xxHash as checksum for error detection #229
Comments
|
CRC algorithms generally feature guarantees of error detection under condition of hamming distances. Given a limited number of bit flips, the CRC will necessarily generate a different result. This can prove handy in situations where errors are presumed to only flip a few bits. This property however has a distribution cost. Once the "safe" hamming distance is crossed, the probability of collision becomes worse. This is a logical consequence of pigeon hole principle. How much worse ? Well, it depends on the exact CRC, but I expect good CRC to be in the 3x - 7x worse range. That may sound a lot, but it's just a 2-3 bits dispersion reduction, so it's not that terrible. Still. Contrast that with a hash featuring "ideal" distribution property : any change, no matter if it's a single bit or a completely different output, has exactly 1 / 2^n probability to generate a collision. It's simpler to grasp : the risk of collision is always the same. In a direct comparison with CRC, when hamming distance is small collision rate is worse (since it's >0), but it's better when hamming distance is large. Fast forward nowadays, and the situation has radically changed. We have layers upon layers of error detection and correction logic above the physical media. We can't just extract a bit from a flash block, nor can we read a bit from a Bluetooth channel. It doesn't make sense any more. These protocols embeds a stateful block logic, which is more complex, more resilient, constantly compensating for the permanent noise of the physical layer. When they fail, that's not going to produce a single flip: rather, a complete data region will be completely shambled, being all zeroes, or even random noise. In this new environment, the bet is that errors, when they happen, are no longer in the "bitflip" category. In which case, the distribution properties of CRC become a liability. A pure hash actually has a lower probability to produce a collision. This is when considering checksumming only. One could say that checksum and hashing are simply 2 different domains, and should not be confused. Indeed, that's the theory. Problem is, this disregards convenience and field practice. Having one "mixer" for multiple purpose is convenient, and programmers will settle for one and forget about it. I can't count how many times I've seen crc32 used for hashing, just because it felt "random enough". It's easy to say that it should not happen, but it does, constantly.
Due to the properties of a good hash, it's indeed possible to extract 8 or 16 bits from a hash, resulting in a 1/256 or 1/65535 collision probability. I see no concern on this. Just, we have to accept the latency of history. People are used to a certain way of things, such as using specific checksum functions for checksumming. Even if there are more recent and potentially better solutions out there, habits do not change fast. |
we know that with CRC 32 and using HD=6 it can detect any 5-bit errors and it can detect bursts up to 2^31=about 204MB
Why is that bad? If bits are somehow correlated can we use this correlation to repair the damaged file? |
1 bit. xxHash is a non-cryptographic hash function, not a checksum. It does not provide any hamming distance or collision resistance guarantees. While it can do a decent job at it, it is not the best choice. It is like using pliers as a wrench. Sure, it will get the job done, but it is less effective than a real wrench and may cause damage. |
do you mean we can fool the decoder with just changing 1 bit of data? |
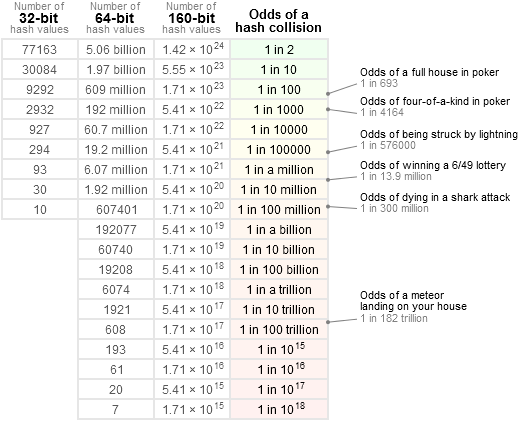
Considering hash values produced from 2 different contents, the probability of collisions is always It indeed means that, at least in theory, a change of a single bit might be able to generate a collision. Now, keep in mind that this probability is In order to get a more accurate idea, I like to refer to this table : i.e : If one wants to find such a theoretic 1-bit collision, one would need a pretty gigantic input and a pretty unbelievable amount of power to brute force a solution to this problem. Even then, a solution might not exist : considering the nature of employed arithmetic, I wouldn't be surprised if it would be impossible to generate a collision with a single bit modification. My own bet is that it takes at least 2 bits, and even then, it requires to place them in specific input's positions to stand a chance to achieve the desired objective, making such a modification no longer "random", hence out of scope for a non-cryptographic hash. But I think the quoted text already explains all this : real
Hashes have generally more usages than just checksum replacement.
This is a completely different topic. Self-repairing data is a topic, and uses different (and much more computationally involved) techniques, such as convolutional codes. This is much more complex. |
#261 demonstrates a single bit collision in the 64-bit variant of XXH3, although it is seed-dependent and very unlikely to happen on random inputs |
|
Indeed; to be more complete, my previous statement was rather directed at the large-size section, for inputs > 240 bytes. But yes, in the limited range of sizes where the input has to match exactly one of the 64-bit |
could you confirm these scenarios?
|
|
The described scenario is :
The LZ4 frame format uses To remain undetected, a corruption must successfully pass all applicable checksums. Now, if corrupted data resides in multiple blocks, either because there are multiple corruption events, or because a single large corrupted section cover consecutive blocks, it's even harder for the corruption to remain undetected. It would have to generate a collision with each one of the block checksums involved. Not counting the fact that each corrupted block may be detected as undecodable by the decompression process, which comes on top of that. So yes, combining block and frame checksum dramatically increases chances of detecting corruption events. |
Is it possible to use LZ4 on the fly? I mean, compress/decompress the data as soon as you've got some of it. it is somehow pipelining. |
This is the streaming mode. Yes it is possible.
The frame checksum is updated continuously, but only produces a result at the end of the frame. Therefore, there is no checksum result to compare to until an end of frame event (a stream may consist of multiple appended frames, but generally doesn't). In contrast, block checksums are created at each block, so they are regularly produced and checked while streaming. Both checksums employ |
|
hi... i know this is an old topic but i think i have something to add... resuming... on error detected (with crc or hash)....
in addition...
... these make crc inappropiate for security purposes (data validation, authentication, password storing/comparison, etc.) CHECK THESE EXCELENT VIDEOS TO UNDERSTAND FURTHER ABOUT CRCs= part 1, part 2 |
One of the things I continually fail to understand is how a hash can be a checksum (or whether they should be), because traditionally hashes are optimized for strings, and for hash tables (DJB2 comes to mind as an old fan favorite). However within the PIC/Arduino crowd, people still use old simple 8-bit checksums, 16-bit Fletcher sums or 16-bit CRC. But you don't see much talk on new checksums as being better choices with today's supposedly faster processors. Are the types of computations used in hashes too slow? (despite CRC being actually slower in software than xxHash..) Or is something inherently bad with hash functions when reduced to 8 or 16 bit?
I've read that xxHash was designed first as a checksum for lz4, and some other hash functions such as SeaHash designed for use in a file system also for checksumming. For comparison, CRC-32 has been widely used, also in some compression formats (like ZIP/RAR). I have also read that CRC has certain mathematical properties which proves hamming distances for error detection for specific polynomials, etc. But in many ways hashes are more chaotic, more resembling pseudo-number-generators, unlikely to have such guarantees, at least that is how it seems to me.
This leaves me wondering if one is better off using CRC-32 for integrity purposes rather than a fast, simple to implement hash, even if it may have a speed hit. Does xxHash have any error-detection guarantees (lets assume 32-bit version)? And if not, how does it compete with CRC-32 as a checksum or error-detection code? What are the tradeoffs?
The text was updated successfully, but these errors were encountered: