Imagine having something like the following situation:
ThreadSafeQueue queue;
void thread_a() {
// Infinite loop just for the sake of this example.
while(true) {
...
queue.push(...);
...
}
}
void thread_b() {
while(true) {
...
x = queue.pop();
...
}
}(Pseudo C++, but the concept applies to other languages too.)
Both functions (thread_a and thread_b) are running concurrently on different OS threads. It's a typical producer-consumer situation.
Maybe thread_a is doing something that should not have too much latency, e.g., communicating with a PLC, and thread_b does some work, that is allowed to have high latency, e.g., updating some UI elements.
Of course, if you had hard real-time requirements, you would use a real-time OS. Nevertheless, since the job of thread_a is more urgent than the job of thread_b, you decide to change the priorities:
thread_a:HIGHpriority (low latency)thread_b:LOWpriority (high latency)
So with the help of the preemptive scheduler of the OS, you now should have low latency on thread_a, because with its priority it's not only preferred over thread_b but also over all other threads (not shown above) with priority NORMAL (the default).
Seems fine, right? But in reality, it likely is not. Assuming our ThreadSafeQueue isn't a specially designed lock-free with all its quirks, but protected by a mutex instead, with a bit of manual inlining, the code reveals more of what it is doing:
Mutex queue_mutex;
void thread_a() {
while(true) {
...
queueMutex.lock();
// push
queueMutex.unlock();
...
}
}
void thread_b() {
while(true) {
...
queueMutex.lock();
// pop
queueMutex.unlock();
...
}
}(Exception-safety using RAII purposely ignored for clarity.)
This means the following might (read "will") happen at some point:
thread_blocks the mutex.- The scheduler interrupts it's execution and gives the CPU to some other thread.
- It might take quite long until
thread_bgets its next time slice. Some other threads with priorityNORMAL, which can also live in other processes running on the same machine, might have quite some time-consuming work to do, so the scheduler prefers them overthread_b. thread_athus will be forced to wait on it's blocking.lock()call for quite long.- Consequently,
thread_ahas lost its low-latency property.
So you thought you have the following:
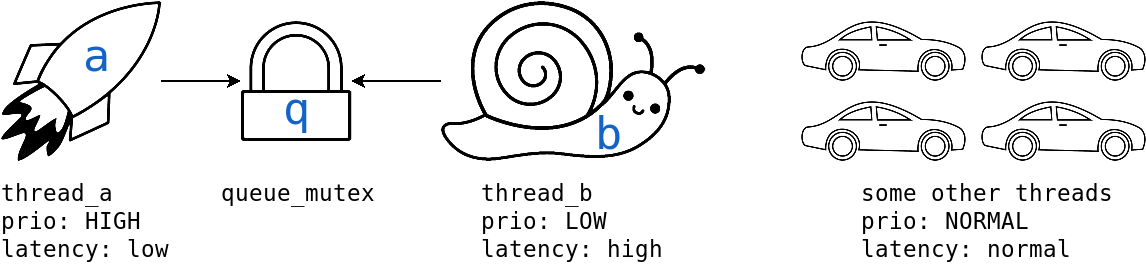
But in reality, you have:

thread_b infected thread_a with its low priority.
This brings us to a new theorem:
A thread's observed priority is not higher than the lowest priority of any thread it shares a mutex with.
The strength of the effect this (priority inversion) has on latency may differ depending on what OS/scheduler is used, but in general, it holds that, as soon as thread priorities are changed deliberately for any reason, one suddenly is forced to investigate the thread-mutex graph of one's application and check for lower-prioritized neighbors. OS schedulers might implement different techniques to lessen the severity of this problem, each of them with different upsides and downsides.
Naturally, the question arises, if this spreading can be transitive too, i.e., if, in the following graph example, the priority of thread_e can have an influence on the latency / observes priority of thread_c:

The answer is: Yes, it can. It depends on how the acquisitions of the locks in thread_d are intertwined.
Mutex mutex_1;
Mutex mutex_2;
// prio HIGH
void thread_c() {
while(true) {
...
mutex_1.lock();
...
mutex_1.unlock();
...
}
}
// prio NORMAL
void thread_d() {
while(true) {
...
mutex_1.lock();
...
mutex_2.lock();
...
mutex_2.unlock();
...
mutex_1.unlock();
...
}
}
// prio LOW
void thread_e() {
while(true) {
...
mutex_2.lock();
...
mutex_2.unlock();
...
}
}(The situation in thread_d might be hidden in calls so some other functions.)
So, what can happen here?
thread_edoes itsmutex_2.lock().- The scheduler interrupts
thread_e. thread_ddoes itsmutex_1.lock().thread_dwants to do itsmutex_2.lock(), but is blocked, becausethread_eis already sleeping insidemutex_2.thread_ctries do it itsmutex_1.lock(), but is blocked, becausethread_dalready has acquiredmutex_1.
Thus, thread_c is blocked at least as long as thread_e does not reach its mutex_2.unlock(). And this, again, can take quite a while.
So, the latency of thread_c was ruined, transitively, by thread_e,
and you end up with the following:

This can haunt you not only when using classical mutexes, but with other types of mutual exclusion devices too.
Conclusion: If possible, avoid headaches by just not fiddling around with thread priorities.