tuple a List that's cleared and repopulated by walking the tuples on each call to get the IEnumerable. However, again, maybe there'd be a more efficient way to do that and only update the Facts list as needed. Think that'd be possible? Actually, I assume it's possible that the Facts property for a given Tuple will be called while another caller is already iterating through its facts. So that'd mean that clearing the same reusable list with each call wouldn't be safe. snikolayev: |
|
Regarding LhsExpression.Invoke, currently each call to invoke calls
If I understand correctly, this means that with each call to invoke, an amount of stack memory will be allocated equal to (object pointer size) * (args.Length). Then, at the end of the execution of Invoke(), that memory is free to be garbage-collected. It seems that instead, the entire class could have just one reusable object[] that's instantiated in the constructor like this:
Then, on each call to invoke it could be repopulated like this: I believe this would mean that the memory would now be allocated only once for the lifetime of the LhsExpression object. That sounds like a major win, but I may be totally off on this, or there may be a more optimal solution. The compatibility issue of ArrayPool does seem problematic. I work primarily with the Unity 3D game/interactive application engine, and it doesn't seem to have include the System.Buffers namespace by default. However I was just able to get the System.Buffers dll via NuGet and it seems to work at first glance. So not sure how much of an issue this is. Regarding Tuple.Facts, pooling enumerators sounds interesting. I haven't explored that before, but sounds like a solid solution. It is my understanding that a List doesn't allocate any memory on a call to List.GetEnumerator(). Supposedly since the enumerator is a struct it's allocated on the stack, not the heap, but I'd like to verify this. If that is the case, then it does also seem that an implementation where each Tuple reuses a List, and updates that List only when the facts list needs to be updated would be an overall optimization. But it sounds more complicated to support that. In the current implementation, where exactly is the memory being allocated in the Facts getter? Is it purely in boxing/unboxing? Also, to clarify, is it possible that, for a given Tuple, Tuple.Facts can be accessed concurrent with another iteration through Tuple.Facts? |
|
For what it's worth, I was able to verify via memory profiling that this implementation allocates no memory on calls to the Facts property: |
|
I also confirmed that using an ArrayPool doesn't allocate additional memory on Rent/Return. So totally agree that would be a good option if the compatibility issues are solvable. |
|
@larrybehaviorlanguage I think it's a promising idea to pre-allocate the array in LhsExpression. Interestingly, in benchmarks, allocating a new array is faster than clearing an existing array with Array.Clear. But, I'm verifying if maybe I don't need to clear the array, given that each expression is using the same slots in the array and is guaranteed to overwrite them. |
|
Regarding tuple enumerator - tuple in NRules is meant to be a recursive data structure, similar to lists in functional languages, where it's incrementally constructed by adding new facts to an existing tuple, incrementally, w/o materializing the whole list at every level. Essentially every tuple object creates an N+1 tuple out of an N-tuple. Creating a list of facts inside each tuple defeats that purpose. It will allocate an array of all N+1 facts, compounding at each level. And so, even though it will allocate it only once per tuple, it will still destroy performance. |
|
@larrybehaviorlanguage one thing I wanted to ask you is why is it so important for you to reduce allocations. Gen 0 allocations that are short-lived are actually very efficient from the GC perspective. What's your overall worry? Also, are there specific problems or perf/memory issues you are experiencing and believe are due to allocations? |
|
@snikolayev Great - reusing the array in Invoke sounds even better if you're always guaranteed to overwrite it per call. |
|
As for the tuple enumerator, that totally makes sense. IEnumerator pooling certainly sounds preferable if possible. I'll think on that and try some more experiments to see if I can come up with a non-allocating implementation. Again, I fear that currently the allocations may actually be partially from boxing/unboxing. So any solution would need to take care of that problem as well. I suppose another option would be to pool lists and use them for the enumeration as shown above. clearing and populating them on demand. In this way, the tuples would share the resources, instead of creating one List per Tuple. I'll investigate that as well, though pooling just the enumerators definitely sounds better if it can work. |
|
@snikolayev As for why I'm so concerned about allocations, I may be in a minority where my use of NRules is for realtime, performance-intensive graphical applications. Specifically, games using the Unity3D game engine. In such applications, the graphics thread needs to run at a constant framerate, or the game will feel unresponsive and laggy. Typically that's something on the order of 16 milliseconds to let all game components update, including the graphics rendering to achieve a framerate of 60 frames/second. In my applications, NRules runs evaluation totally asynchronously so it can't block the main thread, but garbage collection must run on the main thread. So, it's very important to minimize garbage collection as much as possible, even if it's efficient. Currently, when I trigger a major NRules fact update, I'll see frame-rate drop because of garbage collection. In a different application, these levels of allocation would likely be completely fine. |
|
@snikolayev After doing some more digging, I have confirmed that the reason we're seeing allocations for Tuple.Facts enumeration is purely because this is a value type that needs to be boxed to be usable as an IEnumerator reference type. This is the same type of boxing allocation you'll see if you store a value type like an int in an object, like this: If we follow the pattern set forth in List, which uses a struct enumerator and relies on C# "duck typing" vs the IEnumerator interface, this eliminates all allocations. I did a quick test in a sandbox and confirmed that this causes no garbage-collectable allocations since everything is on the stack. This solution also addresses any concerns about asynchronous access since each access gets its own enumerator struct, just like with a List. The TupleFactsEnumerable could be eliminated altogether if the GetEnumerator() method were just added directly to Tuple in place of the Facts. It's more or less a wrapper to stay consistent with the current iteration implementation of: `foreach (Fact fact in tuple.Facts) {}' Otherwise, it could be updated to allow iteration as: `foreach (Fact fact in tuple) {}' One thing this doesn't address is the case of a Tuple's "list" of facts being altered during iteration. However, I don't believe the current implementation addresses this either. Perhaps this is not possible in NRules? There are various discussions about this use of "duck typing" for efficient enumeration around online. Obviously it violates some contracts of C# as a strongly typed language and requires a mutable struct, but allows for iteration with no allocation, so seems like a reasonable trade-off for special cases. |
|
@larrybehaviorlanguage something does not add up here. Boxing/unboxing would only happen if the enumerator was a struct (like you wrote in your prototype). But in NRules Tuple.Facts is a generator, which is compiled by Roslyn into a private class. Here how it looks, as I decompiled the binary: As you can see it extends Object, not ValueType, so it's a class, not a struct, and there should be no boxing/unboxing happening. |
|
Ahh, very interesting. I incorrectly assumed it must be a value type under the hood, but this makes sense. Thanks for explaining. Regardless, it seems like the struct option eliminates the heap allocation problem. |
|
Though pooling of these would likely also be an option if you still prefer that. |
|
Yep, I'm going to look at both options and see what works best |
|
@larrybehaviorlanguage unfortunately reusing array arguments for expression evaluation didn't work. A rete network (and expressions are part of the rete network) is shared between one or more sessions. So, if there are multiple sessions used from different threads, these shared arrays will lead to data corruption. I reverted the change and will now look at other mechanisms for reducing allocations. |
|
@snikolayev Ah, gotcha. I've never used asynchronous sessions for the same rete, but that totally makes sense. Would it instead be possible to give each expression a synchronized Stack<object[]>? During Invoke, you could try to pop an array from the stack to use. If none are available, just instantiate one. Then, at the end of Invoke, push it back onto the stack. |
|
@larrybehaviorlanguage I'm going to experiment with ArrayPool and thread local storage. I want to reduce allocations, but at the same time I want to make sure this does not happen at the expense of performance, so need to carefully navigate this line. |
|
@snikolayev That makes total sense. I'd imagine that replacing any allocations with reuse of arrays or collections would in general be a performance improvement with the side benefit of eliminating the allocation itself. However, I may be off on that, or there may be exceptions. Regardless, you would hope that Microsoft themselves would make the most optimal solution with ArrayPool vs a homegrown solution with a synchronized Stack as I suggested. I just know that you were concerned about depending on ArrayPool limiting the number of possible platform targets for NRules. |
- Optimize tuple looping by using a struct iterator and eliminating allocations - Optimize LHS expression by directly weaving tuple unwrapping into expression, eliminating array allocation - Don't call expression evaluation hooks if no subscribers, eliminating result boxing TODO: - Lazily populate arguments array on expression evaluated subscription - Optimizer RHS and filter expressions
- Weave tuple unwrapping into optimized expression, to eliminate array allocation - Weave dependency resolution into optimized expression if rule uses dependencies - Eliminate terminal node and index map at the activation level and bake it into the compiled rule and action expressions
- Only pay the cost of allocation and evaluation for expression arguments if there are subscribers to lifecycle events, or if accessing via action invocation
* Optimize expressions #200 - Optimize tuple looping by using a struct iterator and eliminating allocations - Optimize LHS expression by directly weaving tuple unwrapping into expression, eliminating array allocation - Don't call expression evaluation hooks if no subscribers, eliminating result boxing - Weave tuple unwrapping into optimized expression, to eliminate array allocation - Weave dependency resolution into optimized expression if rule uses dependencies - Eliminate terminal node and index map at the activation level and bake it into the compiled rule and action expressions _ Eliminate terminal node - Only pay the cost of allocation and evaluation for expression arguments if there are subscribers to lifecycle events, or if accessing via action invocation
|
@larrybehaviorlanguage I managed to get rid of all allocations around expressions evaluation, eliminate boxing and also improved performance. Details under #227. It ended up more complex than you and I discussed, but I'm very happy with the result. |
Reduce the number and extent of allocations during fact propagation.
Also improve performance of Rete graph, particularly when joining facts.
The text was updated successfully, but these errors were encountered: