Model export / import #339
Comments
|
hi @credo99, thanks for reaching out and suggesting these improvements. Adding a button in the precision evaluation screen sounds like a good idea and we will implement it soon. As for 2, each category has its own model that improves as more labeled data is collected. So we are not sure we understand the use case for importing an older model to improve its quality further, can you elaborate more on the use case? |
|
Hi Alon, I will detail below the scenarios / motivation regarding the second part of the above request although it partially reffers also to the issue related to the precision variation discussed in the part 1 of the request: I am using large datasets of medical data (text chunks) that I am attempting to classify into multiple labels (something like diagnoses). My datasets are not homogenous in terms of information quality so it might happen that I have a block of 100 text chunks that are quite informative in terms of conveying information about what is needed for a Correct / Incorrect labelling so the model precision progressively rises to a maximum after let's say each 20-pieces block from this 100 dataset (it can be be also blocks of hundreds or thousands). I one of my cases I reached a precision of 90%. After this block I might stumble upon another 100 (or 1000) block of "incoherent"/incomplete text chunks in terms of conveyed information and by labelling these "bad" chunks I "pollute" the previous model consistency and I reach a 70% precision that lasts for hundreds or thousands of chunks and in the best case it might rise to 85%. Let's suppose I exported the 90% model after it's evaluation. It would be useful if I could re-import it, stop the work of training it for label A (the process that reached a 90% precision) and start the training for label B (remember that I mentioned that I am always working on multiple labeles on the same workspace so usually I am training for label A, reaching a desired precision and then going on with label B and so on). If I drop from 90% to 70% in a couple of minutes and then it takes hours or even days of training to reach again something close to that lost precision in order to start the work for the next label it would be quite tiresome. |
|
Hi again, I saw that another enhancement suggestion from martinscooper (#356) point somehow in the same direction of a future version of label-sleuth that would allow multilabelling, in case this (multilabelling) is on your roadmap please merge the ideas originating from our suggestions so that redundant functionalities should be avoided. Thanks |
|
hi @credo99, apologies for missing your responses. A few comments:
|
|
Hi, regarding the suggestions for multi-labeling, I would like to attach a brief functional requirements set and also some UI suggestions (that of course should be considered only as recomendations, the final implementation is totally under your guidance). These requirements come from my work in the last 5 years with multi-labelling (or multi-classification) tools / environments. I have not included in the requirements the option for loading datasets that are already human-labelled AND tagged as label-sleuth-labelled that would trigger an automatic model generation process from Label Sleuth (as per my email conversations with Yannis). I have kept the requirement for model version export after a new version is generated as per my previous request, it is even more important when one works with tens or hundred of labels and misses a manual export just after a new version is generated, otherwise one should have to wait a tremendous time after a subsequent model version is generated. Please tell me how to attach a pdf file here since I see only image or movie attachment options. Thank you |
|
hi @credo99, I was under the impression that you can upload a pdf by dragging it to the comment box. If that doesn't work, another option is to send your document in the Slack workspace and continue the discussion there. |
|
Hi, I am ading here the requirements document, it contains basically a workflow description for multi-labeling. Thanks. Radu |
Is your feature request related to a problem?
After using quite intensive Label Sleuth for a while in text classification projects that require consecutive generation evaluation of multiple models that suffer significant precision accuracy variation through model generations I realized that if I forget to export the model I was just finishing to evaluate and I step towards the next generation by using the "Label Next" workflow I will be never be able to export the evaluated model since the generation of a new one is already started. So, in a concrete case I "lost" a 90% precision model by not exporting it immediately after the evaluation process since all the consecutive models to that one dropped to 75-85% maximum.
So I propose a two-step enhancement process (if it's doable in a single software iteration even better):
What is the expected behavior?
Step one: Automatic model export at the end of a evaluation process. Once the "Submit" link is clicked the application should either directly or through a modal "Do you want to export the evaluated model? Yes / No" dialog export the model in the same format is exported through the left-frame "Download model" option BUT with a slightly enhancement to the model zip filename that describes the precision, instead the current format: model-category_Birds-version_1-27_1_2023.zip to model-category_Birds-version_1_70_pct_precision-27_1_2023.zip. In the first step it would suffice an automatic model export (without modal dialogue). Please see the attached mockup: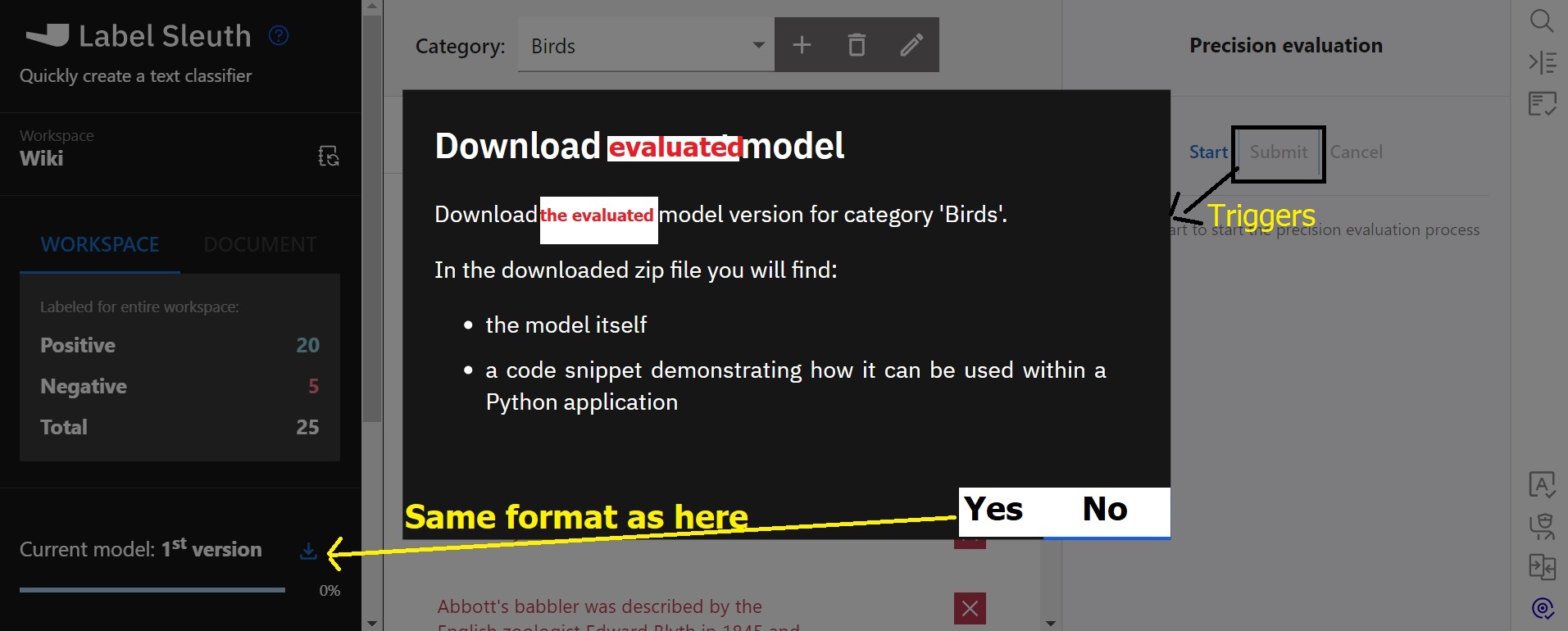
Second step: Model re-import. Continuing the above recommendation, once a high precision model was generated / evaluated / exported it makes sense IMHO to be able to import it in the workspace in order to attempt even further precision enhancement starting from the current one or to continue the labelling process using a different label category (in my case I am using multiple labels in the workspace). That would require a more complex development since from my analysis on the workspace-related files there are several places where json content should be modified in order to "return" to an older model generation. Apart from this (this is just my personal assumption, maybe I am wrong), the workspace configuration should fit the model, i.e., if the model was exported from a configuration using Naive Bayes over BOW it would make sense NOT to allow import in a workspace based on SVM Ensemble. Maybe checking the workspace id to be same in the current workspace and the imported zip file would be required. The user should be informed through a dialogue that he has to take the precaution that the workspace and the to-be-imported model should fitin terms of dataset / model algorithm.
Thank you
Radu
The text was updated successfully, but these errors were encountered: