- https://dataconomy.com/2017/04/big-data-101-data-structures/
- http://web.stanford.edu/class/cs168/
- https://www.ics.uci.edu/~pattis/ICS-23/
Vector search engine (aka neural search engine or deep search engine) uses deep learning models to encode data sets into meaningful vector representations, where distance between vectors represent the similarities between items.
- https://www.microsoft.com/en-us/ai/ai-lab-vector-search
- https://github.com/textkernel/vector-search-plugin
- https://www.algolia.com/blog/ai/what-is-vector-search/
- https://www.pinecone.io/learn/vector-search-basics/
To quote the hash function at wikipedia:
A hash function is any function that can be used to map data of arbitrary size to fixed-size values. The values returned by a hash function are called hash values, hash codes, digests, or simply hashes. The values are used to index a fixed-size table called a hash table. Use of a hash function to index a hash table is called hashing or scatter storage addressing.
Hashed indexes use a hashing function to compute the hash of the value of the index field. The hashing function collapses embedded documents and computes the hash for the entire value but does not support multi-key (i.e. arrays) indexes.
- https://www.hello-algo.com/chapter_hashing/hash_algorithm/#632
- https://zhuanlan.zhihu.com/p/43569947
- https://www.tutorialspoint.com/dbms/dbms_hashing.htm
- Indexing based on Hashing
- https://docs.mongodb.com/manual/core/index-hashed/
- https://www.cs.cmu.edu/~adamchik/15-121/lectures/Hashing/hashing.html
- https://www2.cs.sfu.ca/CourseCentral/354/zaiane/material/notes/Chapter11/node15.html
- https://github.com/Pfzuo/Level-Hashing
- https://thehive.ai/insights/learning-hash-codes-via-hamming-distance-targets
- Various hashing methods for image retrieval and serves as the baselines
Cuckoo Hashing is a technique for resolving collisions in hash tables that produces a dictionary with constant-time worst-case lookup and deletion operations as well as amortized constant-time insertion operations.
- An Overview of Cuckoo Hashing
- Some Open Questions Related to Cuckoo Hashing
- Practical Survey on Hash Tables
- Elastic Cuckoo Page Tables: Rethinking Virtual Memory Translation for Parallelism
- MinCounter: An Efficient Cuckoo Hashing Scheme for Cloud Storage Systems
- Bloom Filters, Cuckoo Hashing, Cuckoo Filters, Adaptive Cuckoo Filters and Learned Bloom Filters
- Revisiting Consistent Hashing with Bounded Loads
- https://courses.cs.washington.edu/courses/cse452/18sp/ConsistentHashing.pdf
- https://nlogn.in/consistent-hashing-system-design/
- https://www.ic.unicamp.br/~celio/peer2peer/structured-theory/consistent-hashing.pdf
Locality-Sensitive Hashing (LSH) is a class of methods for the nearest neighbor search problem, which is defined as follows: given a dataset of points in a metric space (e.g., Rd with the Euclidean distance), our goal is to preprocess the data set so that we can quickly answer nearest neighbor queries: given a previously unseen query point, we want to find one or several points in our dataset that are closest to the query point.
- http://web.mit.edu/andoni/www/LSH/index.html
- http://yongyuan.name/blog/vector-ann-search.html
- https://github.com/arbabenko/GNOIMI
- https://github.com/willard-yuan/hashing-baseline-for-image-retrieval
- http://yongyuan.name/habir/
- https://randorithms.com/2019/09/19/Visual-LSH.html
- https://janzhou.org/database/lsh.html
- http://papers.nips.cc/paper/5893-practical-and-optimal-lsh-for-angular-distance
- https://www.cs.rice.edu/~bc20/
- Locality Sensitive Sampling for Extreme-Scale Optimization and Deep Learning
- http://mlwiki.org/index.php/Bit_Sampling_LSH
- Mutual Information Estimation using LSH Sampling
By using hash-code to construct index, we can achieve constant or sub-linear search time complexity.
Hash functions are learned from a given training dataset.
- https://cs.nju.edu.cn/lwj/slides/L2H.pdf
- Repository of Must Read Papers on Learning to Hash
- Learning to Hash: Paper, Code and Dataset
- Learning to Hash with Binary Reconstructive Embeddings
- http://zpascal.net/cvpr2015/Lai_Simultaneous_Feature_Learning_2015_CVPR_paper.pdf
- https://cs.nju.edu.cn/lwj/slides/hash2.pdf
- Learning to hash for large scale image retrieval
- http://stormluke.me/learning-to-hash-intro/
- https://github.com/caoyue10/DeepHash-Papers
- https://www.cs.utah.edu/~jeffp/teaching/cs7931-S15/cs7931/3-rp.pdf
- https://cims.nyu.edu/~munoz/schedule/2013/slides/rp.pdf
- Bio-Inspired Hashing for Unsupervised Similarity Search
- https://github.com/dataplayer12/Fly-LSH
- https://deepai.org/publication/bio-inspired-hashing-for-unsupervised-similarity-search
- https://science.sciencemag.org/content/358/6364/793/tab-pdf
- https://arxiv.org/abs/1812.01844
- http://homepage.cs.uiowa.edu/~ghosh/
- http://ticki.github.io/blog/skip-lists-done-right/
- https://lotabout.me/2018/skip-list/
- Skip Lists: A Probabilistic Alternative to Balanced Trees
Nearest neighbour search is the problem of finding the most similar data-points to a query in a large database of data-points, and is a fundamental operation that has found wide applicability in many fields, from Bioinformatics, through to Natural Language Processing (NLP) and Computer Vision.
- https://github.com/erikbern/ann-benchmarks
- http://ann-benchmarks.com/
- benchmarking-nearest-neighbor-searches-in-python
- New approximate nearest neighbor benchmarks
- Geometric Proximity Problems
- https://yongyuan.name/blog/vector-ann-search.html
- https://yongyuan.name/blog/approximate-nearest-neighbor-search.html
- CS369G: Algorithmic Techniques for Big Data
- ANN: A Library for Approximate Nearest Neighbor Searching
- Randomized approximate nearest neighbors algorithm
- HD-Index: Pushing the Scalability-Accuracy Boundary for Approximate kNN Search in High-Dimensional Spaces
- https://people.csail.mit.edu/indyk/
- Approximate Nearest Neighbor: Towards Removing the Curse of Dimensionality
- Nearest Neighbors for Modern Applications with Massive Data
- https://arxiv.org/pdf/1804.06829.pdf
- https://wiki.52north.org/AI_GEOSTATS/ConfNNWorkshop2008
- Topic: Locality Hashing, Similarity, Nearest Neighbours
- A General and Efficient Querying Method for Learning to Hash (SIGMOD 2018)
- https://people.csail.mit.edu/indyk/slides.html
- https://appsrv.cse.cuhk.edu.hk/~jfli/
- http://www.cse.cuhk.edu.hk/~jcheng/
- https://postgis.net/workshops/postgis-intro/knn.html
- Sublinear Algorithms and Nearest-Neighbor Search
- Bregman proximity queries
- https://cs.nju.edu.cn/lwj/L2H.html
- https://awesomeopensource.com/projects/nearest-neighbor-search
There are some other libraries to do nearest neighbor search. Annoy is almost as fast as the fastest libraries, (see below), but there is actually another feature that really sets Annoy apart: it has the ability to use static files as indexes. In particular, this means you can share index across processes. Annoy also decouples creating indexes from loading them, so you can pass around indexes as files and map them into memory quickly. Another nice thing of Annoy is that it tries to minimize memory footprint so the indexes are quite small.
FALCONN is a library with algorithms for the nearest neighbor search problem. The algorithms in FALCONN are based on Locality-Sensitive Hashing (LSH), which is a popular class of methods for nearest neighbor search in high-dimensional spaces. The goal of FALCONN is to provide very efficient and well-tested implementations of LSH-based data structures.
- https://github.com/falconn-lib/falconn/wiki
- https://libraries.io/pypi/FALCONN
- https://www.ilyaraz.org/
- https://github.com/FALCONN-LIB/FALCONN/wiki/LSH-Primer
- https://github.com/FALCONN-LIB/FALCONN
- https://falconn-lib.org/
SPTAG assumes that the samples are represented as vectors and that the vectors can be compared by L2 distances or cosine distances. Vectors returned for a query vector are the vectors that have smallest L2 distance or cosine distances with the query vector.
SPTAG provides two methods: kd-tree and relative neighborhood graph (SPTAG-KDT) and balanced k-means tree and relative neighborhood graph (SPTAG-BKT). SPTAG-KDT is advantageous in index building cost, and SPTAG-BKT is advantageous in search accuracy in very high-dimensional data.
It explains how SPTAG works:
SPTAG is inspired by the NGS approach [WangL12]. It contains two basic modules:
index builderandsearcher. The RNG is built on the k-nearest neighborhood graph [WangWZTG12, WangWJLZZH14] for boosting the connectivity. Balanced k-means trees are used to replace kd-trees to avoid the inaccurate distance bound estimation in kd-trees for very high-dimensional vectors. The search begins with the search in the space partition trees for finding several seeds to start the search in the RNG. The searches in the trees and the graph are iteratively conducted.
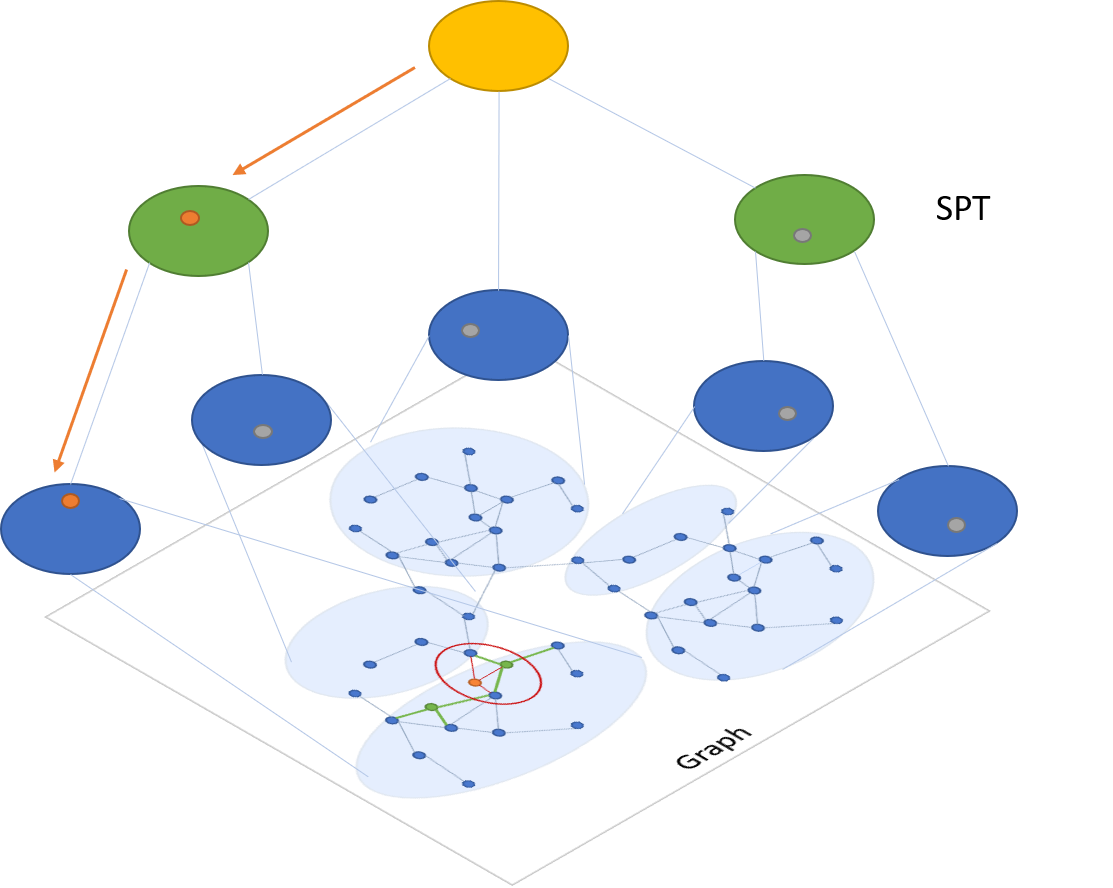
- SPTAG: A library for fast approximate nearest neighbor search
- Query-Driven Iterated Neighborhood Graph Search for Large Scale Indexing
- https://jingdongwang2017.github.io/
Faiss contains several methods for similarity search. It assumes that the instances are represented as vectors and are identified by an integer, and that the vectors can be compared with L2 distances or dot products. Vectors that are similar to a query vector are those that have the lowest L2 distance or the highest dot product with the query vector. It also supports cosine similarity, since this is a dot product on normalized vectors.
Most of the methods, like those based on binary vectors and compact quantization codes, solely use a compressed representation of the vectors and do not require to keep the original vectors. This generally comes at the cost of a less precise search but these methods can scale to billions of vectors in main memory on a single server.
The GPU implementation can accept input from either CPU or GPU memory. On a server with GPUs, the GPU indexes can be used a drop-in replacement for the CPU indexes (e.g., replace IndexFlatL2 with GpuIndexFlatL2) and copies to/from GPU memory are handled automatically. Results will be faster however if both input and output remain resident on the GPU. Both single and multi-GPU usage is supported.
- https://github.com/facebookresearch/faiss
- https://waltyou.github.io/Faiss-Introduce/
- https://github.com/facebookresearch/faiss/wiki
As an open source vector similarity search engine, Milvus is easy-to-use, highly reliable, scalable, robust, and blazing fast. Adopted by over 100 organizations and institutions worldwide, Milvus empowers applications in a variety of fields, including image processing, computer vision, natural language processing, voice recognition, recommender systems, drug discovery, etc.
- https://github.com/milvus-io/milvus
- https://milvus.io/docs/v0.6.0/reference/comparison.md
- https://milvus.io/cn/
- fast library for ANN search and KNN graph construction
- Building KNN Graph for Billion High Dimensional Vectors Efficiently
- https://github.com/aaalgo/kgraph
- https://www.msra.cn/zh-cn/news/features/approximate-nearest-neighbor-search
- https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/37599.pdf
We present a new approach for the approximate K-nearest neighbor search based on navigable small world graphs with controllable hierarchy (Hierarchical NSW, HNSW). The proposed solution is fully graph-based, without any need for additional search structures, which are typically used at the coarse search stage of the most proximity graph techniques. Hierarchical NSW incrementally builds a multi-layer structure consisting from hierarchical set of proximity graphs (layers) for nested subsets of the stored elements. The maximum layer in which an element is present is selected randomly with an exponentially decaying probability distribution. This allows producing graphs similar to the previously studied Navigable Small World (NSW) structures while additionally having the links separated by their characteristic distance scales. Starting search from the upper layer together with utilizing the scale separation boosts the performance compared to NSW and allows a logarithmic complexity scaling. Additional employment of a heuristic for selecting proximity graph neighbors significantly increases performance at high recall and in case of highly clustered data. Performance evaluation has demonstrated that the proposed general metric space search index is able to strongly outperform previous opensource state-of-the-art vector-only approaches. Similarity of the algorithm to the skip list structure allows straightforward balanced distributed implementation.
- https://github.com/nmslib/hnswlib
- https://github.com/nmslib/nmslib
- https://www.itu.dk/people/pagh/
- https://blog.csdn.net/chieryu/article/details/81989920
- http://yongyuan.name/blog/opq-and-hnsw.html
- https://www.ryanligod.com/2018/11/27/2018-11-27%20HNSW%20%E4%BB%8B%E7%BB%8D/
- https://arxiv.org/abs/1707.00143
- https://arxiv.org/abs/1804.09996
- https://arxiv.org/abs/1804.09996
- https://github.com/willard-yuan/cvtk/tree/master/hnsw_sifts_retrieval
- https://github.com/erikbern
- https://github.com/yurymalkov
- https://arxiv.org/abs/1603.09320