Handling missing printers #394
Comments
|
We have some of the same considerations in our environment, and that is what has prompted a good part of the development work with the In our case we have a shipping department that uses a small Zebra label printer (Local USB) to print some 1x4" labels that are used during the checking/shipping process. Our development computers don't have these printers attached. Some of the initial challenges involved reading and writing the DevMode structures, serializing the data and reconstructing the DevMode blocks in the form/report export files. You can find a lot of the details and implementations in the One of the tricky parts here is that a printer can store some fancy driver-specific settings that aren't included in the typical DevMode API structures. You would almost have to interact with the driver itself to query/set these values. (Probably way out of scope for this project.) On the practical side, here are a few things that I have found helpful in maintaining applications that use specific printer and report settings.
From what I recall from the last time I worked on it, the part I am still having some issues with is that some printer setting don't seem to be represented in the export file DevMode blocks. I had to manually select those options again after deploying an update of the database. A more recent issue was the need to print a certain report as duplex and stapled. We created a specially named printer specifically for this need, and configured the stapling through the driver software. For the duplex printing, we used some code to turn the duplexing on when printing that report. The trick there is that we needed to open the report and set the duplex on the ' Open report in hidden view
DoCmd.OpenReport "rptEvals", acViewReport, , "EvalsID=" & lngEval, acHidden
' Set Duplex for double-sided printing
Reports("rptEvals").Printer.Duplex = acPRDPHorizontal
' Print report
DoCmd.OpenReport "rptEvals", acNormal, , "EvalsID=" & lngEval, acHidden
' Close report
DoCmd.Close acReport, "rptEvals"Hope that helps!! |
|
The printer-specific settings are all stored in the However, I believe the add-in strips the NOTE: I'm still not using this add-in in my daily work (I still have to migrate all of my existing repositories to handle the naming convention differences from my current homegrown solution), so I'm assuming an awful lot about how the add-in currently works. |
|
Just to clarify on the actual behavior of the add-in, if you have the option set to save print settings, it parses out the DevMode structures and serializes them into a JSON companion file with user-friendly names. During import, this is reconstructed back into a {
"Info": {
"Class": "clsDbReport",
"Description": "TrainingCertificate Print Settings"
},
"Items": {
"Printer": {
"Orientation": "Landscape",
"PaperSize": "Letter"
},
"Margins": {
"LeftMargin": 1,
"TopMargin": 0.7,
"RightMargin": 1,
"BotMargin": 1.1,
"DataOnly": false,
"Width": 8.9667,
"Height": 2.0521,
"DefaultSize": true,
"Columns": 1,
"ColumnSpacing": 0.25,
"RowSpacing": 0,
"ItemLayout": "Horizontal Columns",
"FastPrint": 1,
"Datasheet": 1
}
}
} ' Add DevMode structures back into forms/reports
Select Case intType
Case acForm, acReport
'Insert print settings (if needed)
If Not (cDbObjectClass Is Nothing) Then
With New clsDevMode
' Manually build the print settings file path since we don't have
' a database object we can use with the clsDevMode.GetPrintSettingsFileName
strPrintSettingsFile = cDbObjectClass.BaseFolder & GetSafeFileName(strName) & ".json"
Set dFile = ReadJsonFile(strPrintSettingsFile)
' Check to ensure dictionary was loaded
If Not (dFile Is Nothing) Then
' Insert DevMode structures into file before importing.
' Load default printer settings, then overlay
' settings saved with report.
.ApplySettings dFile("Items")
' Insert the settings into a combined export file.
strSourceFile = .AddToExportFile(strFile)
End If
End With
End If
End SelectThis approach gives you the benefits of eliminating the noise inherent in the binary content, especially when working on the same project with different computers, and also providing a very human-readable format to spot changes in printer settings. When a report is saved targeting a specific printer, some additional fields are present in the json file. The add-in attempts to locate the specified printer device by name, and builds the {
"Info": {
"Class": "clsDbReport",
"Description": "rptCheckLabel Print Settings"
},
"Items": {
"Device": {
"DriverName": "winspool",
"DeviceName": "\\\\computer-name\\ZDesigner LP 2844-Z",
"Port": "USB002",
"Default": false
},
"Printer": {
"Orientation": "Portrait",
"PaperSize": 257,
"FormName": "4x1 Label"
},
"Margins": {
"LeftMargin": 0.1,
"TopMargin": 0.1,
"RightMargin": 0.1,
"BotMargin": 0.1,
"DataOnly": false,
"Width": 3.666,
"Height": 0.8326,
"DefaultSize": true,
"Columns": 1,
"ColumnSpacing": 0.25,
"RowSpacing": 0,
"ItemLayout": "Horizontal Columns",
"FastPrint": 1,
"Datasheet": 1
}
}
} ' Set the properties in the DevNames structure.
' Note that this simply sets the printer to one with a matching name. It doesn't try to reconstruct
' an identical share and port name or install a missing printer.
strPrinter = dNZ(dSettings, "Device\DeviceName")
If strPrinter = vbNullString Then
' Use default printer
LoadFromDefaultPrinter
' Clear the device name, since we are not binding this
' form/report to a specific printer.
For intCnt = 1 To 32
m_tDevMode.strDeviceName(intCnt) = 0
Next intCnt
Else
' Load defaults from specific printer
LoadFromPrinter strPrinter
End IfAll in all, it seems to work quite well in my environment and allows applications to be deployed to people with different default printers and some reports that use specific settings like page orientation or custom margins. All this is saved and reconstructed using the companion JSON files. The place where it starts getting a little tricky is when you are trying to save printer settings that are outside the normal Windows |
|
I could look into setting printers but from our experience, the client would probably balk at the idea of setting up a shared printer just to support development especially because printers often becomes a source of problems and they'd rather minimize the problems. They're quite antsy at any idea of changing anything about the printers because the printers are so temperamental that if you just look at it funny, it spaz out. My client would love to recreate that fax scene from Office Space. I certainly can empathize! Retaining the printer data is a problem also because if the printer is not present, the So even if we retained the original binary, it wouldn't be a solution because this dialog will get thrown up and gumming up what should be otherwise an automated process. I'm aware that it's possible to set the printer data using the |
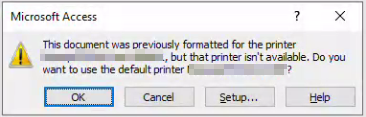
|
I'm asking to see if others observe the same thing I just discovered. You know how when you use This also explains why after clicking If this observation is true, it implies there exists a path for retaining the printer data even if it's not available but want to see if others can confirm this observation. |
|
@joyfullservice, need a bit of guidance. The idea was to enable a per-object setting (similar to Table Data) that would only change the printer settings when exported singly. Here's a screenshot: However, exporting is complicated by the fact that we may export it as part of the indexing or conflict operation and then use that file instead of repeating the export. I'm not sure if the hashing will be affected as well. The idea was to set a flag indicating that this is an explicit export, which would be true only when doing a single export and false otherwise. This way, the report ( or form ) will not be exported and therefore generate unnecessary changes to the printer settings especially if it's coming from a computer that doesn't have the printer attached. However, I'm a bit fuzzy on how this will affect the index, the conflict resolution and hashing. What would be your advice for handling those additional services? |

|
@bclothier - Great question! If you don't mind, maybe I could just step back a bit and reflect on the bigger picture here. At the end of the day, the client needs to have a database that works with their custom reports on their custom printers. From a development standpoint, the development work on the custom reports is probably going to have to take place on the computer that has the printer available. I think that's pretty much a given. Building from source on a different computer is going to be a little tricky because the printer isn't available when importing the report objects from source. For the sake of example, let's say you have three workstations (W1, W2, and W3) that each use a custom printer (P1, P2, P3, respectively) and they all have custom reports formatted for their custom printers. Realistically, the report development has to be done on the respective computer. You can't customize P3 on W1. You also can't do a full build on any of these workstations because they don't have all the printers available. That's where the Merge Build comes in. Rather than building the entire database from scratch each time you bring in some source changes, you are simply merging the changed source files into the existing database. Let's say that all three workstations have a fully functioning build. On W1 you update the login form that is used on all three systems. A full build is not going to help you because the export of W1 will not build P3 on W3. But a merge build will simply merge that one changed source file into W2 and W3 without touching P2 or P3. As far as how this works on a practical level, here is what I envision:
That's great for a shared form, you might say, but what about changes to the reports?
I believe the new Merge Build functionality will allow us to solve some of these complex multi-system scenarios while still enjoying the benefits of version control. Rather than carefully selecting what I export, I instead chose carefully what I commit to the VCS repository. I can do full builds and full exports from any of the three computers, I just have to be careful not to commit P3 from W1. My main repository branch will contain the source of P1 from W1, P2 from W2 and P3 from W3. After the initial build and export, the index will help manage the changes and most of the time you won't even see any changes to the objects that you were not actually changing from a development standpoint. In GitHub Desktop, you can leave certain files unchecked, and they will not be included in the commit. This checked/unchecked state is preserved between sessions, so in our example scenario, on W1 I would really only have to uncheck the reports for P2 and P3 once. They would stay unchecked, while new changes to the login form would show up as checked (to include) by default.
As to the functionality of the index, I should probably write a wiki page at some point explaining the technical specifics, but let me see if I can briefly summarize it here. Essentially the index serves as the intermediary third reference in the state between the source files and the database objects. When you export an object, the index is updated to reflect the state of the source file and the database object at the time of the export. The hash allows us to save a representation of the object or file at that state, in a way where the hash would be different if the object was modified or the source file was changed. The index is the essential component that allows us to determine whether a database object has been modified since the last export, or whether a source file has been changed. We can also determine if there are changes in both places, which is where the conflicts screen is used. More than once this has saved me from accidentally overwriting my work, either in the database, or in the source files. Let me know what you think about the above workflow concept in relation to your client's environment. It would require this add-in and a VCS client to be installed on each workstation where development happens, but I think you would probably be doing that anyway. It would also depend on the merge functionality, but that is getting pretty close to being fully functional. (I know some others are really looking forward to this as well.) |

|
Glad I asked. I was aware that you were working on this and based on your description, I think I need to revisit this again. My concern is that from my earlier observations (which may be flawed or skewed as I wasn't using merge build and was using full export out of paranoia) that when working on different workstations, the reports are altered and therefore shows up in the commit as modified when in fact we do not want those changes to be committed. As you noted, it should mean that they should not be committed. My goal is to ensure they never get exported when they shouldn't and thus contain unwanted changes to show up in the commit. One reason for that is to make it easier for other people to follow the workflow of exporting, then committing with minimum number of steps. If they have to use the patch functionality and individually review the changed files in the commit step, that would be error-prone, especially for reports (and maybe form?) where as you described shouldn't be edited on other workstations for which the printer isn't attached. This would the case regardless of which client they happened to be using. That said, I think they have to be in habit of reviewing their commits anyway and to not blindly dump everything and therefore make the history resemble something like the snow on the old cathode tube TV. I'll have another think about it and get back to you on this workflow. Thanks again! |
Given the following scenario:
In this scenario, building a file from source will not be equal to the original file because the printer data will be lost. During the loading of printer data, the routine attempt to locate the printer and fails to find any. A warning is generated in the build log. Therefore, no printer data is set/retained.
My concern is that this can mangle those specialized reports that were formatted for printers that we don't have access to on the development workstation. Normally, if there's any edits needing to be done on those reports, it's tested on the workstation with such printer attached and only when it's available for use. Those reports should never be edited on the development workstation. If those are opened for some reason, it will throw a dialog asking to change printer in which case, the correct response is to cancel and not open/save the report.
I quite like that the addin is able to import reports without throwing that annoying dialog but unfortunately we need to be able to retain the printer data.
So the question is -- has this scenario been considered and whether it's feasible to solve for this scenario? Reports are not my forté and I'm not sure if it's possible to retain the printer data without having the printer present.
The text was updated successfully, but these errors were encountered: