- Science of Learning
- Resource on Deep Learning Theory
- Interpretability in AI
- Physics and Deep Learning
- Mathematics of Deep Learning
- Dynamics and Deep Learning
- Differential Equation and Deep Learning
- Approximation Theory for Deep Learning
- Inverse Problem and Deep Learning
- Random Matrix Theory and Deep Learning
- Deep learning and Optimal Transport
- Geometric Analysis Approach to AI
- Topology and Deep Learning
- Algebra and Deep Learning
- Probabilistic Theory and Deep Learning
- Statistics and Deep Learning
- Information Theory and Deep Learning
- Brain Science and AI
- Cognition Science and Deep Learning
- The lottery ticket hypothesis
- Double Descent
- Neural Tangents
V. Vapnik said that ``Nothing is more practical than a good theory.'' Here we focus on the theoretical machine learning.
- CONSTRAINT REASONING AND OPTIMIZATION
- https://www.math.ubc.ca/~erobeva/seminar.html
- https://www.deel.ai/theoretical-guarantees/
- http://www.vanderschaar-lab.com/NewWebsite/index.html
- https://nthu-datalab.github.io/ml/index.html
- http://www.cs.cornell.edu/~shmat/research.html
- http://www.prace-ri.eu/best-practice-guide-deep-learning
- https://math.ethz.ch/sam/research/reports.html?year=2019
- http://gr.xjtu.edu.cn/web/jjx323/home
- https://zhouchenlin.github.io/
- https://www.math.tamu.edu/~bhanin/
- https://yani.io/annou/
- https://probability.dmi.unibas.ch/seminar.html
- http://mjt.cs.illinois.edu/courses/dlt-f19/
- http://danroy.org/
- Symbolic Methods for Biological Networks
- https://losslandscape.com/faq/
- https://mcallester.github.io/ttic-31230/
- https://sites.google.com/view/holist/home
Deep learning is a transformative technology that has delivered impressive improvements in image classification and speech recognition. Many researchers are trying to better understand how to improve prediction performance and also how to improve training methods. Some researchers use experimental techniques; others use theoretical approaches.
There has been a lot of interest in algorithms that learn feature hierarchies from unlabeled data. Deep learning methods such as deep belief networks, sparse coding-based methods, convolutional networks, and deep Boltzmann machines, have shown promise and have already been successfully applied to a variety of tasks in computer vision, audio processing, natural language rocessing, information retrieval, and robotics. In this workshop, we will bring together researchers who are interested in deep learning and unsupervised feature learning, review the recent technical progress, discuss the challenges, and identify promising future research directions.
The development of a "Science of Deep Learning" is now an active, interdisciplinary area of research combining insights from information theory, statistical physics, mathematical biology, and others. Deep learning is at least related with kernel tricks, projection pursuit and neural networks.
- Understanding Neural Networks by embedding hidden representations
- Tractable Deep Learning
- DALI 2018, Data Learning and Inference
- MATHEMATICS OF DEEP LEARNING, NYU, Spring 2018
- Theory of Deep Learning, project in researchgate
- THE THEORY OF DEEP LEARNING - PART I
- Magic paper
- Principled Approaches to Deep Learning
- A Convergence Theory for Deep Learning via Over-Parameterization
- Advancing AI through cognitive science
- Deep Learning and the Demand for Interpretability
- Doing the Impossible: Why Neural Networks Can Be Trained at All
- Deep Learning Drizzle
- A Comprehensive Analysis of Deep Regression
- Deep Learning in Practice
- Deep learning theory
- The Science of Deep Learning
- TBSI 2019 Retreat Conference
- http://principlesofdeeplearning.com/
- https://cbmm.mit.edu/education/courses
- DALI 2018 - Data, Learning and Inference
- On Theory@http://www.deeplearningpatterns.com
- https://blog.csdn.net/dQCFKyQDXYm3F8rB0/article/details/85815724
- CoMS E6998 003: Advanced Topics in Deep Learning
- Analyses of Deep Learning (STATS 385) 2019
- Deep Learning Theory: Approximation, Optimization, Generalization
- UVA DEEP LEARNING COURSE
- Theories of Deep Learning (STATS 385)
- Topics Course on Deep Learning for Spring 2016 by Joan Bruna, UC Berkeley, Statistics Department
- Mathematical aspects of Deep Learning
- MATH 6380p. Advanced Topics in Deep Learning Fall 2018
- 6.883 Science of Deep Learning: Bridging Theory and Practice -- Spring 2018
- (Winter 2018) IFT 6085: Theoretical principles for deep learning
- STAT 991: Topics in deep learning (UPenn)
yanjun organized a wonderful reading group on deep learning.
- http://www.mlnl.cs.ucl.ac.uk/readingroup.html
- https://labrosa.ee.columbia.edu/cuneuralnet/
- http://www.ub.edu/cvub/reading-group/
- https://team.inria.fr/perception/deeplearning/
- https://scholar.princeton.edu/csmlreading
- https://junjuew.github.io/elijah-reading-group/
- http://www.sribd.cn/DL/schedule.html
- http://lear.inrialpes.fr/people/gaidon/lear_xrce_deep_learning_01.html
- https://simons.berkeley.edu/events/reading-group-deep-learning
- https://csml.princeton.edu/readinggroup
- http://www.bicv.org/deep-learning/
- https://www.cs.ubc.ca/labs/lci/mlrg/
- https://calculatedcontent.com/2015/03/25/why-does-deep-learning-work/
- https://project.inria.fr/deeplearning/
- https://hustcv.github.io/reading-list.html
- http://pwp.gatech.edu/fdl-2018/program/
- Symposium Artificial Intelligence for Science, Industry and Society
- 4th Workshop on Semantic Deep Learning (SemDeep-4)
- TAU & GTDeepNet seminars
- NeuroIP 2018 workshop on Deep Learning Theory
- Toward theoretical understanding of deep learning
- The Science of Deep Learning
- PG Program in Artificial Intelligence & Machine Learning: Business Applications
- Explainable AI Workshop
- https://people.eecs.berkeley.edu/~malik/
- heoretical Foundation of Deep Learning (TFDL 2018)
- https://simons.berkeley.edu/programs/dl2019
- https://www.minds.jhu.edu/tripods/
- https://humancompatible.ai/research
- Theory of Deep Learning, ICML'2018
- Identifying and Understanding Deep Learning Phenomena
- https://ijcai20interpretability.github.io/
- https://niceworkshop.org/
- https://ecea-5.sciforum.net/
- NSF, Simons Foundation partner to uncover foundations of deep learning
- https://elsc.huji.ac.il/faculty-staff/haim-sompolinsky
- https://www.neuralnet.science/
- https://carolewu.engineering.asu.edu/
- https://www.nist.gov/artificial-intelligence
- https://humancompatible.ai/
- http://kordinglab.com/
- http://koerding.com/
- https://www.regina.csail.mit.edu/
- https://www.cs.huji.ac.il/~shashua/research.php
- http://www.cns.nyu.edu/~eero/
- https://xiangxiangxu.com/
- http://qszhang.com/index.php/team/
- https://gangwg.github.io/research.html
- http://www.mit.edu/~k2smith/
- https://www.msra.cn/zh-cn/news/people-stories/wei-chen
- https://www.microsoft.com/en-us/research/people/tyliu/
- https://www.researchgate.net/profile/Hatef_Monajemi
- http://networkinterpretability.org/
- https://interpretablevision.github.io/
- https://vipriors.github.io/
- Interpretability in AI and its relation to fairness, transparency, reliability and trust
- https://github.com/jphall663/awesome-machine-learning-interpretability
- https://people.mpi-sws.org/~manuelgr/
- 2nd HUMAINT Winter school on Fairness, Accountability and Transparency in Artificial Intelligence
- https://facctconference.org/network/
- https://calculatedcontent.com/
Although deep neural networks have exhibited superior performance in various tasks, interpretability is always Achilles’ heel of deep neural networks. At present, deep neural networks obtain high discrimination power at the cost of a low interpretability of their black-box representations. We believe that high model interpretability may help people break several bottlenecks of deep learning, e.g., learning from a few annotations, learning via human–computer communications at the semantic level, and semantically debugging network representations. We focus on convolutional neural networks (CNNs), and revisit the visualization of CNN representations, methods of diagnosing representations of pre-trained CNNs, approaches for disentangling pre-trained CNN representations, learning of CNNs with disentangled representations, and middle-to-end learning based on model interpretability. Finally, we discuss prospective trends in explainable artificial intelligence.
- https://www.transai.org/
- GAMES Webinar 2019 – 93期(深度学习可解释性专题课程)
- GAMES Webinar 2019 – 94期(深度学习可解释性专题课程) | 刘日升(大连理工大学),张拳石(上海交通大学)
- http://qszhang.com/index.php/publications/
- Explaining Neural Networks Semantically and Quantitatively
- https://www.jiqizhixin.com/articles/0211
- https://www.jiqizhixin.com/articles/030205
- https://mp.weixin.qq.com/s/xY7Cpe6idbOTJuyD3vwD3w
- http://academic.hep.com.cn/fitee/CN/10.1631/FITEE.1700808#1
- https://arxiv.org/pdf/1905.11833.pdf
- http://www.cs.sjtu.edu.cn/~leng-jw/
- https://lemondan.github.io
- http://ise.sysu.edu.cn/teacher/teacher02/1136886.htm
- http://www.cs.cmu.edu/~zhitingh/data/hu18texar.pdf
- https://datasciencephd.eu/DSSS19/slides/GiannottiPedreschi-ExplainableAI.pdf
- http://www.cs.cmu.edu/~zhitingh/
- https://graphreason.github.io/
- https://beenkim.github.io/
- https://www.math.ucla.edu/~montufar/
- Explainable AI: Interpreting, Explaining and Visualizing Deep Learning
- http://www.prcv2019.com/en/index.html
- http://gr.xjtu.edu.cn/web/jiansun
- http://www.shixialiu.com/
- http://irc.cs.sdu.edu.cn/
- https://www.seas.upenn.edu/~minchenl/
- https://cs.nyu.edu/~yixinhu/
- http://www.cs.utexas.edu/~huangqx/
- https://stats385.github.io/
Not all one can understand the relative theory or quantum theory.
DeepLEVER aims at explaining and verifying machine learning systems via combinatorial optimization in general and SAT in particular. The main thesis of the DeepLever project is that a solution to address the challenges faced by ML models is at the intersection of formal methods (FM) and AI. (A recent Summit on Machine Learning Meets Formal Methods offered supporting evidence to how strategic this topic is.) The DeepLever project envisions two main lines of research, concretely explanation and verification of deep ML models, supported by existing and novel constraint reasoning technologies.
- DeepLEVER
- https://aniti.univ-toulouse.fr/index.php/en/
- https://jpmarquessilva.github.io/
- https://www.researchgate.net/profile/Martin_Cooper3
- http://homepages.laas.fr/ehebrard/Home.html
- http://www.merl.com/
Together with the participants of the Oberwolfach Seminar: Mathematics of Deep Learning, I wrote a (not entirely serious) paper called "The Oracle of DLPhi" proving that
Deep Learning techniques can perform accurate classifications on test data that is entirely uncorrelated to the training data. This, however, requires a couple of non-standard assumptions such as uncountably many data points and the axiom of choice. In a sense this shows that mathematical results on machine learning need to be approached with a bit of scepticism.
- https://github.com/juliusberner/oberwolfach_workshop
- http://www.pc-petersen.eu/
- http://voigtlaender.xyz/
- https://math.ethz.ch/sam/research/reports.html
- The Oracle of DLphi
- https://faculty.washington.edu/kutz/
- https://www.scd.stfc.ac.uk/Pages/Scientific-Machine-Learning.aspx
- https://mitmath.github.io/18337/
- https://www.stat.purdue.edu/~fmliang/STAT598Purdue/MLS.pdf
- https://sciml.ai/
- https://github.com/mitmath/18S096SciML
- https://ml4sci.lbl.gov/
- Scientific computation using machine-learning algorithms
- https://sites.google.com/lbl.gov/ml4sci/
- SciANN: Neural Networks for Scientific Computations
Neuronal networks have enjoyed a resurgence both in the worlds of neuroscience, where they yield mathematical frameworks for thinking about complex neural datasets, and in machine learning, where they achieve state of the art results on a variety of tasks, including machine vision, speech recognition, and language translation.
Despite their empirical success, a mathematical theory of how deep neural circuits, with many layers of cascaded nonlinearities, learn and compute remains elusive.
We will discuss three recent vignettes in which ideas from statistical physics can shed light on this issue.
In particular, we show how dynamical criticality can help in neural learning, how the non-intuitive geometry of high dimensional error landscapes can be exploited to speed up learning, and how modern ideas from non-equilibrium statistical physics, like the Jarzynski equality, can be extended to yield powerful algorithms for modeling complex probability distributions.
Time permitting, we will also discuss the relationship between neural network learning dynamics and the developmental time course of semantic concepts in infants.
In recent years, artificial intelligence has made remarkable advancements, impacting many industrial sectors dependent on complex decision-making and optimization. Physics-leaning disciplines also face hard inference problems in complex systems: climate prediction, density matrix estimation for many-body quantum systems, material phase detection, protein-fold quality prediction, parametrization of effective models of high-dimensional neural activity, energy landscapes of transcription factor-binding, etc. Methods using artificial intelligence have in fact already advanced progress on such problems. So, the question is not whether, but how AI serves as a powerful tool for data analysis in academic research, and physics-leaning disciplines in particular.

- https://julialang.org/jsoc/gsoc/sciml/
- https://zhuanlan.zhihu.com/p/94249675
- https://web.stanford.edu/~montanar/index.html
- Physics Meets ML
- physics forests
- Applied Machine Learning Days
- DEEP LEARNING FOR MULTIMESSENGER ASTROPHYSICS: REAL-TIME DISCOVERY AT SCALE
- Workshop on Science of Data Science | (smr 3283)
- Physics & AI Workshop
- https://physicsml.github.io/pages/papers.html
- Physics-AI opportunities at MIT
- https://deepray.github.io/publications.html
- https://gogul.dev/software/deep-learning-meets-physics
- https://github.com/2prime/ODE-DL/blob/master/DL_Phy.md
- https://physics-ai.com/
- http://physics.usyd.edu.au/quantum/Coogee2015/Presentations/Svore.pdf
- Brains, Minds and Machines Summer Course
- deep medcine
- http://www.dam.brown.edu/people/mraissi/publications/
- http://www.physics.rutgers.edu/gso/SSPAR/
- https://community.singularitynet.io/c/education/course-brains-minds-machines
- ARTIFICIAL INTELLIGENCE AND PHYSICS
- http://inspirehep.net/record/1680302/references
- https://www.pnnl.gov/computing/philms/Announcements.stm
- https://tacocohen.wordpress.com/
- https://cnls.lanl.gov/External/workshops.php
- https://www.researchgate.net/profile/Jinlong_Wu3
- http://djstrouse.com/
- https://www.researchgate.net/scientific-contributions/2135376837_Maurice_Weiler
- Spontaneous Symmetry Breaking in Neural Networks
- https://physai.sciencesconf.org/
- Deep Learning in High Energy Physics
- Machine Learning for Physics and the Physics of Learning
- Machine Learning for Physics
- 2017 Machine Learning for Physicists, by Florian Marquardt
- Machine Learning and the Physical Sciences
- Machine Learning in Physics School/Workshop
- http://deeplearnphysics.org/
- https://inspirehep.net/literature/1680302
- Master-Seminar - Deep Learning in Physics (IN2107, IN0014)
- https://www.ml4science.org/agenda-physics-in-ml
- https://www.ias.edu/events/deep-learning-physics
- https://dl4physicalsciences.github.io/
- https://tartakovsky.stanford.edu/research/physics-informed-machine-learning
- Physics in Machine Learning Workshop
- Physics in Machine Learning Workshop
- A Differentiable Physics Engine for Deep Learning
- Physics Based Vision meets Deep Learning (PBDL)
- Physics-Based Deep Learning
- Hamiltonian Neural Networks
- https://sites.google.com/view/icml2019phys4dl/schedule
- Theoretical Physics for Deep Learning
- https://sites.google.com/view/icml2019phys4dl/schedule
- Physics Informed Machine Learning Workshop
- Physics Informed Neural Networks
- Physics Informed Deep Learning
- https://maziarraissi.github.io/research/1_physics_informed_neural_networks/
- https://github.com/maziarraissi/PINNs
- https://github.com/56aaaaa/Physics-informed-neural-networks
- Physics-informed deep learning imaging
- https://github.com/DeepNeuralAI/DL-Physics-Neural-Network
- https://wasp-sweden.org/
- Statistical Physics of Machine Learning
- statistical mechanics // machine learning
- A Theoretical Connection Between Statistical Physics and Reinforcement Learning
- The thermodynamics of learning
- WHY DOES DEEP LEARNING WORK?
- WHY DEEP LEARNING WORKS II: THE RENORMALIZATION GROUP
- https://github.com/CalculatedContent/ImplicitSelfRegularization
- torbenkruegermath
- TOWARDS A NEW THEORY OF LEARNING: STATISTICAL MECHANICS OF DEEP NEURAL NETWORKS
- Statistical Mechanics of Deep Learning
- https://zhuanlan.zhihu.com/p/90096775
Born machine is a Probabilistic Generative Modeling.
- Unsupervised Generative Modeling Using Matrix Product States
- https://wangleiphy.github.io/talks/BornMachine-USTC.pdf
- https://github.com/congzlwag/UnsupGenModbyMPS
- https://congzlwag.github.io/UnsupGenModbyMPS/
- https://github.com/congzlwag/BornMachineTomo
- From Baltzman machine to Born Machine
- Born Machines: A fresh approach to quantum machine learning
- Gradient based training of Quantum Circuit Born Machine (QCBM)
- Combining quantum information and machine learning
- machine learning for quantum technology/
- https://wangleiphy.github.io/
- https://tacocohen.wordpress.com
- https://peterwittek.com/qml-in-2015.html
- https://github.com/krishnakumarsekar/awesome-quantum-machine-learning
- https://peterwittek.com/
- Lecture Note on Deep Learning and Quantum Many-Body Computation
- Quantum Deep Learning and Renormalization
- https://scholar.harvard.edu/madvani/home
- https://www.elen.ucl.ac.be/esann/index.php?pg=specsess#statistical
- https://krzakala.github.io/cargese.io/program.html
- New Theory Cracks Open the Black Box of Deep Learning
- Unifying Physics and Deep Learning with TossingBot
- Linear Algebra and Learning from Data
- Accelerating deep neural networks with tensor decompositions
- An Algebraic Perspective on Deep Learning
- Tensor Networks in a Nutshell
- A library for easy and efficient manipulation of tensor networks.
- http://tensornetworktheory.org/
- https://www.perimeterinstitute.ca/research/research-initiatives/tensor-networks-initiative
- https://github.com/emstoudenmire/TNML
- http://itensor.org/
- http://users.cecs.anu.edu.au/~koniusz/
- https://deep-learning-tensorflow.readthedocs.io/en/latest/
- A Common Logic to Seeing Cats and Cosmos
- Neural Network Renormalization Group
- WHY DEEP LEARNING WORKS II: THE RENORMALIZATION GROUP
- https://guava.physics.uiuc.edu/~nigel/courses/563/Essays_2017/PDF/Luo.pdf
- https://rojefferson.blog/2019/08/04/deep-learning-and-the-renormalization-group/
- Dealings with Data Physics, Machine Learning and Geometry
- Meeting on Mathematics of Deep Learning
- Probability in high dimensions
- https://math.ethz.ch/sam/research/reports.html?year=2019
- Learning Deep Learning
- Summer school on Deep Learning Theory by Weinan E
- .520/6.860: Statistical Learning Theory and Applications, Fall 2018
- 2018上海交通大学深度学习理论前沿研讨会 - 凌泽南的文章 - 知乎
- Theories of Deep Learning
- https://orion.math.iastate.edu/hliu/MDL/
- https://deepmath-conference.com/
A mathematical theory of deep networks and of why they work as well as they do is now emerging. I will review some recent theoretical results on the approximation power of deep networks including conditions under which they can be exponentially better than shallow learning. A class of deep convolutional networks represent an important special case of these conditions, though weight sharing is not the main reason for their exponential advantage. I will also discuss another puzzle around deep networks: what guarantees that they generalize and they do not overfit despite the number of weights being larger than the number of training data and despite the absence of explicit regularization in the optimization?
Deep Neural Networks and Partial Differential Equations: Approximation Theory and Structural Properties Philipp Petersen, University of Oxford
- https://memento.epfl.ch/event/a-theoretical-analysis-of-machine-learning-and-par/
- http://at.yorku.ca/c/b/p/g/30.htm
- https://mat.univie.ac.at/~grohs/
- Deep Learning: Theory and Applications (Math 689 Fall 2018)
- Topics course Mathematics of Deep Learning, NYU, Spring 18
- https://skymind.ai/ebook/Skymind_The_Math_Behind_Neural_Networks.pdf
- https://github.com/markovmodel/deeptime
- https://omar-florez.github.io/scratch_mlp/
- https://joanbruna.github.io/MathsDL-spring19/
- https://github.com/isikdogan/deep_learning_tutorials
- https://www.brown.edu/research/projects/crunch/machine-learning-x-seminars
- Deep Learning: Theory & Practice
- https://www.math.ias.edu/wtdl
- https://www.ml.tu-berlin.de/menue/mitglieder/klaus-robert_mueller/
- https://www-m15.ma.tum.de/Allgemeines/MathFounNN
- https://www.math.purdue.edu/~buzzard/MA598-Spring2019/index.shtml
- http://mathematics-in-europe.eu/?p=801
- https://cims.nyu.edu/~bruna/
- https://www.math.ias.edu/wtdl
- https://www.pims.math.ca/scientific-event/190722-pcssdlcm
- Deep Learning for Image Analysis EMBL COURSE
- MATH 6380o. Deep Learning: Towards Deeper Understanding, Spring 2018
- Mathematics of Deep Learning, Courant Insititute, Spring 19
- http://voigtlaender.xyz/
- http://www.mit.edu/~9.520/fall19/
- The Mathematics of Deep Learning and Data Science - Programme
- Home of Math + Machine Learning + X
- Mathematical and Computational Aspects of Machine Learning
- Mathematical Theory for Deep Neural Networks
- Theory of Deep Learning
- DALI 2018 - Data, Learning and Inference
- BMS Summer School 2019: Mathematics of Deep Learning
- SIAM Conference on Mathematics of Data Science (MDS20)
- Taming the Curse of Dimensionality: Discrete Integration by Hashing and Optimization
- DATA SCIENCE MEETS OPTIMIZATION
- http://www.cas.mcmaster.ca/~deza/tokyo2018progr.html
- https://www.cs.cornell.edu/~bistra/
- Discrete Mathematics of Neural Networks: Selected Topics
- Deep Learning in Computational Discrete Optimization
- Deep Learning in Discrete Optimization
- https://web-app.usc.edu/soc/syllabus/20201/30126.pdf
- http://www.columbia.edu/~yf2414/Slides.pdf
- http://www.columbia.edu/~yf2414/teach.html
- https://opt-ml.org/cfp.html
- https://easychair.org/smart-program/CPAIOR2020/index.html
- http://www.joehuchette.com/
- Strong mixed-integer programming formulations for trained neural networks by Joey Huchette1
- Deep neural networks and mixed integer linear optimization
- Matteo Fischetti, University of Padova
- Deep Neural Networks as 0-1 Mixed Integer Linear Programs: A Feasibility Study
- https://www.researchgate.net/profile/Matteo_Fischetti
- A Mixed Integer Linear Programming Formulation to Artificial Neural Networks
- ReLU Networks as Surrogate Models in Mixed-Integer Linear Programs
Dynamics of deep learning is to consider deep learning as a dynamic system.
For example, the forward feedback network is expressed in the recurrent form:
However, it is not easy to select a proper nonlinear function
Many recursive formula share the same feedback forms or hidden structure, where the next input is the output of previous or historical record or generated points.
- 401-3650-19L Numerical Analysis Seminar: Mathematics of Deep Neural Network Approximation
- http://www.mathcs.emory.edu/~lruthot/talks/
- CS 584 / MATH 789R - Numerical Methods for Deep Learning
- Numerical methods for deep learning
- Short Course on Numerical Methods for Deep Learning
- MA 721: Topics in Numerical Analysis: Deep Learning
Deep Residual Networks won the 1st places in: ImageNet classification, ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.
It inspired more efficient forward convolutional networks.
They take a standard feed-forward ConvNet and add skip connections that bypass (or shortcut) a few convolution layers at a time. Each bypass gives rise to a residual block in which the convolution layers predict a residual that is added to the block’s input tensor.
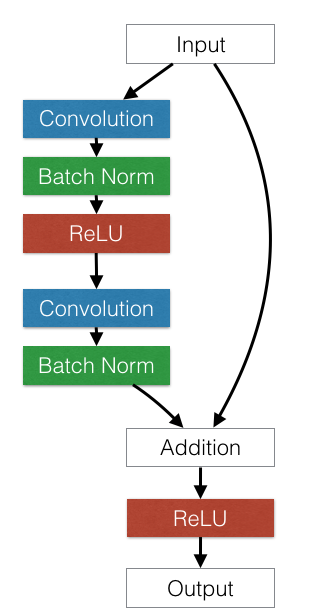
- https://github.com/KaimingHe/deep-residual-networks
- http://torch.ch/blog/2016/02/04/resnets.html
- https://zh.gluon.ai/chapter_convolutional-neural-networks/resnet.html
- https://www.jiqizhixin.com/articles/042201
- http://www.smartchair.org/hp/MSML2020/Paper/
- https://github.com/liuzhuang13/DenseNet
- https://arxiv.org/abs/1810.11741
- Depth with nonlinearity creates no bad local minima in ResNets
- LeanConvNets: Low-cost Yet Effective Convolutional Neural Networks
Reversible Residual Network
- The Reversible Residual Network: Backpropagation Without Storing Activations
- https://ai.googleblog.com/2020/01/reformer-efficient-transformer.html
- https://arxiv.org/abs/2001.04451
- https://ameroyer.github.io/reading-notes/architectures/2019/05/07/the_reversible_residual_network.html
- Layer-Parallel Training of Deep Residual Neural Networks
This section is on insight from numerical analysis to inspire more effective deep learning architecture.
- Path integral approach to random neural networks
- NEURAL NETWORKS AS ORDINARY DIFFERENTIAL EQUATIONS
- Dynamical aspects of Deep Learning
- Dynamical Systems and Deep Learning
- https://zhuanlan.zhihu.com/p/71747175
- https://web.stanford.edu/~yplu/project.html
- https://github.com/2prime/ODE-DL/
- Deep Neural Networks Motivated by Partial Differential Equations
Residual networks as discretizations of dynamic systems: $$ Y_1 = Y_0 +h \sigma(K_0 Y_0 + b_0)\ \vdots \ Y_N = Y_{N-1} +h \sigma(K_{N-1} Y_{N-1} + b_{N-1}) $$
This is nothing but a forward Euler discretization of the Ordinary Differential Equation (ODE):
The goal is to plan a path (via

Another idea is to ensure stability by design / constraints on
ResNet with antisymmetric transformation matrix:
Hamiltonian-like ResNet
Parabolic Residual Neural Networks
Hyperbolic Residual Neural Networks
Hamiltonian CNN
- Numerical methods for deep learning
- Short Course on Numerical Methods for Deep Learning
- Deep Neural Networks Motivated By Ordinary Differential Equations
- Continuous Models: Numerical Methods for Deep Learning
- Fully Hyperbolic Convolutional Neural Networks
- https://eldad-haber.webnode.com/selected-talks/
- http://www.mathcs.emory.edu/~lruthot/courses/NumDL/3-NumDNNshort-ContinuousModels.pdf

Numerical differential equation inspired networks:
- Bridging Deep Architects and Numerical Differential Equations
- BRIDGING DEEP NEURAL NETWORKS AND DIFFERENTIAL EQUATIONS FOR IMAGE ANALYSIS AND BEYOND
- Beyond Finite Layer Neural Networks: Bridging Deep Architectures and Numerical Differential Equations
- http://bicmr.pku.edu.cn/~dongbin/
- https://arxiv.org/pdf/1906.02762.pdf
- Neural ODE Paper List
- A Multiscale and Multidepth Convolutional Neural Network for Remote Sensing Imagery Pan-Sharpening
- https://arxiv.org/abs/1808.02376
- Multimodal and Multiscale Deep Neural Networks for the Early Diagnosis of Alzheimer’s Disease using structural MR and FDG-PET images
MgNet
- MgNet: A Unified Framework of Multigrid and Convolutional Neural Network
- http://www.multigrid.org/img2019/img2019/Index/shortcourse.html
- https://deepai.org/machine-learning/researcher/jinchao-xu
- MA 721: Topics in Numerical Analysis: Deep Learning
- http://www.mathcs.emory.edu/~lruthot/teaching.html
- https://www.math.ucla.edu/applied/cam
- http://www.mathcs.emory.edu/~lruthot/
- Automatic Differentiation of Parallelised Convolutional Neural Networks - Lessons from Adjoint PDE Solvers
- A Theoretical Analysis of Deep Neural Networks and Parametric PDEs.
- https://raoyongming.github.io/
- https://sites.google.com/prod/view/haizhaoyang/
- https://github.com/HaizhaoYang
- https://www.stat.uchicago.edu/events/rtg/index.shtml
Supervised Deep Learning Problem Given training data,
$Y_0$ , and labels,$C$ , find network parameters$\theta$ and classification weights$W, \mu$ such that the DNN predicts the data-label relationship (and generalizes to new data), i.e., solve$$\operatorname{minimize}_{ \theta,W,\mu} loss[g(W, \mu), C] + regularizer[\theta,W,\mu]$$
This can rewrite in a compact form
- Deep Learning Theory Review: An Optimal Control and Dynamical Systems Perspective
- An Optimal Control Approach to Deep Learning and Applications to Discrete-Weight Neural Networks
- Dynamic System and Optimal Control Perspective of Deep Learning
- A Flexible Optimal Control Framework for Efficient Training of Deep Neural Networks
- Deep learning as optimal control problems: models and numerical methods
- A Mean-Field Optimal Control Formulation of Deep Learning
- Control Theory and Machine Learning
- Advancing Systems and Control Research in the Era of ML and AI
- http://marcogallieri.micso.it/Home.html
- Deep Learning meets Control Theory: Research at NNAISENSE and Polimi
- Machine Learning-based Control
- CAREER: A Flexible Optimal Control Framework for Efficient Training of Deep Neural Networks
- https://www.zhihu.com/question/315809187/answer/623687046
- https://www4.comp.polyu.edu.hk/~cslzhang/paper/CVPR19-FOCNet.pdf
Neural ODE

- NeuPDE: Neural Network Based Ordinary and Partial Differential Equations for Modeling Time-Dependent Data
- Neural Ordinary Differential Equations and Adversarial Attacks
- Neural Dynamics and Computation Lab
- NeuPDE: Neural Network Based Ordinary and Partial Differential Equations for Modeling Time-Dependent Data
- https://math.ethz.ch/sam/research/reports.html?year=2019
- http://roseyu.com/
- A Proposal on Machine Learning via Dynamical Systems
- http://www.scholarpedia.org/article/Attractor_network
- An Empirical Exploration of Recurrent Network Architectures
- An Attractor-Based Complexity Measurement for Boolean Recurrent Neural Networks
- Deep learning for universal linear embeddings of nonlinear dynamics
- Exact solutions to the nonlinear dynamics of learning in deep linear neural networks
- Continuous attractors of higher-order recurrent neural networks with infinite neurons
- https://www.researchgate.net/profile/Jiali_Yu3
- Markov Transitions between Attractor States in a Recurrent Neural Network
- A Survey on Machine Learning Applied to Dynamic Physical Systems
- https://deepdrive.berkeley.edu/project/dynamical-view-machine-learning-systems
- https://folk.uio.no/vegarant/
- https://www.mn.uio.no/math/english/people/aca/vegarant/index.html
- https://arxiv.org/pdf/1710.11029.pdf
- http://www.vision.jhu.edu/tutorials/ICCV15-Tutorial-Math-Deep-Learning-Raja.pdf
- https://arxiv.org/abs/1705.03341
- https://izmailovpavel.github.io/
- https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Zheng_Improving_the_Robustness_CVPR_2016_paper.pdf
This section is on how to use deep learning or more general machine learning to solve differential equation numerically.
We derive upper bounds on the complexity of ReLU neural networks approximating the solution maps of parametric partial differential equations. In particular, without any knowledge of its concrete shape, we use the inherent low-dimensionality of the solution manifold to obtain approximation rates which are significantly superior to those provided by classical approximation results. We use this low dimensionality to guarantee the existence of a reduced basis. Then, for a large variety of parametric partial differential equations, we construct neural networks that yield approximations of the parametric maps not suffering from a curse of dimension and essentially only depending on the size of the reduced basis.
- https://math.ethz.ch/sam/research/reports.html?year=2019
- https://aimath.org/workshops/upcoming/deeppde/
- https://github.com/IBM/pde-deep-learning
- https://arxiv.org/abs/1804.04272
- https://deepai.org/machine-learning/researcher/weinan-e
- https://deepxde.readthedocs.io/en/latest/
- https://github.com/IBM/pde-deep-learning
- https://github.com/ZichaoLong/PDE-Net
- https://github.com/amkatrutsa/DeepPDE
- https://github.com/maziarraissi/DeepHPMs
- https://github.com/markovmodel/deeptime
- https://torchdyn.readthedocs.io/en/latest/index.html
- Deep Hidden Physics Models: Deep Learning of Nonlinear Partial Differential Equations
- SPNets: Differentiable Fluid Dynamics for Deep Neural Networks
- https://maziarraissi.github.io/DeepHPMs/
- A Theoretical Analysis of Deep Neural Networks and Parametric PDEs
- Deep Approximation via Deep Learning
- Diffeq 202020
- https://openreview.net/group?id=ICLR.cc/2020/Workshop/DeepDiffEq#accept-poster
- https://mcallester.github.io/ttic-31230/Fall2020/
- The Deep Ritz Method: A Deep Learning-Based Numerical Algorithm for Solving Variational Problems
- Solving Nonlinear and High-Dimensional Partial Differential Equations via Deep Learning
- DGM: A deep learning algorithm for solving partial differential equations
- NeuralNetDiffEq.jl: A Neural Network solver for ODEs
- PIMS CRG Summer School: Deep Learning for Computational Mathematics
- https://arxiv.org/abs/1806.07366
- https://mat.univie.ac.at/~grohs/
- https://rse-lab.cs.washington.edu/
- http://www.ajentzen.de/
- https://web.math.princeton.edu/~jiequnh/
- A multiscale neural network based on hierarchical matrices
- A multiscale neural network based on hierarchical nested bases
- https://www.researchgate.net/profile/Gitta_Kutyniok
- https://www.researchgate.net/project/Mathematical-Theory-for-Deep-Neural-Networks
- https://www.academia-net.org/profil/prof-dr-gitta-kutyniok/1133890
- https://www.tu-berlin.de/index.php?id=168945
- https://www.math.tu-berlin.de/?108957
- Deep Learning: An Introduction for Applied Mathematicians
- Neural Jump SDEs (Jump Diffusions) and Neural PDEs
- Deep-Learning Based Numerical BSDE Method for Barrier Options
- Machine learning approximation algorithms for high-dimensional fully nonlinear partial differential equations and second-order backward stochastic differential equations
- http://www.multigrid.org/index.php?id=13
- http://casopisi.junis.ni.ac.rs/index.php/FUMechEng/article/view/309
- http://people.math.sc.edu/imi/DASIV/
- Deep ReLU Networks and High-Order Finite Element Methods
- https://math.psu.edu/events/35992
- Neural network for constitutive modelling in finite element analysis
- https://arxiv.org/abs/1807.03973
- A deep learning approach to estimate stress distribution: a fast and accurate surrogate of finite-element analysis
- An Integrated Machine Learning and Finite Element Analysis Framework, Applied to Composite Substructures including Damage
- https://github.com/oleksiyskononenko/mlfem
- https://people.math.gatech.edu/~wliao60/
- https://www.math.tu-berlin.de/fileadmin/i26_fg-kutyniok/Kutyniok/Papers/main.pdf
Universal approximation theory show the expression power of deep neural network of some wide while shallow neural network. The section will extend the approximation to the deep neural network.
- Deep Neural Network Approximation Theory
- Approximation Analysis of Convolutional Neural Networks
- Deep vs. shallow networks : An approximation theory perspective
- Deep Neural Network Approximation Theory
- Provable approximation properties for deep neural networks
- Optimal Approximation with Sparsely Connected Deep Neural Networks
- Deep Learning: Approximation of Functions by Composition
- Deep Neural Networks: Approximation Theory and Compositionality
- DNN Bonn
- From approximation theory to machine learning
- Collapse of Deep and Narrow Neural Nets
- Nonlinear Approximation and (Deep) ReLU Networks
- Deep Approximation via Deep Learning
- Convolutional Neural Networks for Steady Flow Approximation
- https://www.eurandom.tue.nl/wp-content/uploads/2018/11/Johannes-Schmidt-Hieber-lecture-1-2.pdf
- https://arxiv.org/abs/2006.00294
- Efficient approximation of high-dimensional functions with deep neural networks
Understanding the training process of Deep Neural Networks (DNNs) is a fundamental problem in the area of deep learning. The study of the training process from the frequency perspective makes important progress in understanding the strength and weakness of DNN, such as generalization and converging speed etc., which may consist in “a reasonably complete picture about the main reasons behind the success of modern machine learning” (E et al., 2019).
The “Frequency Principle” was first named in the paper (Xu et al., 2018), then (Xu 2018; Xu et al., 2019) use more convincing experiments and a simple theory to demonstrate the university of the Frequency Principle. Bengio's paper (Rahaman et al., 2019) also uses the the simple theory in (Xu 2018; Xu et al., 2019) to understand the mechanism underlying the Frequency Principle for ReLU activation function. Note that the second version of Rahaman et al., (2019) points out this citation clearly but they reorganize this citation to “related works” in the final version. Later, Luo et al., (2019) studies the Frequency Principle in the general setting of deep neural networks and mathematically proves Frequency Principle with the assumption of infinite samples. Zhang et al., (2019) study the Frequency Principle in the NTK regime with finite sample points. Zhang et al., (2019) explicitly shows that the converging speed for each frequency and can accurately predict the learning results.
- Deep learning in Fourier domain
- Deep Learning Theory: The F-Principle and An Optimization Framework
- Frequency Principle: Fourier Analysis Sheds Light on Deep Neural Networks
- Nonlinear Collaborative Scheme for Deep Neural Networks
- The Convergence Rate of Neural Networks for Learned Functions of Different Frequencies
- Frequency Principle in Deep Learning with General Loss Functions and Its Potential Application
- Theory of the Frequency Principle for General Deep Neural Networks
- Explicitizing an Implicit Bias of the Frequency Principle in Two-layer Neural Networks
- https://www.researchgate.net/profile/Zhiqin_Xu
- https://github.com/xuzhiqin1990/F-Principle
- http://proceedings.mlr.press/v80/balestriero18b/balestriero18b.pdf
- http://proceedings.mlr.press/v80/balestriero18a/balestriero18a.pdf
- http://rb42.web.rice.edu/
- https://github.com/RandallBalestriero
- https://www.nsf.gov/awardsearch/showAward?AWD_ID=1838177&HistoricalAwards=false
- A Max-Affine Spline Perspective of Recurrent Neural Networks (RNNs)
- https://zw16.web.rice.edu/
- https://www.mfo.de/occasion/1842b
- https://www.mfo.de/occasion/1947a
- https://github.com/juliusberner/oberwolfach_workshop
- DGD Approximation Theory Workshop
- https://deepai.org/profile/julius-berner
- https://www.cityu.edu.hk/ma/people/profile/zhoudx.htm
- https://dblp.uni-trier.de/pers/hd/y/Yang:Haizhao
- https://math.duke.edu/people/ingrid-daubechies
- http://www.pc-petersen.eu/
- https://wwwhome.ewi.utwente.nl/~schmidtaj/
- https://personal-homepages.mis.mpg.de/montufar/
- https://www.math.tamu.edu/~foucart/
- http://www.damtp.cam.ac.uk/user/sl767/#about
- http://voigtlaender.xyz/publications.html- https://ins.sjtu.edu.cn/people/xuzhiqin/
Today, the best performing approaches for the aforementioned image reconstruction and sensing problems are based on deep learning, which learn various elements of the method including i) signal representations, ii) stepsizes and parameters of iterative algorithms, iii) regularizers, and iv) entire inverse functions. For example, it has recently been shown that solving a variety of inverse problems by transforming an iterative, physics-based algorithm into a deep network whose parameters can be learned from training data, offers faster convergence and/or a better quality solution. Moreover, even with very little or no learning, deep neural networks enable superior performance for classical linear inverse problems such as denoising and compressive sensing. Motivated by those success stories, researchers are redesigning traditional imaging and sensing systems.
- Sixteenth International Conference on the Integration of Constraint Programming, Artificial Intelligence, and Operations Research
- https://github.com/mughanibu/Deep-Learning-for-Inverse-Problems
- Accurate Image Super-Resolution Using Very Deep Convolutional Networks
- https://eiffl.github.io/talks/KMI2020/index.html
- https://earthscience.rice.edu/mathx2019/
- https://www.researchgate.net/publication/329395098_On_Deep_Learning_for_Inverse_Problems
- Deep Learning and Inverse Problem
- https://www.scec.org/publication/8768
- https://amds123.github.io/
- https://github.com/IPAIopen
- https://imaginary.org/snapshot/deep-learning-and-inverse-problems
- https://www.researchgate.net/scientific-contributions/2150388821_Jaweria_Amjad
- https://zif.ai/inverse-reinforcement-learning/
- Physics Based Machine Learning for Inverse Problems
- https://www.ece.nus.edu.sg/stfpage/elechenx/Papers/TGRS_Learning.pdf
Learning-based methods, and in particular deep neural networks, have emerged as highly successful and universal tools for image and signal recovery and restoration. They achieve state-of-the-art results on tasks ranging from image denoising, image compression, and image reconstruction from few and noisy measurements. They are starting to be used in important imaging technologies, for example in GEs newest computational tomography scanners and in the newest generation of the iPhone.
The field has a range of theoretical and practical questions that remain unanswered. In particular, learning and neural network-based approaches often lack the guarantees of traditional physics-based methods. Further, while superior on average, learning-based methods can make drastic reconstruction errors, such as hallucinating a tumor in an MRI reconstruction or turning a pixelated picture of Obama into a white male.
- Deep Learning for Inverse Problems
- Solving inverse problems with deep networks
- Neumann Networks for Inverse Problems in Imaging
- Deep Decomposition Learning for Inverse Imaging Problems
- Model Meets Deep Learning in Image Inverse Problems
- https://deepai.org/publication/unsupervised-deep-learning-algorithm-for-pde-based-forward-and-inverse-problems
- https://www.aapm.org/GrandChallenge/DL-sparse-view-CT/
- https://github.com/jiupinjia/GANs-for-Inverse-Problems
- https://eiffl.github.io/talks/KMI2020/index.html
- https://onlinelibrary.wiley.com/doi/epdf/10.1002/qua.26599
- Deep neural networks learning to solve nonlinear inverse problems for the wave equation
- deep inverse optimization
- https://ori.ox.ac.uk/deep-irl/
- Attacking inverse problems with deep learning
- Workshop: Learning Meets Combinatorial Algorithms
- https://data102.org/fa20/
- https://ieeexplore.ieee.org/document/8434321
- https://sites.google.com/site/sercmig/manish-bhatt_-phd-thesis-work
Random matrix focus on the matrix, whose entities are sampled from some specific probability distribution. Weight matrices in deep neural network are initialed in random. However, the model is over-parameterized and it is hard to verify the role of one individual parameter.
- http://romaincouillet.hebfree.org/
- https://zhenyu-liao.github.io/
- https://dionisos.wp.imt.fr/
- https://project.inria.fr/paiss/
- https://zhenyu-liao.github.io/activities/
- Implicit Self-Regularization in Deep Neural Networks: Evidence from Random Matrix Theory and Implications for Learning
- Recent Advances in Random Matrix Theory for Modern Machine Learning
- Features extraction using random matrix theory
- Nonlinear random matrix theory for deep learning
- A RANDOM MATRIX APPROACH TO NEURAL NETWORKS
- A Random Matrix Approach to Echo-State Neural Networks
- Harnessing neural networks: A random matrix approach
- Tensor Programs: A Swiss-Army Knife for Nonlinear Random Matrix Theory of Deep Learning and Beyond
- Scaling Limits of Wide Neural Networks with Weight Sharing: Gaussian Process Behavior, Gradient Independence, and Neural Tangent Kernel Derivation
- Random Matrix Theory and its Innovative Applications∗
- https://romaincouillet.hebfree.org/docs/conf/ELM_icassp.pdf
- https://romaincouillet.hebfree.org/docs/conf/NN_ICML.pdf
- http://www.vision.jhu.edu/tutorials/CVPR16-Tutorial-Math-Deep-Learning-Raja.pdf
- A Random Matrix Framework for BigData Machine Learning
- https://ai.google/research/pubs/pub46342
- http://people.cs.uchicago.edu/~pworah/nonlinear_rmt.pdf
- A SWISS-ARMY KNIFE FOR NONLINEAR RANDOM MATRIX THEORY OF DEEP LEARNING AND BEYOND
- https://simons.berkeley.edu/talks/9-24-mahoney-deep-learning
- https://cs.stanford.edu/people/mmahoney/
- https://www.stat.berkeley.edu/~mmahoney/f13-stat260-cs294/
- https://arxiv.org/abs/1902.04760
- https://melaseddik.github.io/
- https://thayafluss.github.io/
Optimal transport (OT) provides a powerful and flexible way to compare probability measures, of all shapes: absolutely continuous, degenerate, or discrete. This includes of course point clouds, histograms of features, and more generally datasets, parametric densities or generative models. Originally proposed by Monge in the eighteenth century, this theory later led to Nobel Prizes for Koopmans and Kantorovich as well as Villani’s Fields Medal in 2010.
- Optimal Transport & Machine Learning
- Topics on Optimal Transport in Machine Learning and Shape Analysis (OT.ML.SA)
- https://www-obelix.irisa.fr/files/2017/01/postdoc-Obelix.pdf
- http://www.cis.jhu.edu/~rvidal/talks/learning/StructuredFactorizations.pdf
- https://mc.ai/optimal-transport-theory-the-new-math-for-deep-learning/
- https://www.louisbachelier.org/wp-content/uploads/2017/07/170620-ilb-presentation-gabriel-peyre.pdf
- http://people.csail.mit.edu/davidam/
- https://www.birs.ca/events/2020/5-day-workshops/20w5126
- https://github.com/hindupuravinash/nips2017
- Selection dynamics for deep neural networks
- https://people.math.osu.edu/memolitechera.1/index.html
- Optimal Transport Theory the New Math for Deep Learning
- https://www.researchgate.net/publication/317378242_GAN_and_VAE_from_an_Optimal_Transport_Point_of_View
- https://arxiv.org/abs/1710.05488
- http://www.dataguru.cn/article-14562-1.html
- http://cmsa.fas.harvard.edu/wp-content/uploads/2018/06/David_Gu_Harvard.pdf
- http://www.dataguru.cn/article-14563-1.html
- http://games-cn.org/games-webinar-20190509-93/
- https://www3.cs.stonybrook.edu/~gu/
Why and how that deep learning works well on different tasks remains a mystery from a theoretical perspective. In this paper we draw a geometric picture of the deep learning system by finding its analogies with two existing geometric structures, the geometry of quantum computations and the geometry of the diffeomorphic template matching. In this framework, we give the geometric structures of different deep learning systems including convolutional neural networks, residual networks, recursive neural networks, recurrent neural networks and the equilibrium prapagation framework. We can also analysis the relationship between the geometrical structures and their performance of different networks in an algorithmic level so that the geometric framework may guide the design of the structures and algorithms of deep learning systems.
- Machine Learning on Geometrical Data CSE291-C00 - Winter 2019
- Geometric Analysis Approach to AI Workshop
- ABC Dataset A Big CAD Model Dataset For Geometric Deep Learning
- Into the Wild: Machine Learning In Non-Euclidean Spaces
- How deep learning works — The geometry of deep learning
- http://cmsa.fas.harvard.edu/geometric-analysis-ai/
- http://inspirehep.net/record/1697651
- https://diglib.eg.org/handle/10.2312/2631996
- http://ubee.enseeiht.fr/skelneton/
- https://biomedicalimaging.org/2019/tutorials/
- Geometric View to Deep Learning
- GEOMETRIC IDEAS IN MACHINE LEARNING: FROM DEEP LEARNING TO INCREMENTAL OPTIMIZATION
- Deep Learning Theory: Geometric Analysis of Capacity, Optimization, and Generalization for Improving Learning in Deep Neural Networks
- Workshop IV: Deep Geometric Learning of Big Data and Applications
- Robustness and geometry of deep neural networks
- A geometric view of optimal transportation and generative model
- GeoNet: Deep Geodesic Networks for Point Cloud Analysis
- http://www.stat.uchicago.edu/~lekheng/
- https://web.mat.upc.edu/sebastia.xambo/ICIAM2019/GC&DL.html
- https://www.nsf.gov/awardsearch/showAward?AWD_ID=1418255
- https://nsf-tripods.org/institutes/
- https://users.math.msu.edu/users/wei/
- https://www.darpa.mil/program/hierarchical-identify-verify-exploit
- https://deepai.org/profile/randall-balestriero
- https://github.com/digantamisra98/Library
- http://www.tianranchen.org/research/papers/deep-linear.pdf
- The Loss Surfaces of Multilayer Networks
- The Loss Surface Of Deep Linear Networks Viewed Through The Algebraic Geometry Lens
- The Loss Surface of Deep and Wide Neural Networks
- Visualizing the Loss Landscape of Neural Nets
- Understanding the Loss Surface of Neural Networks for Binary Classification
- Optimization Landscape and Expressivity of Deep CNNs
- On the Flatness of Loss Surface for Two-layered ReLU Networks
- https://www.cs.umd.edu/~tomg/projects/landscapes/
- Deep Learning without Poor Local Minima
- https://chulheey.mit.edu/wp-content/uploads/sites/12/2017/12/yun2017global_nips2017workshop.pdf
The basic idea of tropical geometry is to study the same kinds of questions as in standard algebraic geometry, but change what we mean when we talk about ‘polynomial equations’.
- Tropical Geometry of Deep Neural Networks
- https://opendatagroup.github.io/data%20science/2019/04/11/tropical-geometry.html
- https://www.stat.uchicago.edu/~lekheng/
- https://mathsites.unibe.ch/siamag19/
- https://www.math.ubc.ca/~erobeva/seminar.html
- https://sites.google.com/view/maag2019/home
- https://sites.google.com/site/feliper84/
- https://deepai.org/publication/a-tropical-approach-to-neural-networks-with-piecewise-linear-activations
- ReLu and Maxout Networks and Their Possible Connections to Tropical Methods
- Applications of Tropical Geometry in Deep Neural Networks
We perform topological data analysis
on the internal states of convolutional deep neural networks to develop an understanding of the computations
that they perform. We apply this understanding to modify the computations so as to (a) speed up computations and (b) improve generalization
from one data set of digits to another.
One byproduct of the analysis is the production of a geometry on new sets of features on data sets of images,
and use this observation to develop a methodology for constructing analogues of CNN's for many other geometries,
including the graph structures constructed by topological data analysis.
- https://keuperj.github.io/DeToL/
- Topological Methods for Machine Learning
- Topological Approaches to Deep Learning
- Topological Data Analysis and Beyond
- https://www.gaotingran.com/
- Topology based deep learning for biomolecular data
- RESEARCH ARTICLE TopologyNet: Topology based deep convolutional and multi-task neural networks for biomolecular property predictions
- Exposition and Interpretation of the Topology of Neural Networks
- https://zhuanlan.zhihu.com/p/26515275
- Towards a topological–geometrical theory of group equivariant non-expansive operators for data analysis and machine learning
- https://github.com/FatemehTarashi/awesome-tda
- Graph Machine Learning using 3D Topological Models
- A Stable Multi-Scale Kernel for Topological Machine Learning
- https://github.com/Chen-Cai-OSU/Topology-and-Learning
- Topology Optimization based Graph Convolutional Network
- https://www.birs.ca/workshops/2012/12w5081/report12w5081.pdf
- http://cunygc.appliedtopology.nyc/
- https://www.sthu.org/research/topmachinelearning/
- https://arxiv.org/abs/2003.04584
- Multiparameter Persistence Images for Topological Machine Learning
- Topological Data Analysis
- Understanding Bias in Datasets using Topological Data Analysis
- Optimal Transport, Topological Data Analysis and Applications to Shape and Machine Learning
- https://tgda.osu.edu/ot-tda-workshop/
- Topology and Machine Learning
- A Topology Layer for Machine Learning
- giotto-tda: A Topological Data Analysis Toolkit for Machine Learning and Data Exploration
- A Stable Multi-Scale Kernel for Topological Machine Learning
- Topological Machine Learning for Multivariate Time Series
- https://sites.google.com/site/nips2012topology/
- Persistence Images: A Stable Vector Representation of Persistent Homology
- Topological data analysis of zebrafish patterns
- https://elib.dlr.de/128105/1/MIMA_IGRASS_2019.pdf
- Using topological data analysis for diagnosis pulmonary embolism
- Persistence Bag-of-Words for Topological Data Analysis
- A Deep Learning Design for improving Topology Coherence in Blood Vessel Segmentation
- https://www.dbs.ifi.lmu.de/~tresp/
- A Novel Topology Optimization Approach using Conditional Deep Learning
- A deep Convolutional Neural Network for topology optimization with strong generalization ability
- https://www.researchgate.net/publication/322568237_Deep_learning_for_determining_a_near-optimal_topological_design_without_any_iteration
- Topology Optimization Accelerated by Deep Learning
- Topological Data Analysis Based Approaches to Deep Learning
- Topological Measurement of Deep Neural Networks Using Persistent Homology
- https://isaim2020.cs.ou.edu/
- https://graphnav.stanford.edu/
- Applying Topological Persistence in Convolutional Neural Network for Music Audio Signals
Topological Layer is used to extract the feature via topological data analysis.
- Deep Learning with Topological Signatures
- http://machinelearning.math.rs/Jekic-TDA.pdf
- Feature Extraction Using Topological Data Analysis for Machine Learning and Network Science Applications
- Mixing Topology and Deep Learning with PersLay
- https://arxiv.org/pdf/1904.09378.pdf
- https://github.com/bruel-gabrielsson/TopologyLayer
- A Topology Layer for Machine Learning
- Improved Image Classification using Topological Persistence
- https://arxiv.org/abs/2102.07835
- Topology Optimization based Graph Convolutional Network
- Persistence Enhanced Graph Neural Network
- https://www.ijcai.org/Proceedings/2019/0550.pdf
- Recent Advances in Topology-Based Graph Classification
- https://arxiv.org/abs/1911.06892
- A Persistent Weisfeiler–Lehman Procedure for Graph Classification
- A General Neural Network Architecture for Persistence Diagrams and Graph Classification
- http://homepages.cs.ncl.ac.uk/stephen.mcgough/CV/Papers/2016/GFPX2-slides.pdf
- https://ieeexplore.ieee.org/document/7840988
- https://bastian.rieck.me/talks/AMLD2020_Slides.pdf
- Topological based classification of paper domains using graph convolutional networks
Except the matrix and tensor decomposotion for accelerating the deep neural network, Tensor network is close to deep learning model.
- https://github.com/tscohen/gconv_experiments
- http://dalimeeting.org/dali2019b/workshop-05-02.html
- https://erikbekkers.bitbucket.io/
- https://staff.fnwi.uva.nl/m.welling/
- https://www.ics.uci.edu/~welling/
- http://ibis.t.u-tokyo.ac.jp/suzuki/
- http://www.mit.edu/~kawaguch/
- https://www.4tu.nl/ami/en/Agenda-Events/
Aizenberg, Ivaskiv, Pospelov and Hudiakov (1971) (former Soviet Union) proposed a complex-valued neuron model for the first time, and although it was only available in Russian literature, their work can now be read in English (Aizenberg, Aizenberg & Vandewalle, 2000). Prior to that time, most researchers other than Russians had assumed that the first persons to propose a complex-valued neuron were Widrow, McCool and Ball (1975). Interest in the field of neural networks started to grow around 1990, and various types of complex-valued neural network models were subsequently proposed. Since then, their characteristics have been researched, making it possible to solve some problems which could not be solved with the real-valued neuron, and to solve many complicated problems more simply and efficiently.
- http://what-when-how.com/artificial-intelligence/complex-valued-neural-networks-artificial-intelligence/
- The 10th International Conference on Complex Networks and their Applications
The complex-valued Neural Network is an extension of a (usual) real-valued neural network, whose input and output signals and parameters such as weights and thresholds are all complex numbers (the activation function is inevitably a complex-valued function).
- https://staff.aist.go.jp/tohru-nitta/HNN.html
- https://staff.aist.go.jp/tohru-nitta/CNN.html
- https://github.com/ChihebTrabelsi/deep_complex_networks
- https://r2rt.com/beyond-binary-ternary-and-one-hot-neurons.html
- https://www.elen.ucl.ac.be/Proceedings/esann/esannpdf/es2011-42.pdf
- https://www.microsoft.com/en-us/research/uploads/prod/2018/04/Deep-Complex-Networks.pdf
- https://core.ac.uk/reader/41356536
It looks like Deep (Convolutional) Neural Networks are really powerful. However, there are situations where they don’t deliver as expected. I assume that perhaps many are happy with pre-trained VGG, Resnet, YOLO, SqueezeNext, MobileNet, etc. models because they are “good enough”, even though they break quite easily on really realistic problems and require tons of training data. IMHO there are much smarter approaches out there, which are neglected/ignored. I don’t want to argue why they are ignored but I want to provide a list with other useful architectures.
Instead of staying with real numbers, we should have a look at complex numbers as well.
Let’s remember the single reason why we use complex numbers (
- https://arxiv.org/abs/1903.08478
- Introduction to Quaternion Neural Networks
- Capsule Networks and other neural architectures that are less known
- https://github.com/Orkis-Research/Quaternion-Convolutional-Neural-Networks-for-End-to-End-Automatic-Speech-Recognition
- Probabilistic Framework for Deep Learning
- A Probabilistic Theory of Deep Learning
- A Probabilistic Framework for Deep Learning
- Deep Probabilistic Programming
- https://github.com/oxmlcs/ML_bazaar/wiki/Deep-Learning-and-Probabilistic-Inference
- https://eng.uber.com/pyro/
- Probabilistic Deep Learning with Python
- https://livebook.manning.com/book/probabilistic-deep-learning/
- http://csml.stats.ox.ac.uk/
- https://fcai.fi/agile-probabilistic
- http://bayesiandeeplearning.org/2017/papers/59.pdf
- GluonTS: Probabilistic Time Series Models in Python
- CS 731: Advanced methods in artificial intelligence, with biomedical applications (Fall 2009)
- CS 838 (Spring 2004): Statistical Relational Learning
- https://www.ida.liu.se/~ulfni53/lpp/bok/bok.pdf
- https://www.biostat.wisc.edu/bmi576/
- http://www.cs.ox.ac.uk/people/yarin.gal/website/blog_2248.html
The abstract of Bayesian Deep learning put that:
While deep learning has been revolutionary for machine learning, most modern deep learning models cannot represent their uncertainty nor take advantage of the well studied tools of probability theory. This has started to change following recent developments of tools and techniques combining Bayesian approaches with deep learning. The intersection of the two fields has received great interest from the community over the past few years, with the introduction of new deep learning models that take advantage of Bayesian techniques, as well as Bayesian models that incorporate deep learning elements [1-11]. In fact, the use of Bayesian techniques in deep learning can be traced back to the 1990s’, in seminal works by Radford Neal [12], David MacKay [13], and Dayan et al. [14]. These gave us tools to reason about deep models’ confidence, and achieved state-of-the-art performance on many tasks. However earlier tools did not adapt when new needs arose (such as scalability to big data), and were consequently forgotten. Such ideas are now being revisited in light of new advances in the field, yielding many exciting new results Extending on last year’s workshop’s success, this workshop will again study the advantages and disadvantages of such ideas, and will be a platform to host the recent flourish of ideas using Bayesian approaches in deep learning and using deep learning tools in Bayesian modelling. The program includes a mix of invited talks, contributed talks, and contributed posters. It will be composed of five themes: deep generative models, variational inference using neural network recognition models, practical approximate inference techniques in Bayesian neural networks, applications of Bayesian neural networks, and information theory in deep learning. Future directions for the field will be debated in a panel discussion. This year’s main theme will focus on applications of Bayesian deep learning within machine learning and outside of it.
- Kingma, DP and Welling, M, "Auto-encoding variational Bayes", 2013.
- Rezende, D, Mohamed, S, and Wierstra, D, "Stochastic backpropagation and approximate inference in deep generative models", 2014.
- Blundell, C, Cornebise, J, Kavukcuoglu, K, and Wierstra, D, "Weight uncertainty in neural network", 2015.
- Hernandez-Lobato, JM and Adams, R, "Probabilistic backpropagation for scalable learning of Bayesian neural networks", 2015.
- Gal, Y and Ghahramani, Z, "Dropout as a Bayesian approximation: Representing model uncertainty in deep learning", 2015.
- Gal, Y and Ghahramani, G, "Bayesian convolutional neural networks with Bernoulli approximate variational inference", 2015.
- Kingma, D, Salimans, T, and Welling, M. "Variational dropout and the local reparameterization trick", 2015.
- Balan, AK, Rathod, V, Murphy, KP, and Welling, M, "Bayesian dark knowledge", 2015.
- Louizos, C and Welling, M, “Structured and Efficient Variational Deep Learning with Matrix Gaussian Posteriors”, 2016.
- Lawrence, ND and Quinonero-Candela, J, “Local distance preservation in the GP-LVM through back constraints”, 2006.
- Tran, D, Ranganath, R, and Blei, DM, “Variational Gaussian Process”, 2015.
- Neal, R, "Bayesian Learning for Neural Networks", 1996.
- MacKay, D, "A practical Bayesian framework for backpropagation networks", 1992.
- Dayan, P, Hinton, G, Neal, R, and Zemel, S, "The Helmholtz machine", 1995.
- Wilson, AG, Hu, Z, Salakhutdinov, R, and Xing, EP, “Deep Kernel Learning”, 2016.
- Saatchi, Y and Wilson, AG, “Bayesian GAN”, 2017.
- MacKay, D.J.C. “Bayesian Methods for Adaptive Models”, PhD thesis, 1992.
- Towards Bayesian Deep Learning: A Framework and Some Existing Methods
- http://www.wanghao.in/mis.html
- https://github.com/junlulocky/bayesian-deep-learning-notes
- https://github.com/robi56/awesome-bayesian-deep-learning
- https://alexgkendall.com/computer_vision/phd_thesis/
- http://bayesiandeeplearning.org/
- https://ericmjl.github.io/bayesian-deep-learning-demystified/
- http://www.cs.ox.ac.uk/people/yarin.gal/website/blog.html
- http://twiecki.github.io/blog/2016/06/01/bayesian-deep-learning/
- https://uvadlc.github.io/lectures/apr2019/lecture9-bayesiandeeplearning.pdf
- Self-supervised Bayesian Deep Learning for Image Recovery with Applications to Compressive Sensing
Mathematician Ivakhnenko and associates including Lapa arguably created the first working deep learning networks in 1965, applying what had been only theories and ideas up to that point.
Ivakhnenko developed the Group Method of Data Handling (GMDH) – defined as a “family of inductive algorithms for computer-based mathematical modeling of multi-parametric datasets that features fully automatic structural and parametric optimization of models” – and applied it to neural networks.
For that reason alone, many consider Ivakhnenko the father of modern deep learning.
His learning algorithms used deep feedforward multilayer perceptrons using statistical methods at each layer to find the best features and forward them through the system.
Using GMDH, Ivakhnenko was able to create an 8-layer deep network in 1971, and he successfully demonstrated the learning process in a computer identification system called Alpha.
- https://zhuanlan.zhihu.com/p/36519666
- https://wwwhome.ewi.utwente.nl/~schmidtaj/
- http://csml.stats.ox.ac.uk/people/teh/
- http://www.sdlcv-workshop.com/
- https://gkunapuli.github.io/files/17rrbmILP-longslides.pdf
- https://arxiv.org/abs/1810.07132
- https://dashee87.github.io/
- http://lear.inrialpes.fr/workshop/osl2015/
- http://www.stats.ox.ac.uk/~teh/
- http://blog.shakirm.com/ml-series/a-statistical-view-of-deep-learning/
- http://blog.shakirm.com/wp-content/uploads/2015/07/SVDL.pdf
- https://www.ijcai.org/Proceedings/2019/0789.pdf
- http://www.stat.ucla.edu/~jxie/
- https://mifods.mit.edu/seminar.php
- https://johanneslederer.com/people/
- https://www.tsu.ge/data/file_db/faculty_zust_sabunebismetk/WEB%20updated%205.05.15-announcement.pdf
- On Statistical Thinking in Deep Learning: A Talk
- On Statistical Thinking in Deep Learning: A Blog Post
- Implementing Bayesian Inference with Neural Networks
Handling inherent uncertainty and exploiting compositional structure are fundamental to understanding and designing large-scale systems. Statistical relational learning builds on ideas from probability theory and statistics to address uncertainty while incorporating tools from logic, databases, and programming languages to represent structure. In Introduction to Statistical Relational Learning, leading researchers in this emerging area of machine learning describe current formalisms, models, and algorithms that enable effective and robust reasoning about richly structured systems and data.
- Statistical Relational AI Meets Deep Learning
- https://people.cs.kuleuven.be/~luc.deraedt/salvador.pdf
- http://www.starai.org/2020/
- https://homes.cs.washington.edu/~pedrod/cikm13.html
- https://www.cs.umd.edu/srl-book/
- https://gkunapuli.github.io/
- https://aifrenz.github.io/
- https://ipvs.informatik.uni-stuttgart.de/mlr/spp-wordpress/
- https://personal.utdallas.edu/~sriraam.natarajan/Courses/starai.html
- http://acai2018.unife.it/
- https://www.biostat.wisc.edu/~page/838.html
- http://www.nlpca.org/
- http://users.ics.aalto.fi/~juha/papers/Generalizations_NN_1995.pdf
- https://www.cs.cmu.edu/~mgormley/courses/10601-s17/slides/lecture18-pca.pdf
- http://www.vision.jhu.edu/teaching/learning/deeplearning19/assets/Baldi_Hornik-89.pdf
- https://www.cs.purdue.edu/homes/dgleich/projects/pca_neural_nets_website/
- https://rdrr.io/cran/caret/man/pcaNNet.html
- http://research.ics.aalto.fi/ica/book/
- https://www.esat.kuleuven.be/sista/lssvmlab/
- https://zhenyu-liao.github.io/pdf/journal/LSSVM-TSP.pdf
- https://sci2s.ugr.es/keel/pdf/specific/articulo/vs04.pdf
- https://www.esat.kuleuven.be/sista/members/suykens.html
In short, Neural Networks extract from the data the most relevant part of the information that describes the statistical dependence between the features and the labels. In other words, the size of a Neural Networks specifies a data structure that we can compute and store, and the result of training the network is the best approximation of the statistical relationship between the features and the labels that can be represented by this data structure.
- https://github.com/adityashrm21/information-theory-deep-learning
- https://infotheory.ece.uw.edu/research.html
- Information Theory of Deep Learning
- Anatomize Deep Learning with Information Theory
- “Deep learning - Information theory & Maximum likelihood.”
- Information Theoretic Interpretation of Deep Neural Networks
- https://naftali-tishby.mystrikingly.com/
- http://pirsa.org/18040050
- https://lizhongresearch.miraheze.org/wiki/Main_Page
- https://lizhongzheng.mit.edu/
- https://www.leiphone.com/news/201703/qzBcOeDYFHtYwgEq.html
- http://nsfcbl.org/
- Large Margin Deep Neural Networks: Theory and Algorithms
- http://ai.stanford.edu/
- https://www.math.ias.edu/wtdl
- DEEP 3D REPRESENTATION LEARNING
- https://www.mis.mpg.de/ay/index.html
- Mathematical Algorithms for Artificial Intelligence and Big Data Analysis (Spring 2017)
- https://www.tbsi.edu.cn/index.php?s=/cms/181.html
- https://www.bigr.io/deep-learning-neural-networks-iot/
- https://www.ee.ucl.ac.uk/iiml//projects/it_foundations.html
- https://www.isi.edu/~gregv/ijcai/
- https://arxiv.org/abs/1804.09060
- https://people.eng.unimelb.edu.au/jmanton/static/pdf/ISIT2020_preprint.pdf
- http://proceedings.mlr.press/v80/chen18j/chen18j.pdf
- https://arxiv.org/pdf/1503.02406.pdf
- https://stat.mit.edu/calendar/gregory-wornell/
- http://www.mit.edu/~a_makur/publications.html
- https://www.rle.mit.edu/sia/publications/
- https://www.rle.mit.edu/sia/
- https://xiangxiangxu.com/
In this talk, we formulate a new problem called the "universal feature selection" problem, where we need to select from the high dimensional data a low dimensional feature that can be used to solve, not one, but a family of inference problems. We solve this problem by developing a new information metric that can be used to quantify the semantics of data, and by using a geometric analysis approach. We then show that a number of concepts in information theory and statistics such as the HGR correlation and common information are closely connected to the universal feature selection problem. At the same time, a number of learning algorithms, PCA, Compressed Sensing, FM, deep neural networks, etc., can also be interpreted as implicitly or explicitly solving the same problem, with various forms of constraints.
- Universal Features
- https://glouppe.github.io/info8010-deep-learning/
- http://ita.ucsd.edu/
- http://naftali-tishby.mystrikingly.com/
- http://lizhongzheng.mit.edu/
- The Information Theoretic Problem in Deep-Learning
- https://xiangxiangxu.com/
- https://www.tbsi.edu.cn/index.php?s=/cms/181.html
- The information bottleneck method
- On the information bottleneck theory of deep learning
- Deep Learning and the Information Bottleneck Principle
- https://www.cs.huji.ac.il/labs/learning/Papers/allerton.pdf
- https://mc.ai/summary-on-the-information-bottleneck-theory-of-deep-learning/
- https://www.jmlr.org/papers/volume6/chechik05a/chechik05a.pdf
- https://github.com/billy-odera/info8004-advanced-machine-learning
- Greedy InfoMax for Self-Supervised Representation Learning
- Mutual Information Maximization for Simple and Accurate Part-Of-Speech Induction
- https://arxiv.org/abs/1808.06670
- Deep InfoMax: Learning good representations through mutual information maximization
- https://kwotsin.github.io/post/deep_infomax/
- https://loewex.github.io/
- https://kwotsin.github.io/publication/infomax-gan/
https://ee.stanford.edu/event/seminar/isl-seminar-inventing-algorithms-deep-learning
The first is reliable communication over noisy media where we successfully revisit classical open problems in information theory; we show that creatively trained and architected neural networks can beat state of the art on the AWGN channel with noisy feedback by a 100 fold improvement in bit error rate.
The second is optimization and classification problems on graphs, where the key algorithmic challenge is scalable performance to arbitrary sized graphs. Representing graphs as randomized nonlinear dynamical systems via recurrent neural networks, we show that creative adversarial training allows one to train on small size graphs and test on much larger sized graphs (100~1000x) with approximation ratios that rival state of the art on a variety of optimization problems across the complexity theoretic hardness spectrum.
- https://arxiv.org/abs/1805.09317v1
- https://github.com/datlife/deepcom
- Inventing Communication Algorithms via Deep Learning
- https://infotheory.ece.uw.edu/research.html#deepcode
- Physical Layer Communication via Deep Learning
- COMMUNICATION ALGORITHMS VIA DEEP LEARNING
- https://www.media.mit.edu/groups/signal-kinetics/publications/
- https://research.ece.cmu.edu/lions/Papers/CodedEdge_INFOCOM.pdf
- https://jackkosaian.github.io/
- https://deepcomm.github.io/
- Learning-Based Coded Computation
- https://dl.acm.org/doi/10.1145/3341301.3359654
- https://github.com/Thesys-lab/parity-models
- https://www.cs.cmu.edu/~rvinayak/
- LEARN Codes: Inventing Low-Latency Codes via Recurrent Neural Networks

- Neural Audio Coding
- Psychoacoustic Loss Functions for Neural Audio Coding
- end-to-end optimized speech coding with deep neural networks
- https://arxiv.org/abs/2101.00054
- https://github.com/cocosci/pam-nac
- http://web.mit.edu/hst.723/www/
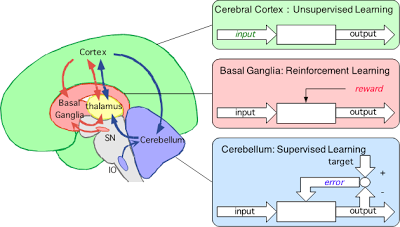
Artificial intelligence and brain science have had a swinging relationship of convergence and divergence. In the early days of pattern recognition, multi-layer neural networks based on the anatomy and physiology of the visual cortex played a key role, but subsequent sophistication of machine learning promoted methods that are little related to the brain. Recently, however, the remarkable success of deep neural networks in learning from big data has re-evoked the interests in brain-like artificial intelligence.
- Theoretical Neuroscience and Deep Learning Theory
- Bridging Neuroscience and Deep Machine Learning, by building theories that work in the Real World.
- Center for Mind, Brain, Computation and Technology
- Where neuroscience and artificial intelligence converge.
- https://elsc.huji.ac.il/events/elsc-conference-10
- http://www.brain-ai.jp/organization/
- https://neurodata.io/
- Artificial Intelligence and brain
- Dissecting Artificial Intelligence to Better Understand the Human Brain
- Deep Learning and the Brain
- AI and Neuroscience: A virtuous circle
- Neuroscience-Inspired Artificial Intelligence
- 深度神经网络(DNN)是否模拟了人类大脑皮层结构? - Harold Yue的回答 - 知乎
- Deep Learning: Branching into brains
- https://www.humanbrainproject.eu/en/
- https://www.neuro-central.com/ask-experts-artificial-intelligence-neuroscience/
- https://sites.google.com/mila.quebec/neuroaiworkshop
- Brains and Bits: Neuroscience Meets Machine Learning
- Learning From Brains How to Regularize Machines
- https://zenkelab.org/
- https://neural-reckoning.github.io/snn_workshop_2020/
- https://fzenke.net/
- https://github.com/google/ihmehimmeli
- Spiking neural networks: Applications to computing, algorithmics, and robotics
- “Why spikes? – Understanding the power and constraints of spiking based computation in biological and artificial neuronal networks”
- https://2020.wcci-virtual.org/session/workshop-6-design-implementation-and-applications-spiking-neural-networks-and-neuromorphic
- https://niceworkshop.org/nice-2020/nice-2020-tutorials/
- Spiking Neural Networks for real-time inference tasks
SpiNNaker is a novel massively-parallel computer architecture, inspired by the fundamental structure and function of the human brain, which itself is composed of billions of simple computing elements, communicating using unreliable spikes.
The project's objectives are two-fold:
- To provide a platform for high-performance massively parallel processing appropriate for the simulation of large-scale neural networks in real-time, as a research tool for neuroscientists, computer scientists and roboticists
- As an aid in the investigation of new computer architectures, which break the rules of conventional supercomputing, but which we hope will lead to fundamentally new and advantageous principles for energy-efficient massively-parallel computing
SpiNNaker project has delivered the world’s largest neuromorphic computing platform incorporating over a million ARM mobile phone processors and capable of modelling spiking neural networks of the scale of a mouse brain in biological real time
- SpiNNaker: A Spiking Neural Network Architecture
- http://apt.cs.manchester.ac.uk/projects/SpiNNaker/project/
- The Neuromorphic Computing platform: Getting started to run network simulations on SpiNNaker and emulations on BrainScaleS
- Running Spiking Neural Network Simulations on SpiNNaker
- SpiNNaker
- SpiNNaker Project - The SpiNNaker Chip.
- https://www.intel.com/content/www/us/en/research/neuromorphic-community.html
- Loihi Deep Dive Architecture, SDK, Examples
Numenta has developed a major theory of intelligence and how the brain works called The Thousand Brains Theory of Intelligence, and we’re now exploring how to incorporate key principles of the theory to the field of machine intelligence.

- https://numenta.com/
- https://numenta.com/blog/2019/01/16/the-thousand-brains-theory-of-intelligence/
- The Thousand Brains Theory
- https://lexfridman.com/jeff-hawkins/
Brain science is the physological theorey of cognitive science, which focus on the physical principle of brain function. The core problem of cognition science is how to learn in my eyes.
Artificial deep neural networks (DNNs) initially inspired by the brain enable computers to solve cognitive tasks at which humans excel. In the absence of explanations for such cognitive phenomena, in turn cognitive scientists have started using DNNs as models to investigate biological cognition and its neural basis, creating heated debate.

- https://www.mis.mpg.de/ay/
- Josh Tenenbaum
- Deep Neural Networks as Scientific Models
- https://wiki.opencog.org/w/Language_learning
- https://github.com/opencog/learn
- Advancing AI through cognitive science - Spring 2019
- NYU PSYCH-GA 3405.001 / DS-GA 3001.014 : Advancing AI through cognitive science
- PSYCH 209: Neural Network Models of Cognition: Principles and Applications
- Computational Learning and Memory Group
- Computational cognitive Science Group @MIT
- Beyond deep learning
- Cognitive Computation Group @ U. Penn.
- Computational cognitive modeling
- Mechanisms of geometric cognition
- Computational Cognitive Science Lab
- Deep Learning for Cognitive Computing, Theory
- TOPIC: FROM ARISTOTLE TO WILLIAM JAMES TO DEEP LEARNING : EVERYTHING OLD IS NEW AGAIN.
- https://www.dcsc.es/
- Deep Neural Networks as Scientific Models
- http://vca.ele.tue.nl/
- Psychlab
- https://www.uni-potsdam.de/en/mlcog/index.html
- https://csai.nl/home/
- https://hadrienj.github.io/about/
- https://iccs2019.github.io/
- https://human-memory.net/
- https://sites.google.com/view/goergen
- https://engineering.purdue.edu/IE/people/ptProfile?resource_id=126302
- https://engineering.columbia.edu/faculty/christos-papadimitriou
- Peristera Paschou
- https://people.csail.mit.edu/mirrokni/Welcome.html
- https://www.mindcogsci.net/
- https://ganguli-gang.stanford.edu/people.html
- http://wiki.ict.usc.edu/cogarch/index.php/Main_Page
- http://cogarch.ict.usc.edu/
- http://bicasociety.org/cogarch/architectures.php
- The Neural Adaptive Computing Laboratory (NAC Lab)
- https://baicsworkshop.github.io/speakers.html
Predictive coding is a leading theory of how the brain performs probabilistic inference.
- Neuronal Dynamics of Predictive Coding
- https://lorenlugosch.github.io/posts/2020/07/predictive-coding/
- https://www.cc.gatech.edu/~dovrolis/Papers/ContinualLearning18.pdf
- Predictive coding and Bayesian inference in the brain
- PREDICTIVE CODING “IS AS IMPORTANT TO NEUROSCIENCE AS EVOLUTION IS TO BIOLOGY.”
- LAB: Lab for the Algorithmic Brain
- https://www.fil.ion.ucl.ac.uk/~karl/#_Computational_neuroscience
- Maximal Mutual Information Predictive Coding for Natural Language Processing
- https://senselab.med.yale.edu/modeldb/ModelList?id=223029
- https://libi.engin.umich.edu/research/neuroscience-driven-artificial-intelligence/
- The Bayesian Brain: An Introduction to Predictive Processing
- https://ieeexplore.ieee.org/document/8733892

- Representation Learning with Contrastive Predictive Coding
- Representation Learning with Contrastive Predictive Coding (Jan 2019)
- http://128.84.21.203/abs/2005.12963
- https://arxiv.org/abs/2004.10120
- https://github.com/SonyCSLParis/vqcpc-bach
- https://sonycslparis.github.io/vqcpc-bach/
- http://proceedings.mlr.press/v136/stacke20a/stacke20a.pdf
- http://people.csail.mit.edu/clai24/data/lai2019contrastive.pdf
A hierarchical predictive coding model consists of layers of latent variables (tiers). Each tier attempts to predict the adjacent lower tier, resulting in a predicted state and a prediction error. By minimizing the prediction error, both the latent variables and the predictors of these variables are estimated.
This principle is often complemented by more general variations that will be supported in future versions of the package
- https://sflippl.github.io/predicode/html/index.html
- Does Hierarchical Predictive Coding Explain Perception?
- https://arxiv.org/abs/2005.03230
- https://ieeexplore.ieee.org/document/9262044
- https://core.ac.uk/display/202307343
The lottery ticket hypothesis proposes that over-parameterization of deep neural networks (DNNs) aids training
by increasing the probability of a “lucky” sub-network initialization being
present rather than by helping the optimization process (Frankle & Carbin, 2019).
- https://ai.facebook.com/blog/understanding-the-generalization-of-lottery-tickets-in-neural-networks
- https://arxiv.org/pdf/1905.13405.pdf
- https://arxiv.org/abs/1903.01611
- https://arxiv.org/abs/1905.13405
- https://arxiv.org/abs/1906.02768
- https://arxiv.org/abs/1906.02773
- https://arxiv.org/abs/1909.13458
- https://zhuanlan.zhihu.com/p/84178021
- https://zhuanlan.zhihu.com/p/67782029
- https://openai.com/blog/deep-double-descent/
- https://zhuanlan.zhihu.com/p/100451862
- http://www.jfrankle.com/
- https://gkdz.org/#about
- http://yosinski.com/
- Deconstructing Lottery Tickets: Zeros, Signs, and the Supermask
- OpenLTH: A Framework for Lottery Tickets and Beyond
- Code: The Lottery Ticket Hypothesis: Finding Small, Trainable Neural Networks
- The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
- The Lottery Ticket Hypothesis at Scale
- Stabilizing the Lottery Ticket Hypothesis
- Linear Mode Connectivity and the Lottery Ticket Hypothesis
- The Lottery Ticket Hypothesis for Pre-trained BERT Networks
- https://roberttlange.github.io/posts/2020/06/lottery-ticket-hypothesis/
- https://internetpolicy.mit.edu/neural-networks-and-the-lottery-ticket-hypothesis/
- Luck Matters: Understanding Training Dynamics of Deep ReLU Networks
The model with optimal parameters are not equal to the best model.
We show that the double descent phenomenon occurs in CNNs, ResNets, and transformers: performance first improves, then gets worse, and then improves again with increasing model size, data size, or training time. This effect is often avoided through careful regularization. While this behavior appears to be fairly universal, we don’t yet fully understand why it happens, and view further study of this phenomenon as an important research direction.

- https://arxiv.org/abs/1710.03667
- Reproducing Deep Double Descent
- Deep Double Descent
- Deep Double Descent (cross-posted on OpenAI blog)
- Deep Double Descent: Where Bigger Models and More Data Hurt
- Double Trouble in Double Descent : Bias and Variance(s) in the Lazy Regime
- https://www.lyrn.ai/
- High-dimensional dynamics of generalization error in neural networks
- https://mltheory.org/deep.pdf