Duplicate Finder tool update! #21
Comments
|
Prototype UI 1. The actions are missing, I need to figure out where to put them. EDIT: Also might add both resolution and format of each page into the thumbnail overlay just like the page number. The format(s) will be listed below resolution in the same style as the tags. 2021-11-22_02-19-32.mp4 |
|
Would be nice to have a namespace for which folder the archives are found in. Would make quicker work for certain archives that are duplicates from an authoritative source. Unclear if that is what "Source" is in demonstration. |
The folder where it is stored in the server? Unfortunately I can't pull that. There is a script that converts folders to categories but those are not used in this case.
It is the source from where it came from i.e. the url, at least in my case. The tags section is the same as the tags shown in the archive tab. |
|
Alright everything but the improved caching was implemented. The final design is like the video above but with delete and mark as non duplicate buttons, also pages show their resolution, extension and number. |
|
Failing to pull tags properly. |

|
After using this extensively to remove duplicates from an automatic feed for a while, a few usability things to make sorting duplicates faster, in order of probable ability to do:
Above here are what are probably easy fix implementations.
Overall, it's been a fantastic tool to use, and I've already been able to remove hundreds of automatically downloaded duplicates which would have taken multitudes longer to sort out over time. Keep up the good work,. |
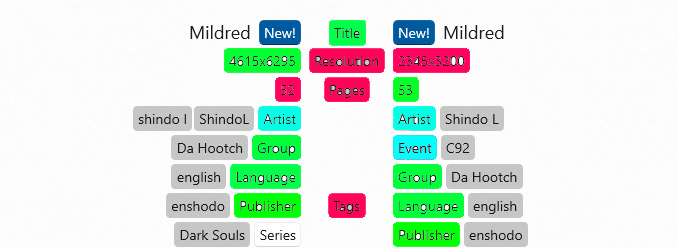

There is a few things that would improve the current duplicate tool for the power user, giving you more info at a glance and allowing you to make a more informed decision.
Cache duplicate processing data locally and update on new runs.
Mark a PAIR of comics as not Duplicates, this should be per Comic ID in Lanraragi, allowing it to skip it for future searches, like a blacklist. An overwrite might be wanted for this for corrections of user errors? This should be on a per pair basis
A Compare comic issue view that fills the window with both comics of the pair, taking up half the screen each with thumbnails of all pages of each. This allows you to more easily at a glance. Much like the detailed page of a comic that displays all metadata and all thumbnails. Just loaded side by side in the tab itself. Overlay would be wanted but could be done with its own tab type: This could be done a bit easier by having a split view tab type that is general for all content, and allowing the dupe tool to make a new such tab and prefill the comic issues in question.
Listing image sizes of either original cover art or all images if possible.
Display Cached info in a comparison manner between the two comic issues. A is higher res than B displaying the common res and in green for example. same with other data like amount of tags and pages. Here is an example of such a thing from Hydrus with Import date, file size, image res and jpeg compression setting.

The text was updated successfully, but these errors were encountered: