This repo has code and pretrained models in support of the paper Representation Mixing for TTS Synthesis
Samples site: https://s3.amazonaws.com/representation-mixing-site/index.html
Recent character and phoneme-based parametric TTS systems using deep learning have shown strong performance in natural speech generation. However, the choice between character or phoneme input can create serious limitations for practical deployment, as direct control of pronunciation is crucial in certain cases. We demonstrate a simple method for combining multiple types of linguistic information in a single encoder, named representation mixing, enabling flexible choice between character, phoneme, or mixed representations during inference. Experiments and user studies on a public audiobook corpus show the efficacy of our approach.

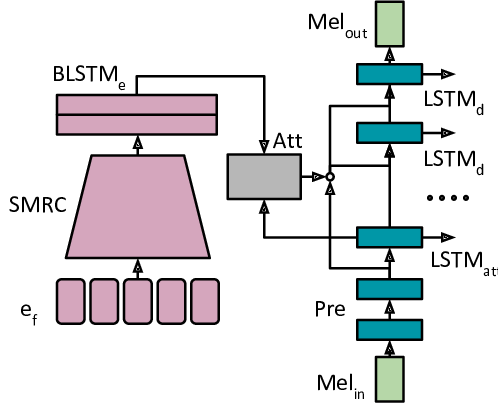
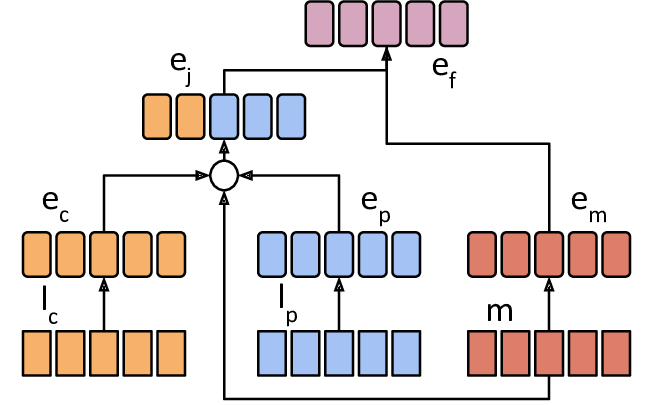
pretrained/ contains some information and code for pretrained models, as well as a colab notebook for sampling from the pretrained model
code/ (will) contain a NON-RUNNABLE code dump of my research library used for training the model. This is only for very, very interested people and for seeing the model definition in code. If you just want sound, use the colab.