json std lib slow #51
Comments
|
Hi @ziodave, thanks for pointing this out! |
|
For the time being, switching to orjson brought a great advantage. The profiling now shows that the SPARQL queries are slowing down the initial indexing. The queries are being cached in memory, probably storing them as file caches (and even pushing them to a GH repo) would help. I'll create a new issue for this ;-) |
|
Apologies for spying on this conversation (I have a github scraper setup so I can see how people are using
Just a quick clarifying point - In [1]: import msgspec
In [2]: msgspec.json.decode(b'{"hello": "world"}')
Out[2]: {'hello': 'world'}A schema will speed things up further (and provide some guard rails for malformed data), but even without a schema Either |
|
Thanks @jcrist, yes I started adding the schema as an improvement I am testing out on the languagemodel (along with reactive rxpy) and so far the profiler looks promising :-) |
|
And now that I added some multiproc, we're back at that :-)
|
|
@jcrist is there a way to ignore a typed value when the type is unknown? Right now I get this error: But I don't care about |
|
I ended up defining it. So far so good ...
|

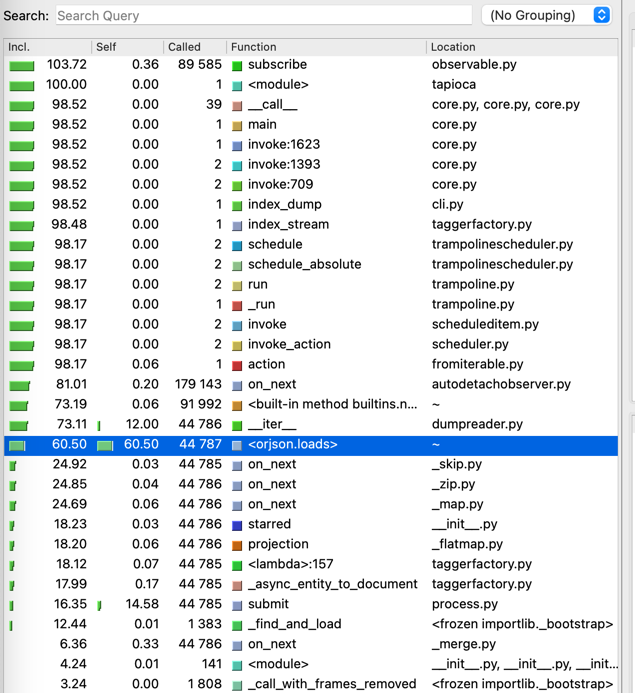
I ran a cProfile session and found that half of the time is spent within the JSON loads.
While a quick replacement of json with orjson brings improvements, if we could switch to msgspec we could seriously improve the indexing performance:
https://pythonspeed.com/articles/faster-python-json-parsing/
https://jcristharif.com/msgspec/
Only thing
msgspecrequires the json schema, as far as I could see these are the required fields:Am I missing something?
The text was updated successfully, but these errors were encountered: