Disambiguation #33
Comments
|
It's hard to say looking at a single example! In general I would recommend training a model for a specific domain (which would also let you select more finely which entities can be annotated). |
|
@wetneb is there a reason you're not using the edges in OpenTapioca/Wikidata to run the classifier? Did you try already? |
|
How would you turn them into features? |
|
I am not sure, I am trying to understand how to solve the above reference case. I can see the Apple Inc. (Q312) has an edge to Steve Jobs (Q19837) and viceversa. I am trying to understand if we can use these edges to perform the training. Because the training is extremely complex on larger datasets, involving first the dbpedia.org to wikidata.org item id mapping and then the classification. And I am afraid that SVM is not suitable for classification of large datasets. |
|
Yes edges are used, not directly as features of the classifier, but to foster the score of collections of mentions that are interlinked. It's something I tried to explain in the paper but things might well be unclear there, let me know if I can clarify aspects of that. |
|
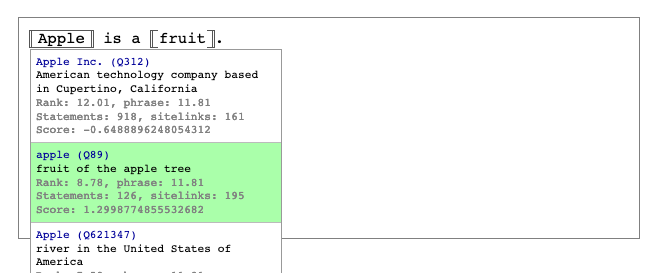
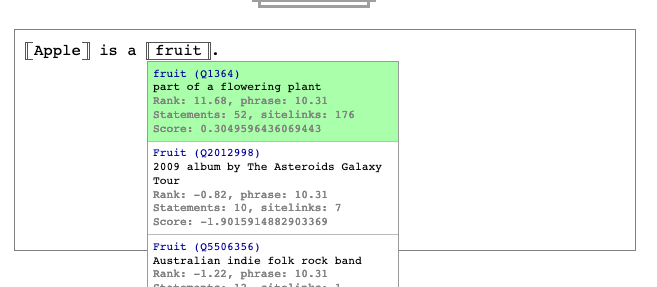
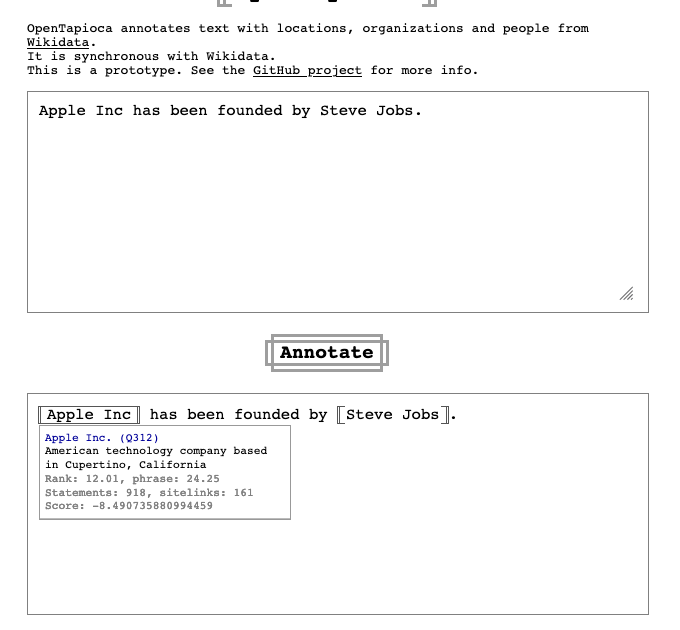
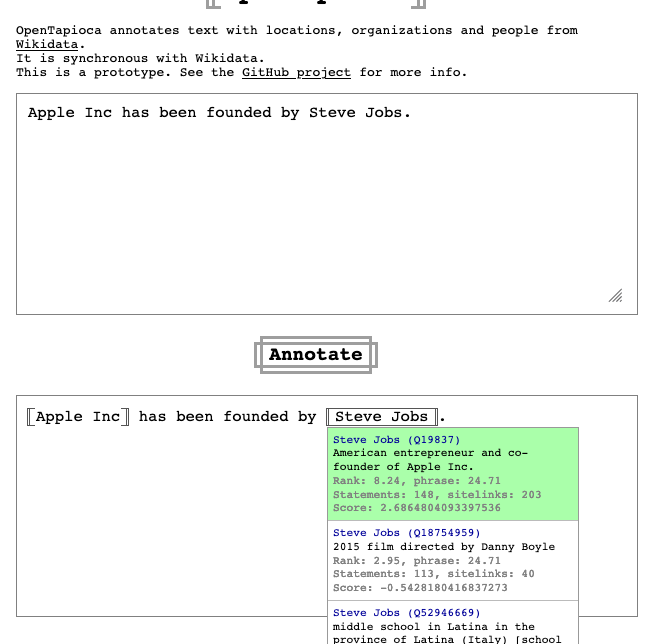
I see. I think there some tuning to do then, take for example this scenario: "Apple is a fruit", works nicely:
"Apple Inc has been founded by Steve Jobs", works nicely:
but "Apple has been founded by Steve Jobs", doesn't work nicely:
The only thing that's changing is that "Apple" in the second case is an alias of "Apple Inc.". As far as I understand from the paper though aliases have the same score as labels? Should the "Apple has been founded by Steve Jobs" actually yield the same results as "Apple Inc has been founded by Steve Jobs"? |
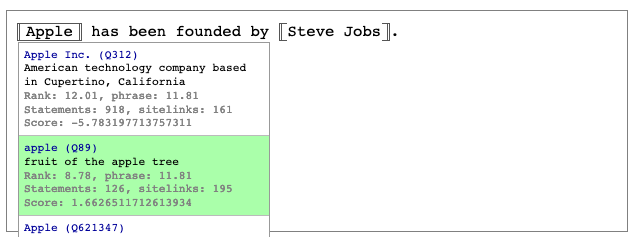
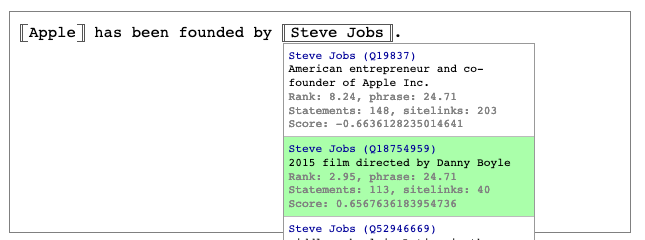
|
Yes it's a curious result, I would definitely expect "Apple has been founded by Steve Jobs" to be understood correctly. I think the training set probably did not contain extremely famous companies or people like those, so they are outliers that aren't scored well by the classifier. |
|
Yes, and this is the path that I followed, I thought I could find a better dataset for training, but this increases complexity. And then I thought is there a way to optimize cases similar to this one? at the end 'Apple' is just an alias of 'Apple Inc.' :-) |
|
I don't know exactly what you mean by optimize cases similar to this one - do you mean tweaking the classifier parameters manually to adjust for those cases? |
|
Yes, sorry. But is this a classifier issue? "Apple Inc" is detected while "Apple" as alias isn't. Sorry, I might not be to expert with the classifier. I am asking a colleague of mine to join this thread too. |
|
"Apple Inc" is more specific than "Apple" so it is normal that is detected more easily. |
I think the reason of not working fine for some cases is not necessarily classification. Changing the parameters may further reduce the evaluation metrics and as a result, be less accurate about things that already work well. |
Hello @wetneb,
Can the following be improved or fixed by running the classifier on a larger dataset? or is it only based on the number of statements for each entity?
Cheers,
David
The text was updated successfully, but these errors were encountered: