Update from Chia on the Dust Storm #9049
Replies: 10 comments 54 replies
-
|
Generally speaking the chain has handled it well with most nodes keeping things running smoothly Could you provide some data that show that "most nodes keeping things running smoothly." Otherwise, we have to assume that you pulled that out of a hat just to get off of the hook. Also, not all traffic is just around transactions. Plenty of farms have huge number of stalled partials. Those are potentially farms where their upload bandwidth got overloaded by "low performance" / starving nodes. It look like those nodes cannot process data that they are getting from the network fast enough, as such are dropping that network data on the floor, and starting to request the same data over and over. However, there are a decent number of nodes out there who are either running low performance nodes or are otherwise suboptimal in their configuration. Could be more specific what resource requirements those nodes are not meeting? I guess, blaming everything on RPis out there is just nonsense. You can easily say that all the nodes need to run on the latest server based chips, and home desktops will not cut. Q: Why isn’t Chia capable of preventing this? If those are fact of life events, then why Chia didn't run such well known scenarios on the test network? Do you have QA dept? Q: If I’m feeling strain on my node, is there anything I can do to alleviate it? Looks like you don't quite understand the problem. The issue is not with the number of connections, but rather with the total upload bandwidth used. Also, your suggestion to "you have the option to terminate their connection" is basically asking farmers to engage in a whack-a-mole game, as looks like there is plenty of those 'starving' nodes, and once you delete one, the next one is waiting to connect. As such, why don't you prioritize farming traffic over peer-syncing requests. The second issue is what do you do to back-off from overloading the upload bandwidth. Looks like there is no throttling protocol there, and nodes are just happily choking the upload bandwidth, when some "starving" nodes are potentially requesting the same data over and over. |
Beta Was this translation helpful? Give feedback.
-
|
Is it time to consider promoting the use of open source funding for client development? IMO the ideal model is how Ethereum utilizes grant money to fund pool client development (Geth, OpenEthereum, etc) to ensure there are many open source clients for pools to choose from. There are also very good reasons Ethereum uses more than one client on the network. It helps prevent network wide issues when a single client has an issue, otherwise it could mean the entire network goes dark if there were no other clients. This has already happened with previous release issues with bugs and will continue to happen as long as the network only runs one client. The current situation is forcing people with low end hardware to run full nodes so they can farm since there is only one OP pool that runs their own client but is shunned by the community for doing so. If you promoted the development of clients that do not require nodes this problem would naturally go away as those with weak hardware could run the lite clients if you will on the pools that support them. I know it is nice to say we have millions of nodes and it makes our network the safest. However we are now finding the network may only be as safe as the weakest links; nodes being run on subpar hardware because there is no other option for them. I have mined Ethereum for almost 5 years and never ran an ETH1.0 client to do so. This is done by the pools and how it should be to prevent bad nodes on the network from causing issues like we quickly saw as TPS scaled and revealed what some of us already knew. |
Beta Was this translation helpful? Give feedback.
-
And this is the exact reason why Ethereum is at risk to pools getting together and threatening to hijack the network because they don't like how things went. Even though Chia is not as vulnerable to the same problem, more full nodes make the network more secure. Perhaps doing something as simple as updating/clarifying the minimum recommended specs is good enough to tackle the weak node issue. IMHO only harvesters should run on RPi. Definitely agree on funding community development to add more software resiliency on the network. |
Beta Was this translation helpful? Give feedback.
-
|
Pools getting together and threatening to hijack the network? Worst thing they can do is to execute a 51% attack, which is basically a theft that no legal companies will accomplish. It is not an Eth2 beacon chain, where 66% control would literally allow to "print money out of nothing". |
Beta Was this translation helpful? Give feedback.
-
Sure, my post could be seen as combative, or rather written by an angry user. So, you could start with trying to understand where the anger comes from. Instead, you have decided to project what you do (e.g., what followed in your reply) on me. Also, I really appreciate that you took your precious time to respond. However, you could also try to respect the fact that you basically owe responses/updates to Chia community, as we farmers are overwhelmed with issues (ignored by your side) that your software has. Your $700 million network is run by us, farmers. With that said, as you tried to keep at least part of your answers light, let me also try to start like that. You would be surprised, but I was in charge of architecting P2P telephony network, and thus I was also working on simulating it. So, I am really grateful for the offer to be considered. However, what we did is not just simulating that network, but we also produced guidance for phone (node) requirements. That was easily done by starting with one node, and simulating several peers, where we could control the behavior of those simulating peers. The rest was just an extrapolation of our results, and it held rather well. That implies that you do not quite understand the difference between the node and the network simulation/testing, so maybe I am a bit overqualified here. As far as my anger, as much as I can, I am helping other farmers with their issues. Things are repeating with every single update, and every other new user. Most problems that I see are due to blockchain corruption. That happens on chia shutdowns, where Chia processes are losing synchronization, and not doing clean shutdowns, i.e., db owning processes just crashes (or is killed on reboot) without cleanly closing blockchain/wallet db. That was reported maybe in May, was on github Issues page, and as other things got ignored. You have just confirmed, that so far, that was MO for Chia (ignore all issues). I still think that you should do a simple tool that would check db integrity, as as far as I can tell, even if Chia software is running (seemingly) fine, that db corruption Is there. Potentially that problem is exacerbated during updates. Also, all other forks are offering blockchain db downloads, to speed up synchronization. That is another thing that would potentially help with cleaning up those dbs. Next big problem for me are logs. Of course, better documentation would help, but I would also encourage Chia, not just to flag entries with ERROR/WARN/INFO, but rather use a bitmask for those, plus add DEBUG/ALL levels as well. This way, farmers could dis-/enable some of those (not just go up/down a level), especially those that are purely meant to be developer logs. (A good example of such DEBUG log entry could be notification about peers barfing, as for P2P protocol that is just how it works, not really a concern). That was also brought up on github Issues page, but was way over the head for that guy to understand, or maybe as you stated – why bother approach. Logs are not really helping with performance, and under stress there are more logs, thus further degrading/overwhelming the systems. I had few exchanges with your devs/support people on github. Most what was brought up was brushed off, as my take is that it was over their heads. I was asked to look at their code, where hard coded numbers were all over the place, and the guy was wondering why when he changes one number it still doesn’t work. Every ten lines or so virtually the same code was duplicated. (I was taught that when you see hard coded numbers, you are fired, when you see the code repeating, you are fired, when you see warnings, you are fired – old school, I guess.) The code that I looked at (related to reported issues) was basically not production ready. This is just anecdotal, but there cases like that all over that forum. A couple of days ago, I was trying to help one farmer with his setup. He had a 500TB farm, but his pool (Flex) was reporting mostly around 5-10TB only. On the top of that, over 80% of his partials were stale. (No, it was not related to Dust Storm.) We turned every single component around, but all was sound. There was no one lead that would point us to any HW/networking issues. His box was running Ubuntu, 2x 12/24 cores Xeons, 512 RAM, 200Mbps up/down-stream network connection, all drives basically brand new, and tested well with hdparm, partial lookup times not the best, but still OK. We really couldn’t find anything. As a last option, he switched to Flex client. Right after that, pool recognized his farm size, and the number of his stale proofs went down to 0.04%. That is just one of many similar problems. If that doesn’t make you pause about what software quality you represent, how much it was neglected, I don’t know what else will. Another good example is adding password in the latest version. You can take a look at chiaforum.com how worthless that implementation is. This issue was also reported two/three months ago. The fact that any third-party software (that can be actually quite useful, e.g., farmr) has full access to mnemonics (in order to be useful) is just mind boggling. And without such software, Chia’s package is basically worthless as far as any debugging, or even status updates. As far as your rant about those 15 years old laptops, etc., that is just you continuing to spread FUD without providing any data (I guess, you are fed with that logic by your devs), plus deflecting the root cause, what is the poorly written code. My take is that potentially the main problem is the blockchain db not properly optimized, thus slowing down everything else (of course, slow underlying storage is not helping, no point to bang on that). With blockchain db growing, this problem will just continue to overwhelm whatever underlying storage is used to host it. Lastly, the person behind Dust Storm was interviewed today. Let me quote part of what he said: This is also what he said, and what I would like to being addressed. We already see pool separation, and it looks like it will not take long before we will see smaller pools dropping off. When you say that about 20% of users were affected, I assume that you infer that from the net space drop. Do you have more data about for instance what size of farms were mainly affected? My understanding is that a big chunk of net space belongs to few whales, and their nodes were intact (overbuilt systems). That would imply that in that 20% were more or less all average Joes. The fact that people were reporting stale partials, implies that their farms are below PB level, as more or less everything above that threshold are either OG or self-pooling farms. With all that being said, I would expect that in your updates, you put a bit more stress on farmers, not just pool operators. So, no I am not looking for any more exchanges. That is my last reply to you, and sorry for it being a bit long. I also don't expect a reply from you, hoping that this is the end of that exchange. Update: The first one is while using Chia (captured yesterday, just after upgrading to Flex - that sharp drop in stale partials): And here is what he has today (while with Flex client): Just mind boggling. Please, ignore the stale percentage in his latest chart, as it still includes residue while on Chia. There is a different screenshot in that thread that shows his box under two different names (name change happened when switching to Flex client), and on that one he has that 0.04% while on Flex. Here is that thread: |
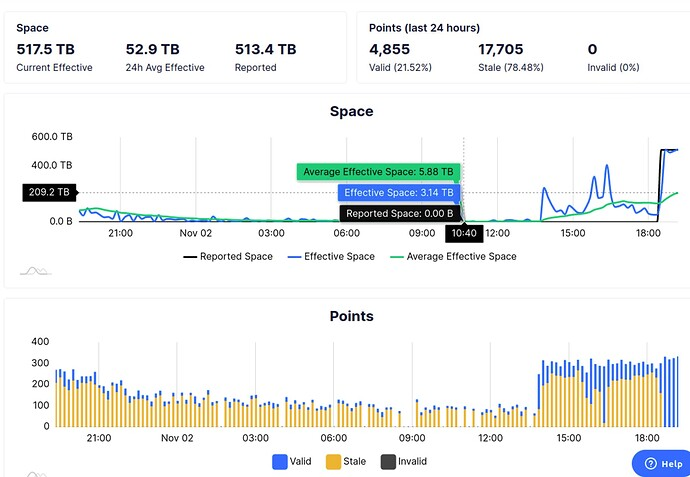

Beta Was this translation helpful? Give feedback.
-
|
Please stop and take a breath, on both sides. All the you's, I's, my's, rhetoric, and hyperbole is not a constructive way to communicate and only contributes to the toxic behaviors I'm seeing running rampant in this community. In pull requests and issues it is best to talk about the problem, not the person. |
Beta Was this translation helpful? Give feedback.
-
|
Chia could only be so lucky to have the success that Ethereum garners with an over 200K active developer community. Ethererum is and should be the measure that new POW/POS/POST blockchains seek to mimic to obtain the same kind of success. Ignoring what has and continues to work is to go on an unknown and risky path as we are now seeing. It is not too late to right this ship and move towards a better future. All that is needed is a simple public statement from the Chia team advising farmers with a node that "just isn't good enough" to move to pools that have developed Official Protocol solutions that allow them to farm without a node. |
Beta Was this translation helpful? Give feedback.
-
11/1 updateI wanted to give everyone a “day-after” update, since I’m sure you are all expecting one and we have some things to share as well. As I mentioned in my previous statement on Sunday, we’ve had a lot of the team heads down looking at things this weekend to find out what exactly the pain points were behind the more obvious symptoms you felt, and determined what we could be doing differently to alleviate them. All in all, machines that are above spec did fine through the Dust Storm (generally speaking, but there were more than a few who were above par but had a majority of node peers who were under powered and lagging behind, hurting them). On a whole, the chain continued to progress, and transactions were processed. However, there were some signs of slowdown here and there, nodes with weak peers struggled, there were some issues with signage points being out of order for otherwise healthy nodes, some pools felt pains that trickled down to their farmers, and transactions with no fees attached were delayed a few hours. The takeaway is this: While the chain remained strong and stable, it was not a great user experience for about 20% of you and had it continued on indefinitely, the symptoms while not catastrophic were unignorable, and we want to fix that. We have always known there was plenty of room for optimizations in how we do certain things, and like all software projects we balance going back and revisiting optimizations against new features we need to add to advance the software forward. Over time, we’ve done those things when we can, with the expectation we would phase in more optimizations gradually over time but ahead of the curve of the network load growth and need for them. However, this event pushed that timetable up dramatically shortening said curve, and so we shall do the same with our optimizations. Thanks to our anonymous tester, we now have zeroed in specifically on several areas of potential optimization. Some are pretty clear to us, some require further testing to validate. Over the course of this week we’ll be adding a few of these optimizations to the forthcoming 1.2.11 release that we were already planning to put out within the week. Others will come in subsequent patches, depending on the body of work and validation needed. The exact details of those changes I’m not prepared to go into right now, because some are still up in the air, but they will be covered in the release notes of those updates and any future post mortems we may do. Additional to this, the other fact of reality is that the heady days of constant zero-fee transactions are behind us. When the blocks are not full, one can still send a zero fee transaction and have it processed right away, however if another Dust Storm kicks up, then you will need to add fees to your transaction to jump ahead. Even the bare minimum of 0.00005 will be enough to jump ahead of a Duster, however. This also means that pools who did not already implement fee support into their back end operations need to add those as well, to avoid delays in times of congestion. From the looks of things, many of them did this over the weekend and those who haven’t yet are working on it. If you are wondering why your pool of choice seemingly never had an issue, well odds are they built from the ground up to always support fees and just turned them on when the need arises, while simultaneously having a node with already strong peers. We also have some work to do on our side regarding fees as well. Just like some pools did not yet implement fee support because it wasn’t a requirement and they opted to work on it later in the interests of rapid deployment, we too do not yet have fee support for plotNFT commands in the GUI and CLI. The functionality to support that does exist in the rpc code itself, but no user interface elements currently connect to that. We’ve got someone working on that as I post this as well, in parallel to the work being done for the optimizations. In the meantime, if you make a plotnft change, if there is low traffic it will still go through right away, if there is high traffic then it might take a few hours to process. Between these things, we expect to make meaningful changes over the coming days, as well as some reprioritizations over the coming weeks, that will reduce this pain. This will probably be the last “big” update I give on this, (unless things get spicy again) until we do a post mortem, though we’ll be around to answer questions where able. So in summary:
|
Beta Was this translation helpful? Give feedback.
-
|
Ironically, on october 31st, in the middle of the storm, I had my higher day reward from the pool, despite a 3% stale partials and a signage point mess all around the logs. If it had been a test, I'd have sayed you passed it. |
Beta Was this translation helpful? Give feedback.
-
|
when will release new version to fix the Dust Storm? |
Beta Was this translation helpful? Give feedback.
-
|
The Dust Storm can not be fixed. But it can be outranked in the transaction fee competation. |
Beta Was this translation helpful? Give feedback.
-
|
Yes there are performance improvements coming that will help significantly. |
Beta Was this translation helpful? Give feedback.
-
|
Dust Storm exposed two problems: 1. delayed transactions, 2. 10-20% of network went down. Transactions fees can easily address the first problem, you are right about it. However, the second problem is that just one guy in a basement using two wallets and running one script for a couple of hours at a time brought 20% of network down. I would also assume that behind that 20% of network that went down were about 50-70% of nodes (virtually all peers that were connecting to my node were the starving ones - based on 78 connected peers), as most of the nodes are on the low end of the spectrum. Imagine what would happen, if just people on this thread would pooled, and run that attack for a week (he/she has made the code available). This is the main problem. Nothing Else Matters / Metallica |
Beta Was this translation helpful? Give feedback.
-
|
There are some fixes that are going to help with network stability. I agree that 10-20% of space not being able to farm is not acceptable. |
Beta Was this translation helpful? Give feedback.
-
|
I appreciate your reply. However, let me try to restate what I wrote above. That 10-20% network space loss is not /may not be a big deal. However, the other side of this coin is that maybe 70-80% of nodes were broken, and I would worry about this number, as it points to a total network meltdown, if someone is more serious about hurting the network. That is the reason that I have asked for that farm size distribution for nodes that were behind. And again, the code that did this damage is already out. Anyone can rent 10-20 decent AWS instances, and run the hell out of that. This is the scary part, at least for me. As far as the fixes that you are working on, take a look at those two screenshots above, as those may give you an idea how much behind you are. |
Beta Was this translation helpful? Give feedback.
-
I would be very careful especially since Chia is a public company and could sue for damages from a DDOS type crypto attack. I would not doubt it if their lawyers are already looking into any legal avenues available to them for this attack. This is a little different than a normal crypto currency where it is decentralized and damages are hard to prove against a single entity. Chia is a centralized company and can sue for damages as noted many times already for name infringements. Whether they do or not is up to them. The recent $150,000 Ubisoft lawsuit comes to mind, there are others. |
Beta Was this translation helpful? Give feedback.
-
|
If you are trying to say that the situation is really serious, I am 100% with you. I am also 100% with you about reaching out to external developers. Most likely, those are solid engineers with already years of expertise. Chia's code is an open source, so that makes it even easier. As far as trying to sue:
|
Beta Was this translation helpful? Give feedback.
-
|
Hey, for me this is a problem now. I planed to run the full-node on a PI4 with 128GB SD Card. Now it sounds like that this is not possible because the software is too slow on lowend hardware (maybe because Python?). But if I want a energy efficient setup it makes no sense just because of inefficient software to add a ~ 100W CPU for a decent Price just for this task. And my main Computer is not running all the time (should not, that's why I want to move everything to the PI). This inefficiency makes small farming near impossible. My Computer eats more energy than the Storage. Even a 100W Nettop eats more Power than my HDDs. And turning off the farmer 18 hours a day makes also no sense. I am absolute clueless what to do now. Selling my 45TB drives and say good bye to this project? Or waiting a year to the point where the software got stable. And just a side note: Today my blockchain db got screwed. Needed to resync for no reasons. sqlite3 did not show any error on the database. Just the software did not connect to the network. Only removing the blockchain db fixed that problem. Annoying. No errors even in the log file... no connection and loading spinners all over the gui. 12h now to block 450000 with 100mbit network, m.2 SSD and Ryzen 5 3600XT with high CPU load and RAM usage with 10 start_full_node processes (each with 3-10% CPU usage and 50 to 400MB Ram)... no wonder that a PI would run out of breath. How long will that take in a year? one month? ^^ Just a lil disappointed User who solo farmed since April and replotts now for pooling. Feels like I was right with my skeptical view on python as the main language for a blockchain project. Greetings |
Beta Was this translation helpful? Give feedback.
-
From same page. |
Beta Was this translation helpful? Give feedback.
-
|
The pi itself seems to run fine, however the storage medium that you use does have a large impact. A pi with an SSD will perform much better than with a slow SD card. |
Beta Was this translation helpful? Give feedback.
-
Love it. Keep experimenting. |
Beta Was this translation helpful? Give feedback.
-
|
The problem with slow handling of mostly blockchain is not just RPis with SD cards. Looking at ChiaForum, more and more farmers running desktops that have their installation on hard drives experience problems. Hopefully, you can get a good db dev to optimize blockchain db, plus provide some utility to check that db for corruption. |
Beta Was this translation helpful? Give feedback.
-
|
Now that's a legit issue that was unexpected which dev team has promised to fix in 1.2.11, which is already out, and subsequent updates. |
Beta Was this translation helpful? Give feedback.
-
|
Also, Chia being Green isn't about a single <100TB farmer not wanting to sip another 100w-200w out of their system, it's on the aggregate level. Read https://www.chia.net/2021/10/20/mining-vs-farming.en.html for actual data and facts. |
Beta Was this translation helpful? Give feedback.
-
|
Here is my current status.
I was searching online for any clues, and found this answer on StackOverflow: I have tried to locate the source of that assertion, but failed (couldn't find anything on sqlite website). If that assertion about restarting the backup process on any db writes is correct, it implies that blockchain db, cannot be backed up by this tool. sqlite provides some backup API, but that would require code changes, as such that is not an end-user solution. I have tried to search for other options (replication), and found four commercial utilities, but gave up on those. So, at the moment, I believe that the best option would be to have Chia provide download link to somewhat latest db (as other forks are doing). Again, I don't know anything about sqlite. This is my very first time to deal with it, so maybe there are other solutions that actually work. @Dishwasha Than you for your help in this process. @hbroer Sorry for hijacking your thread |
Beta Was this translation helpful? Give feedback.
-
Agreed, that is rather a scary section.
This doesn't sound reassuring. We know that most people crash blockchain db handling processes on Chia restarts or reboots.
There is no data how much, how fast, so it is hard to say whether this is a serious degradation. There is potentially a remedy for that by running checkpoints. But again, just guessing, still it doesn't sound right. My take is that as with any db, you need a db expert to fine tune it, and possibly one that knows that db. If one has basically zero experience in that (knows only how to do selects and updates), that is just a shortcut to a disaster. |
Beta Was this translation helpful? Give feedback.
-
no problem ;-) I am playing around with one of my PI4 as a full_node at the moment. I added my main computer as a node to the Pi node and it is now syncing. And because you try to backup the blockchain db manually maybe it could be working this way too:
then every day or hour just stop the backup full_node, backup the database by file copy, start the node again. This way you might have always a live backup + some snapshots. With other databases than sqlite I would do something similar: Primary DB which replicates to a secondary. The secondary database is where the backup happens. The reason is that this will not affect the performance of the primary. I do the PI4 full_node because I want some "benchmarks" on the sync process. I log every minute the node status, cpu usage and the mem usage. Will do that with some other machines later too. Btw currently top shows mostly three chia_full_node_ processes with heavy load jumping between 0 and 100% and 8% to 14$ mem Usage per process (2GB Pi4): |
Beta Was this translation helpful? Give feedback.
-
|
Absolutely, what you stated is right. (Although, if you think that blockchain db downloaded from Chia.net could be poisoned, that also implies app download could be poisoned. Potentially, a PGP signature could help, but that is out of the scope of this thread.) However, all that is beside the point of this thread. We are not talking how things should work, but what doesn't work, and how to at least mitigate it. Let me quote a post from yesterday on ChiaForum:
Why do I, or other guys on the forum need to help such guy? Why do you need to spend your time explaining the basics? We all want Chia to succeed, but there should be some limits, where things are potentially easy to address. Starting with that, here are the problems that hit that forum basically daily.
Let's say that the very first two are a fresh starts (the whole blockchain needs to be download), and the last two are where the user has virtually up-to-speed db. I guess, we can agree that downloading a 30GB file should take less than an hour (say for 100Mbps download speed). Also, regardless of what storage is being used, it should also be less than an hour to write it. Assuming that the new setup is downloading that data from just one peer that has 5 Mbps upstream bandwidth, such download should take about 20 hours. Of course, those are ideal numbers, so we can add / remove some margins there, but we are nowhere close to a week without seeing the end of the process. This is the problem for the first two cases. As Chia default setup is to peer with 80 peers, potentially that 20 hours (using just one peer) could be shrunk to well below 1 hour using most of those peers. Again, an ideal number, but at least that one hour is a good target to have. For the last two cases there, we have two problems. The first is most likely a db corruption during Chia restarts / upgrades, the second is going into the slow download as in those first two cases recreating blockchain db from scratch. The software is not providing any indications what could be wrong, what just compounds those problems for those that are less "computer educated." Those problems were reported really long time ago, and as Sargonas stated, their priorities where elsewhere, so nothing has been done to address either those crashes / db corruption, or syncing speeds. As with every software, if a fix for a problem will take some considerable amount of time, then you try to figure out a work-around to mitigate that issue. Downloading that blockchain db is exactly mitigating those two issues for time being, without taking much (if any) time from the dev team. That's all. |
Beta Was this translation helpful? Give feedback.
-
That is an elegant home made basically master/slave replication solution. I think that instead of dealing with all that UPnP, etc., it would be enough to set "target_peer_count" to 3 in config.yaml (for local farmer, local wallet, and the last for the other node for syncing). That connection to the other node could be forced by using "CONNECT TO OTHER PEERS" button in Connections section. Also, based on the output you provided, it looks that RPi4 has plenty of room on the CPU side to be a full node. I guess, most people just don't realize that a slow SD card is what it is, a slow SD card and is not cutting. As such, just stating that one needs to boot maybe from something like V90 SD card, or rather an SSD/NVMe is what should be stated, not just bashing on low-performance nodes, where we know that the culprit is basically bad software. |
Beta Was this translation helpful? Give feedback.
-
|
Hi all, To return to the subject, DustStorm was well executed test with well executed response even though I was severely affected and I'm not a IT-guy. But from security stress testing of a system I know how bad/good execution/response looks like. Don't be afraid in testing underdog-project fanatics patience while you still can because in 2 years you won't be able to afford it and users will expect smooth sailing with 100% of the time ;) |
Beta Was this translation helpful? Give feedback.
-
|
I’m positive that there was some crazy engineer that proposed this on the meeting but was quickly thrown out the window by some conservative manager. |

Beta Was this translation helpful? Give feedback.
-
|
Hola, a todos, hay alguna forma de identificar el origen, a mi parecer solo es estrategia con la finalidad de cobrar x transacción, tanto rollo y poca solucion, no pueden o no quieren identificar al causante.... se esta volviendo ridiculo chia de 1500 Dolares a 80Dolares...... ya sabemos la codicia que abunda en el globo.... |
Beta Was this translation helpful? Give feedback.
-
Over the last 24 hours there has been a lot of discussion about the current state of the Chia blockchain, and we wanted to clear up some understanding about what is/isn't happening and what we are currently working on to address it.
Since mid afternoon on Saturday the 30th (PST) there has been increasing waves of transaction spam, what is also commonly known as a "Dust storm" on other crypto networks. This is when an individual user sends exceptionally large amounts of minimum sized transactions (in this case 1 mojo) to thousands of wallets, in an attempt to strain the network.
All they have really done, however, is take the unused overhead in each block that as of now was simply waiting to be filled with transactions and filled more of it. Generally speaking the chain has handled it well with most nodes keeping things running smoothly. Additionally, if users include fees with their transaction (a previously unneeded requirement due to market demands), then your transactions will leap ahead of the Duster’s and deprioritize them.
However, there are a decent number of nodes out there who are either running low performance nodes or are otherwise suboptimal in their configuration. (We are also currently investigating reports of edge cases where an optimal setup also struggles at times potentially.) These nodes are struggling to keep up, and as a result users dependent on them, either because it was their node for their network, or because their own node was peered with these nodes, are experiencing pain in staying synced and farming off of this node. This pain has naturally spread to some pool operators as well (especially those who did not include transaction fees support in their code), which depending on how their pool is built, may also impact their farmers.
While we trust the majority of the network to run smoothly and for the rest of it to self-heal from this, (and indeed it has in the pauses between each wave of these), we recognize the pain that it brings to a non trivial number of users is unacceptable from their point of view.
We have always known there was a lot of room for optimization in our code, particularly for full nodes running on low end hardware like Raspberry Pi4, and like all software projects we have to balance carefully between spending resources on optimization against adding critical new functionality. We recognize now that there is a significant need for more optimizations sooner than we anticipated, and are currently all hands on deck looking for ways to get out short term optimization tweaks as well as long term ones as well, to alleviate this pain for folks experiencing it.
While I don’t have specifics on what those are at this moment, rest assured the dev team is deep into looking into this as we share this, and we will have updates as they become available. One thing that is clear now however, is that the days of the "zero transaction fee" world are behind us. That unknown point on the horizon where TX Fees would be a normal thing, appears at this point to be today.
A quick Q&A:
Q: Why isn’t Chia capable of preventing this?
A: “Dust Storms” are a fact of life for any blockchain. They happen all the time, however the combination of transaction fees and decentralization minimize the impact to where you generally never see them. Because Chia is so new, we are still in the early stages of life where most blocks were partially empty and transaction fees were not needed. If anything, this will simply bring about the mainstream use of transaction fees sooner than later to alleviate the majority of it. It did however highlight certain opportunities for optimization we had not yet prioritized which we are looking into currently. (In fact, we already early-on implemented a "minimum" fee of 0.00005 for a 2 spend coin, by making anything lower than that all the way down to 1 mojo be treated all the same as 1 mojo, for the express purpose of making these kinds of Dust Storms cost prohibitive and preventing the "1 mojo, 2 mojo, 3 mojo" bidding wars.)
Q: What can I do to make sure my transactions go through?
A: All still are, though they might get delayed by a block or so. If you want one to go through ASAP, just include a transaction fee of 0.0001 or higher, and you will stand well above the dust noise. (Note that transaction fees below the minimum are all considered 0. There is no real difference between a 1 mojo transaction fee and a 100 mojo transaction fee.)
Q: My pool isn’t paying me as fast as they usually do, or calculating my rewards as quickly.
A: This is to be expected, since they are relying on transactions to execute operations, and their nodes may be peered with slow nodes affected. We are working with the pool operator community to help them implement transaction fees (for the ones who did not already have them) to prioritize their transactions. Rest assured your pool likely has your best interests in mind and is working to get your experience back to what you are used to, but also please note these last few months have been an unusual world of “zero-fee transactions” that was bound to end sooner or later, which would require a shift in end-user expectations at some point.
Q: I’m running a node on a Pi, what can I do to make it better in light of this?
A: We’re still trying to understand which changes will and won’t make a difference in handling this for individuals on the lower end of the spectrum, but we will update you with more constructive guidance once we have hard facts. Some obvious ones that are good standards regardless are to run your node DB off of an SSD, NOT the internal SD card. Finally, run the CLI version of Chia, not the GUI. In the meantime, while it is a suboptimal answer, if you DO have stronger hardware available than the Pi for running a node, we advise moving to that for the time being. You can often just transition your Pi to a remote harvester and farm from a more powerful node.
Q: If I’m feeling strain on my node, is there anything I can do to alleviate it?
A: You can lower your default peer count in config.yaml from 80 to something smaller, like 40 or 50 for example, or maybe lower based on your needs. Additionally you can monitor your peer connections and if you see peers that are woefully behind in blocks, and if they show no signs of catching up and are not benefitting from you and only dragging you down, you have the option to terminate their connection from the CLI. (Please only do this for nodes sandbagging you however. If you see peers slowly catching up thanks to you, be a good neighbor and help them!) Also, if you are plotting on the same machine that is your node, you could try splitting the workload between machines or temporarily pausing plotting while your node catches up. Lastly, while we encourage and support the spirit of Chia Forks, halting them on your machine and freeing up resources for Chia specifically will obviously help, especially if you are one of those power users farming 10+ forks on one machine!
Q: Where can I get more information on what is happening as it unfolds?
A: You are welcome to swing through our Keybase server, where many of the team is interacting in real time with advice and support where we can provide it, in both the #general and #support channels. The most up-to-date announcements will likely hit there first in the #announcements channel before we distill them down into updates elsewhere.
Q: You mention making optimizations to the network because of this. Does this mean a fork is coming?
A: No. Chia was built in such a way that there are a great number of things we can improve and modify without the need for a network fork. Forking the chain has, and will always be, a “break glass in case of emergency” solution to a critical situation, not a “make-things-easy” tool for tough problems.
Q: I’m a pool operator, what can/should I be doing right now?
A: First off, reach out to TheSargonas on Keybase and get added to our pool operators group, so you can stay in touch with us and other pool ops in real time, this should be useful overall and not just for this event. Primarily however, make sure you are including transaction fees going forward. Pools who had implemented them last night after the first wave of this have experienced little to no trouble at all when the bigger waves hit. Secondly, re-examine your node configuration. Months back at the onset, some of the pool operators out there deployed nodes in the cloud using low-spec instances, because at the time it was all they needed. As the weeks and months went by, tribal knowledge meant they just honestly forgot to revisit that. Make sure your pool nodes are configured with the power they need and maybe even some auto scaling where possible.
Beta Was this translation helpful? Give feedback.
All reactions