Just a place to store graphs and benchmark results #236
Comments
Collision studyIt's the first test I'm aware of able to directly probe the collision efficiency of 64-bit hashes (32-bit collision efficiency was already well covered by SMHasher). Unfortunately, 128-bit collision analysis is still way off. The test generates a massive amount of hashes, and counts the number of collisions produced. It doesn't come cheap, and requires a lot of time, and a lot or RAM. Testing 64-bit hashes on large inputs :An input of 256 bytes is expected to always trigger the "long" mode for hashes algorithms featuring multiple modes depending on input length.
Testing 64-bit non-portable hashes :
The collision ratio is too high to recommend using these algorithms as checksums. Testing 64-bit hashes on small inputs :The test on input 8 bytes => 8 bytes output can check if there is some "space reduction" happening at this length. If there is no space reduction, then the transformation is a perfect bijection, which guarantees no collisions for 2 different inputs.
Testing 128-bit hashes :The only acceptable score for these tests is always
Tests on small input lengths
|
|
@Cyan4973 How can I reproduce your benchmark results? And if possible could you add wyhash into your graph? xxhash will be faster than wyhash for large enough size i.e about 256bytes in my tests, however, it would be very helpful to let users know about that.
|

|
@hungptit , I haven't yet open-sourced the collision analyzer. This effort still needs to be done. Maybe I'll add it later in the repository, typically under For the time being, I'm just populating a few test results, trying to complete a picture. |
|
@Cyan4973 I plan to send you a PM to ask about the suggestion for collision analyzer and luckily you point me to this thread. I am looking forward to your collision analyzer and I would assume other users also eager to try it given the number years that you have been working on the excellent cryptographic applications. I think wyhash is an excellent hash and it would be helpful to users if you can include it in your benchmark. AquaHash (created by Andrew Rogers) is new and have not been through any serious battle yet and it is not portable so you do not need to worry about it for now. I can help to add it to your collision analyzer later once you can open-source it. |
|
I will move graphs and tables into the "wiki" section, where it's more appropriate as documentation, I suppose. For the time being, the first page is here : I will continue with the collision analysis results. |
|
Btw @hungptit , if you are interested in the performance graphs, as opposed to the collision analyzer, the benchmark tool is already available, within the repository at |
|
I completed a 64-bit collision test for some AES-based algorithms. |
|
@Cyan4973 It is bad news for me because I may not be able to use AquaHash for my local cache :) However, it is good news since you have confirmed that AquaHash may not be good enough for normal use cases and I need to figure out something else. Do you have any result for wyhash and clhash? And how about other AES-based algorithms such as meow hash? I look forward to using your collision analysis tool in the near future so I can quickly evaluate the quality of any new hash algorithm i.e performance and quality. Let me know if you need help with testing and/or evaluating your analyzer. |
I've updated the table with results from more hashes. |
|
@Cyan4973 I think your benchmark + analysis is good enough to write an excellent article. I would love to read about how you compare hash functions mathematically with some benchmark numbers :) |
|
Slight error: AES is SSE4.2. |
|
On the Intel Intrinsic Guide, it's not even listed as part of SSE : it seems to be in its own category : That's may be why it has its own switch That being said, it was released "at the same time as", say, SSE4.2, so it's easy to make the equivalence. |
|
Was it meowhash 0.5 or a previous version? |
|
The 1-bit loss in t1ha2 is mostly due to wide multiplication as one of the last steps in mixing the final result. The thing is, the operation of the form |
|
You don't need that much brute force to understand that. Just print out a small table, as multiplication properties scale. You can pretty clearly see that xor breaks up some of the patterns, but has more bias on the high bits because it saturates instead of overflowing. It is also less symmetrical. That is the main reason for xor folding those high bits every so often. That spreads stuff to the lower bits which don't fare well. |
|
Good news : The primary intention is to check that The collision generator cannot exactly reach 128-bit level, that would require an insane amount of resources. But it can get close to ~80-bit, and that's enough to break some hash algorithms which announce 128-bit of variance. It's an interesting result, because such limitation was invisible up to now. |
|
By the way, I thought I said this before but I guess I didn't.
That is because AES isn't a hash function. It is an encryption algorithm. Why AES sucks for hashingEncryption is just a fancy permutation, and it is designed to be reversible. Hashing is more than a fancy permutation, and it is designed to be irreversible and highlight one-bit changes by changing basically most the bits. AES doesn't, and it fails miserably at the last property. Here is how AES (from As you can see, only 32 bits are affected, since it is treated as separate lanes. Source for output (not my best code lol)// _mm_aesenc_si128 equivalent
// https://github.com/veorq/aesenc-noNI, modified to not overwrite
#include <stdint.h>
static const uint8_t sbox[256] =
{ 0x63, 0x7c, 0x77, 0x7b, 0xf2, 0x6b, 0x6f, 0xc5, 0x30, 0x01, 0x67, 0x2b, 0xfe,
0xd7, 0xab, 0x76, 0xca, 0x82, 0xc9, 0x7d, 0xfa, 0x59, 0x47, 0xf0, 0xad, 0xd4,
0xa2, 0xaf, 0x9c, 0xa4, 0x72, 0xc0, 0xb7, 0xfd, 0x93, 0x26, 0x36, 0x3f, 0xf7,
0xcc, 0x34, 0xa5, 0xe5, 0xf1, 0x71, 0xd8, 0x31, 0x15, 0x04, 0xc7, 0x23, 0xc3,
0x18, 0x96, 0x05, 0x9a, 0x07, 0x12, 0x80, 0xe2, 0xeb, 0x27, 0xb2, 0x75, 0x09,
0x83, 0x2c, 0x1a, 0x1b, 0x6e, 0x5a, 0xa0, 0x52, 0x3b, 0xd6, 0xb3, 0x29, 0xe3,
0x2f, 0x84, 0x53, 0xd1, 0x00, 0xed, 0x20, 0xfc, 0xb1, 0x5b, 0x6a, 0xcb, 0xbe,
0x39, 0x4a, 0x4c, 0x58, 0xcf, 0xd0, 0xef, 0xaa, 0xfb, 0x43, 0x4d, 0x33, 0x85,
0x45, 0xf9, 0x02, 0x7f, 0x50, 0x3c, 0x9f, 0xa8, 0x51, 0xa3, 0x40, 0x8f, 0x92,
0x9d, 0x38, 0xf5, 0xbc, 0xb6, 0xda, 0x21, 0x10, 0xff, 0xf3, 0xd2, 0xcd, 0x0c,
0x13, 0xec, 0x5f, 0x97, 0x44, 0x17, 0xc4, 0xa7, 0x7e, 0x3d, 0x64, 0x5d, 0x19,
0x73, 0x60, 0x81, 0x4f, 0xdc, 0x22, 0x2a, 0x90, 0x88, 0x46, 0xee, 0xb8, 0x14,
0xde, 0x5e, 0x0b, 0xdb, 0xe0, 0x32, 0x3a, 0x0a, 0x49, 0x06, 0x24, 0x5c, 0xc2,
0xd3, 0xac, 0x62, 0x91, 0x95, 0xe4, 0x79, 0xe7, 0xc8, 0x37, 0x6d, 0x8d, 0xd5,
0x4e, 0xa9, 0x6c, 0x56, 0xf4, 0xea, 0x65, 0x7a, 0xae, 0x08, 0xba, 0x78, 0x25,
0x2e, 0x1c, 0xa6, 0xb4, 0xc6, 0xe8, 0xdd, 0x74, 0x1f, 0x4b, 0xbd, 0x8b, 0x8a,
0x70, 0x3e, 0xb5, 0x66, 0x48, 0x03, 0xf6, 0x0e, 0x61, 0x35, 0x57, 0xb9, 0x86,
0xc1, 0x1d, 0x9e, 0xe1, 0xf8, 0x98, 0x11, 0x69, 0xd9, 0x8e, 0x94, 0x9b, 0x1e,
0x87, 0xe9, 0xce, 0x55, 0x28, 0xdf, 0x8c, 0xa1, 0x89, 0x0d, 0xbf, 0xe6, 0x42,
0x68, 0x41, 0x99, 0x2d, 0x0f, 0xb0, 0x54, 0xbb, 0x16 };
#define XT(x) (((x) << 1) ^ ((((x) >> 7) & 1) * 0x1b))
void aesenc (uint8_t *out, const uint8_t *s, const uint8_t *rk) {
uint8_t i, t, u, v[4][4];
for (i = 0; i < 16; ++i) v[((i / 4) + 4 - (i%4) ) % 4][i % 4] = sbox[s[i]];
for (i = 0; i < 4; ++i) {
t = v[i][0];
u = v[i][0] ^ v[i][1] ^ v[i][2] ^ v[i][3];
v[i][0] ^= u ^ XT(v[i][0] ^ v[i][1]);
v[i][1] ^= u ^ XT(v[i][1] ^ v[i][2]);
v[i][2] ^= u ^ XT( v[i][2] ^ v[i][3]);
v[i][3] ^= u ^ XT(v[i][3] ^ t);
}
for (i = 0; i < 16; ++i) out[i] = v[i / 4][i % 4] ^ rk[i];
}
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
static void print_buf(const uint8_t *buf)
{
for (int i = 0; i < 16; i++) {
printf("%02x", buf[i]);
}
}
int main(void)
{
srand(time(NULL));
uint8_t input[16], output[16], key[16];
for (int i = 0; i < 16; i++) {
key[i] = rand();
}
printf("Key:\n");
print_buf(key);
for (int j = 0; j < 8; j++) {
for (int i = 0; i < 16; i++) {
input[i] = rand();
}
printf("\n");
print_buf(input);
printf(" ");
aesenc(output, input, key);
print_buf(output);
int mask = rand();
input[(mask / 8) % 16] ^= (1 << (mask % 8));
printf("\n");
print_buf(input);
printf(" ");
aesenc(output, input, key);
print_buf(output);
printf("\n%*s\n", ((mask / 8) % 16) * 2 + 2, "^^");
}
}Additionally, AES cancels itself out: aesenc(x, aesenc(x, y)) == yWhile this is fine for encryption since you only use So if you had a hash that looked like this.... uint128_t hash(uint128_t seed, const uint8_t *input, size_t len)
{
uint128_t acc = seed;
for (size_t i = 0; i < len / 16; i++) {
acc ^= aesenc(read128(input + 16 * i), acc);
}
if (len % 16) {
acc ^= aesenc(readpartial128(input + (len & ~(size_t)15), len & 15), acc);
}
return acc;
}You have 30 seconds to find at least 340282366920938463463374607431768211456 length extension collisions with this: Lastly, AES is terribly slow if you don't have AES-NI or ARM crypto. While AES-NI is pretty common, with all Intels >= Nehalem and AMDs >= Bulldozer (iirc), ARM crypto is a pretty recent optional extension that many manufacturers leave out for cost and simplicity (see also: integer division in ARMv7) And we have more than proven that you can write a good, fast hash function without any non-portable instructions. Just see all xxHash variants and basically any scalar hash. |
|
Yawn, hopefully back from my hiatus and I got a new PC! AMD Ryzen 5 3600 Scalar SSE2 AVX2 (hot damn!) |
|
Nice new config @easyaspi314 ! And an AMD platform is welcomed, as it provides a pretty nice comparison point to measurements on Intel ones ! 2 details that stand out :
|
|
Oh oof, just realized that CMake was on RelWithDbgInfo which does /Ob1. That would explain it, since the read functions are just static I'll get a new bench later. |
|
I've also updated the internal benchmark function |
|
Timer inaccuracy would explain a lot. Since it definitely wasn't going into super saiyan mode (Core 2 has no Turbo Boost), the best explanation is an inaccurate timer. There were other places where I got an even multiple, like the POWER9 which got 30000.0. |
|
This is a lot more believable! SSE2 AVX2 Everything lines up properly now, and the results are a lot more accurate. Especially scalar which fits the "roughly 1.5x the speed of XXH32" pattern I have typically seen. |
|
Here is x86 scalar (with XXH3_hashLong_internal_loop forced inline) Also matches the "3/4 the speed of XXH32 on 32-bit" pattern as well. Everything seems to check out. I say definitely remove this hack: #if defined(__clang__) && (XXH_VECTOR==0) && !defined(__AVX2__) && !defined(__arm__) && !defined(__thumb__)
static void
#else
XXH_FORCE_INLINE void
#endif |
|
I kind of remember that So, somehow, this property was lost during later updates ? |
|
I do see a few tweaks that change the performance, such as putting the multiply over the block, but I am thinking that it is just that XXH32 is faster in relation (AMD seems to have a better ROL) or compiler differences (you used GCC, no?). I am going to try in msys2 with GCC. |
|
I just tested it on my laptop, which features an i7-8559U, On latest However, if I use Note : I have to force |
GCC is clearly cheating, there is no way it is generating better code than Clang 😛 This is with the swapped multiply: XXH_ALIGN(XXH_ACC_ALIGN) xxh_u64* const xacc = (xxh_u64*) acc; /* presumed aligned on 32-bytes boundaries, little hint for the auto-vectorizer */
const xxh_u8* const xinput = (const xxh_u8*) input; /* no alignment restriction */
const xxh_u8* const xsecret = (const xxh_u8*) secret; /* no alignment restriction */
size_t i;
XXH_ASSERT(((size_t)acc & (XXH_ACC_ALIGN-1)) == 0);
for (i=0; i < ACC_NB; i++) {
xxh_u64 const data_val = XXH_readLE64(xinput + 8*i);
xxh_u64 const data_key = data_val ^ XXH_readLE64(xsecret + i*8);
xacc[i] += XXH_mult32to64(data_key & 0xFFFFFFFF, data_key >> 32);
if (accWidth == XXH3_acc_64bits) {
xacc[i] += data_val;
} else {
xacc[i ^ 1] += data_val; /* swap adjacent lanes */
}
} |

|
It's funny that we get the |
|
Well you are using Clang 6.0, perhaps there was a regression… Are you using -mno-sse2? IIRC with SSE2+XXH_VECTOR=0, Clang will half vectorize it. |
|
Indeed.
So I benchmarked
That was it. I was only setting |
|
I'm really curious now. I mean scalar x86 isn't that important since SSE2 is safe to assume, but the fact that GCC is generating significantly faster code piques my interest. |
|
@easyaspi314 gcc is better than clang in some optimizations. If you try double y = 1.0 * x in the compiler explorer then you will see gcc is smarter than both clang and msvc. |
|
We know that compilers optimize differently, and we have plenty of ugly hacks to correct misoptimizations/dumb expansions:
I was mostly making the joke because Clang usually is better with this stuff, and it is my favorite compiler. |
Performance graphs, comparing
XXH3with other portable non-cryptographic hashes :Bandwidth on large data (~100 KB)
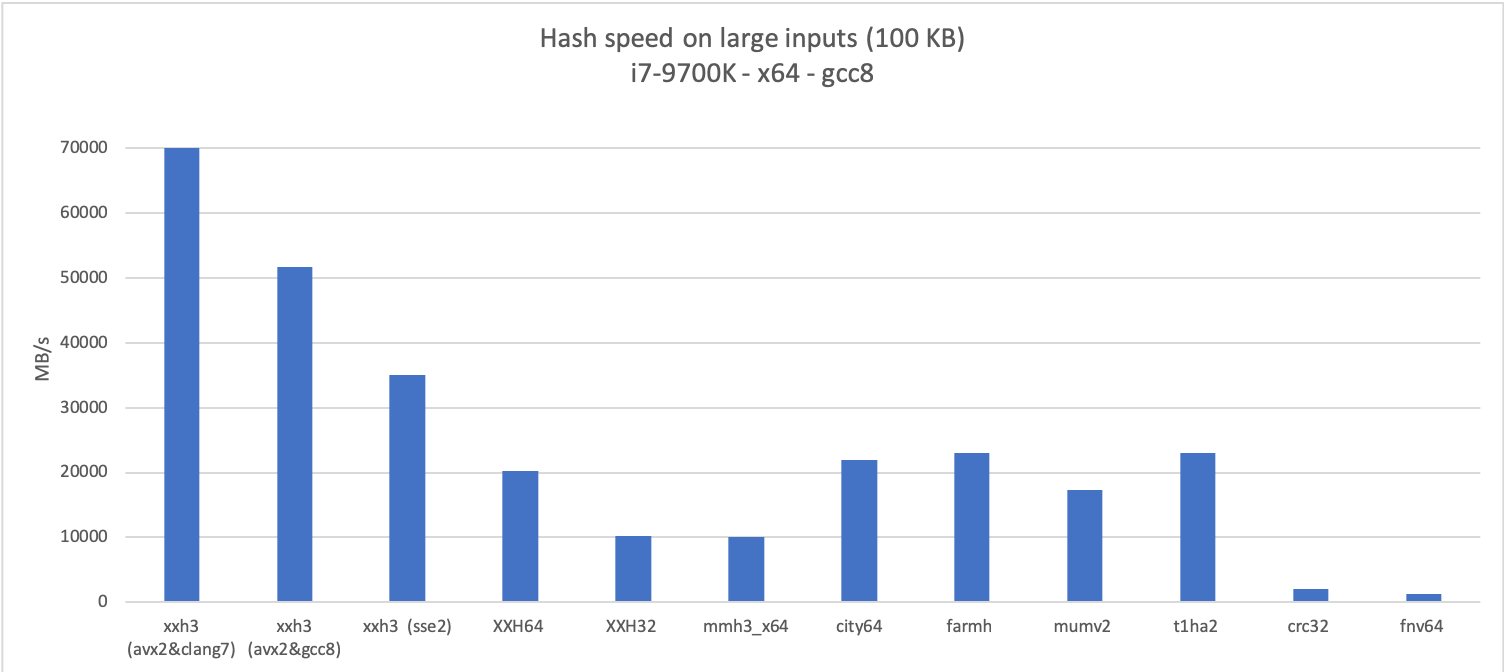
Bandwidth on x64 on variable size data of len 2^N

Bandwidth on x86 on variable size data of len 2^N (32-bit friendliness)

Following benchmarks concentrate on small data :
Throughput on small data of fixed length N

Throughput tests try to generate as many hashes as possible. This is the easiest methodology for benchmark measurements, but mostly representative of "batch mode" scenarios.
Throughput on small data of random length [1-N]

When input size is a random length, it's much harder for the branch predictor to properly select the right path in the algorithm. The impact on performance can be major.
Latency on small data of fixed length N
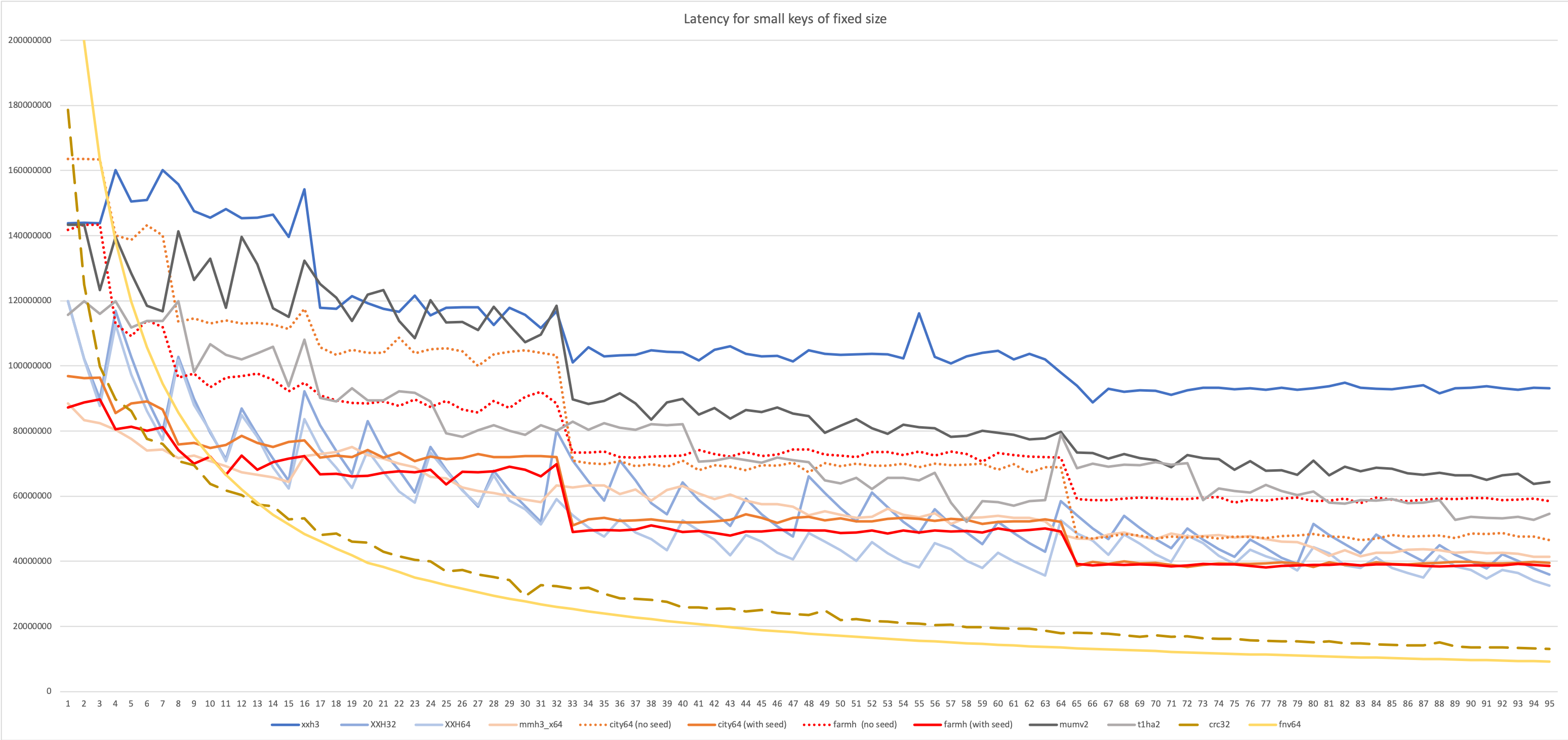
Latency tests require the algorithm to complete one hash before starting the next one. This is generally more representative of situations where the hash is integrated into a larger algorithm.
Latency on small data of random length [1-N]

The text was updated successfully, but these errors were encountered: