上一次,我写了一篇《Data URL的简介与使用》,该文章主要介绍了什么是Data URL,其优缺点及可以如何使用。其中有一个隐含在文中的重要概念,那就是Data URL是Base64编码的,且Base64编码的数据体积通常是原数据的体积4/3。
不知道大家会不会有这样的疑问:
- 为什么图片转成Base64编码,就可以直接内联到HTML中显示呢?
- 为什么Base64编码后,体积会增大1/3呢?
如果你对此也有疑问的话,就往下一看究竟吧。
我们知道HTTP协议是文本协议,不同于常规的二进制协议那样直接进行二进制传输。Base64编码是从二进制到字符的过程,可用于在HTTP环境下传递较长的标识信息。
首先Base64是一种编码算法,为什么叫做Base64呢?其实原因也很简单,是因为该算法共包含64个字符。包括大小写拉丁字母各26个、数字10个、加号+和斜杠/,共64个字符。此外还有等号=用来作为后缀用途。
字符与索引的对应关系如下图所示。
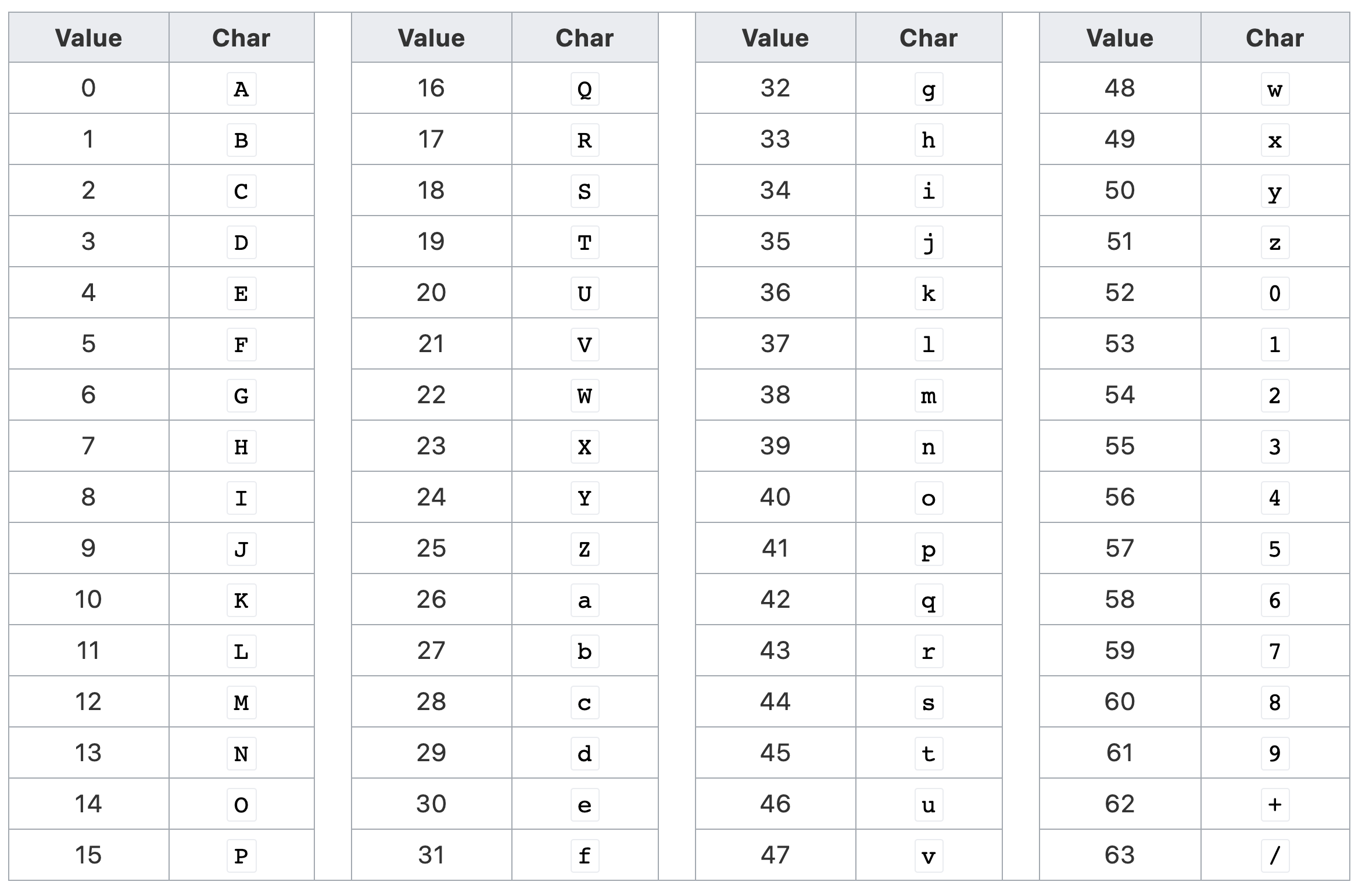
但,为什么Base64编码算法只支持64个字符呢?
首先,我们先回顾下ASCII码。ASCII码的范围是0-127,其中0-31和127是控制字符,共33个。其余95个,即32-126是可打印字符,包括数字、大小写字母、常用符号等。如下图所示,图片来源(https://zh.wikipedia.org/wiki/ASCII)。
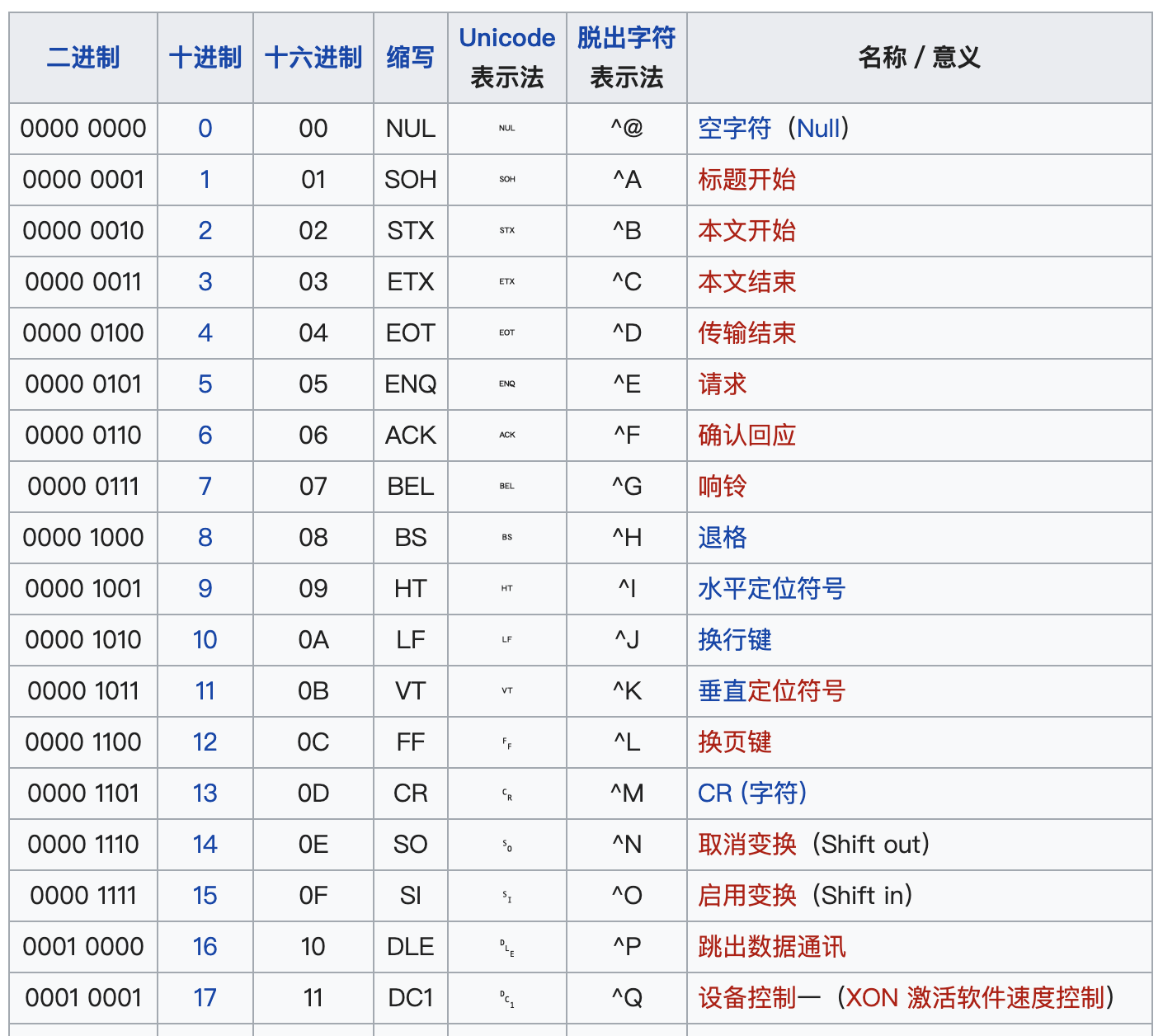
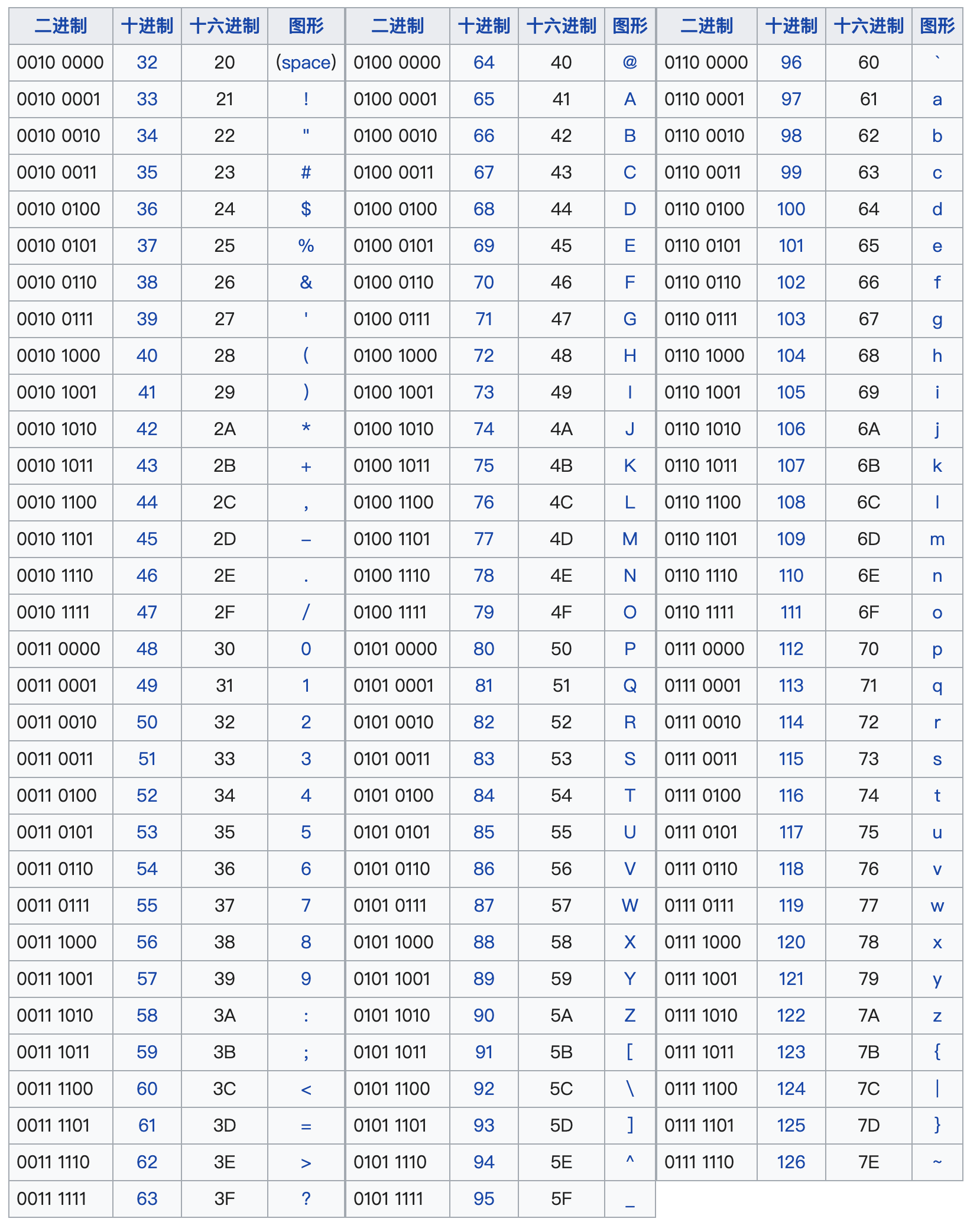
早期的一些传输协议,例如邮件传输协议SMTP,只能传输可打印的ASCII字符。这样原本的8bit字节码(0-255)就会超出使用范围,从而到这无法传输。
这时,就产生了Base64编码,它利用6bit字符来表达原本的8bit字符。
上面我们知道了什么是Base64编码,知道了其包含的64个字符。它主要是通过6bit字符来表达原本的8bit字符。接下来我们一起学习下这一过程是如何进行的。
首先,6bit显然不够容纳8bit的数据。6和8的最小公倍数是24,所以我们用4个Base64字符刚好能够表示三个传统的8bit字符。如下所示,字符串Man的编码图解如下:
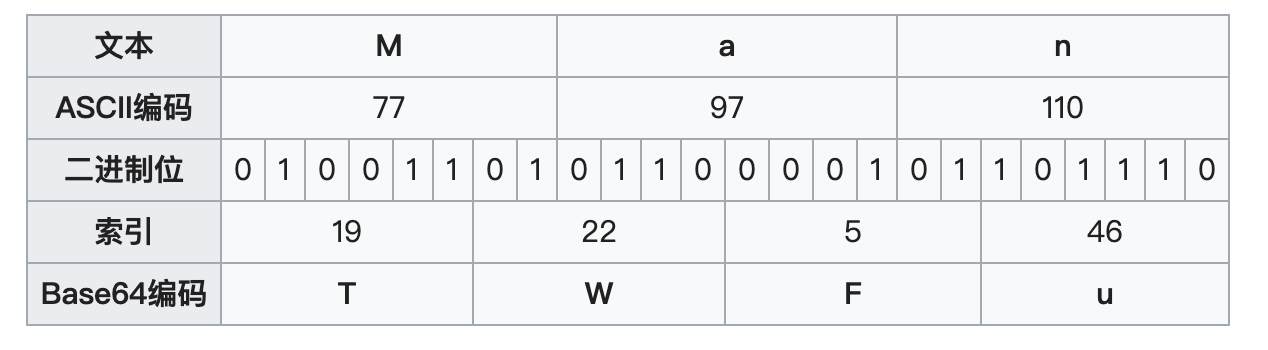
Man的编码结果为TWFu,显然,Base64编码会多1/3的长度,这也解释了文中开头的疑问,为什么Base64编码后的体积会大1/3。
Man这个字符串的长度刚好是3,我们能用4个Base64来表示。如果待编码的字符串长度不是三的倍数时应该怎么处理呢?
这是需要做一个特殊处理,假设带编码字符串长度为10。这前9个字符可以用12个Base64字符表示。第10个字符的前6bit作为一个Base64字符,剩下的2bit后面需要先补0,补到6位(此处补4个0)作为第二个Base64字符,至于第三个和第四个Base64字符,虽然没有相对应的内容,我们仍需以=填充。
如下图所示,A对应的Base64编码为QQ==,BC对应的Base64编码为QkM=。

最后的问题就是解码啦,解码的过程比较简单。去掉末尾的等号=。剩下的Base64字符,每8bit组成一个8bit字节,最后剩余不足8位的丢弃即可。
本文篇幅较短,旨在简单介绍Base64编码原理。相信看完之后,大家一定能够理解为什么Base64编码后体积会增大1/3,而不再是死记硬背这一特点。至少有这个收获就够啦。