A package which efficiently applies any function to a pandas dataframe or series in the fastest available manner.




To know about latest improvements, please check the changelog.
Further documentations on swifter is available here.
Check out the examples notebook, along with the speed benchmark notebook. The benchmarks are created using the library perfplot.
$ pip install -U pandas # upgrade pandas
$ pip install swifter # first time installation
$ pip install swifter[notebook] # first time installation including dependency for rich progress bar in jupyter notebooks
$ pip install swifter[groupby] # first time installation including dependency for groupby.apply functionality
$ pip install -U swifter # upgrade to latest version if already installed
$ pip install -U swifter[notebook] # upgrade to latest version to include dependency for rich progress bar in jupyter notebooks
$ pip install -U swifter[groupby] # upgrade to latest version to include dependency for groupby.apply functionality
alternatively, to install on Anaconda:
conda install -c conda-forge swifter # Install swifter
conda install -c conda-forge swifter>=1.3.2 ray>=1.0.0 # Install swifter with dependency for groupby.apply
...after installing, import swifter into your code along with pandas using:
import pandas as pd
import swifter...alternatively, swifter can be used with modin dataframes in the same manner:
import modin.pandas as pd
import swifterNOTE: if you import swifter before modin, you will have to additionally register modin: swifter.register_modin()
df = pd.DataFrame({'x': [1, 2, 3, 4], 'y': [5, 6, 7, 8]})
# runs on single core
df['x2'] = df['x'].apply(lambda x: x**2)
# runs on multiple cores
df['x2'] = df['x'].swifter.apply(lambda x: x**2)
# use swifter apply on whole dataframe
df['agg'] = df.swifter.apply(lambda x: x.sum() - x.min())
# use swifter apply on specific columns
df['outCol'] = df[['inCol1', 'inCol2']].swifter.apply(my_func)
df['outCol'] = df[['inCol1', 'inCol2', 'inCol3']].swifter.apply(my_func,
positional_arg, keyword_arg=keyword_argval)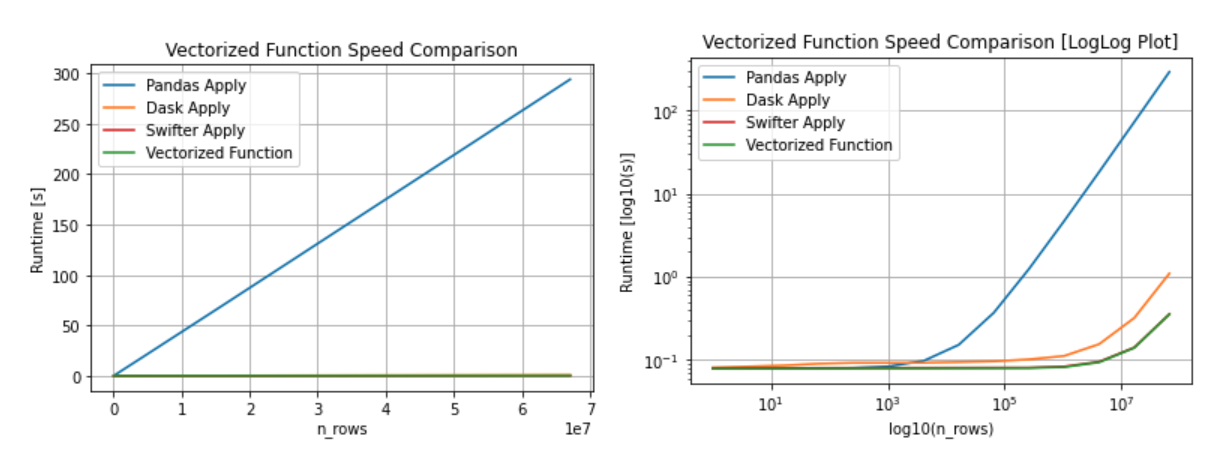
When vectorization is not possible, automatically decides which is faster: to use dask parallel processing or a simple pandas apply
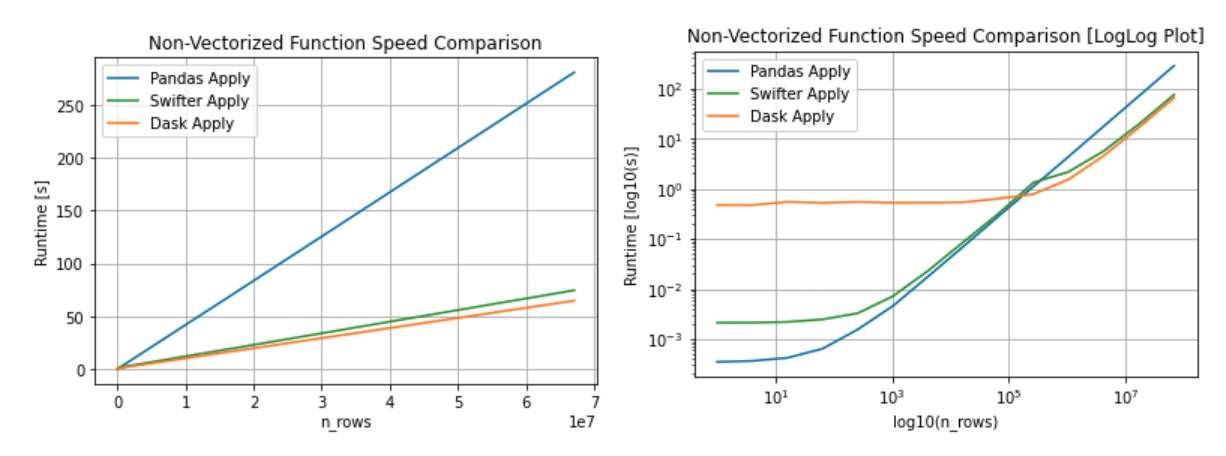
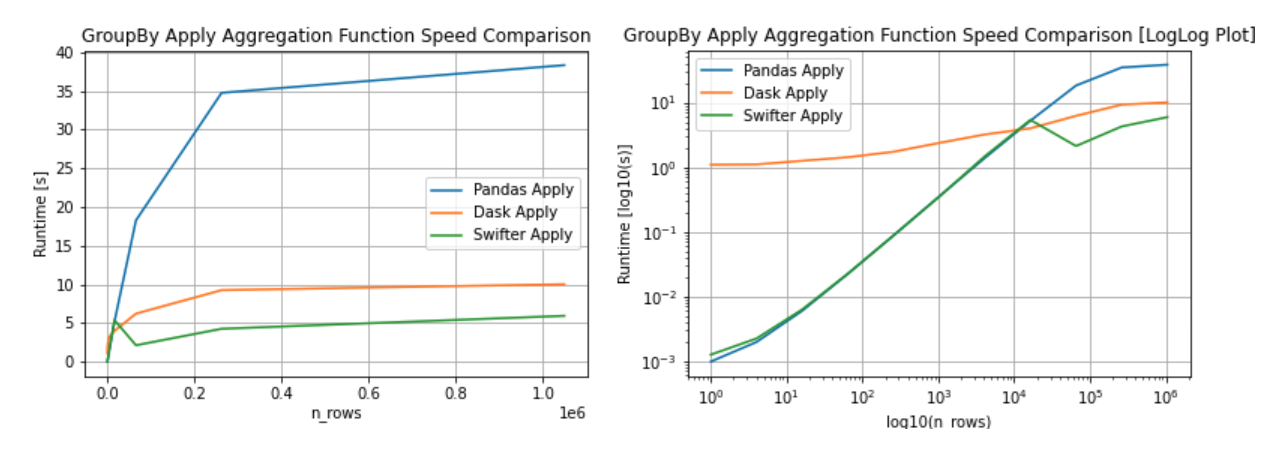
See the speed benchmark notebook for source of the above performance plots.
-
The function is documented in the .py file. In Jupyter Notebooks, you can see the docs by pressing Shift+Tab(x3). Also, check out the complete documentation here along with the changelog.
-
Please upgrade your version of pandas, as the pandas extension api used in this module is a recent addition to pandas.
-
Import modin before importing swifter, if you wish to use modin with swifter. Otherwise, use
swifter.register_modin()to access it. -
Do not use swifter to apply a function that modifies external variables. Under the hood, swifter does sample applies to optimize performance. These sample applies will modify the external variable in addition to the final apply. Thus, you will end up with an erroneously modified external variable.
-
It is advised to disable the progress bar if calling swifter from a forked process as the progress bar may get confused between various multiprocessing modules.
-
If swifter return is different than pandas try explicitly casting type e.g.:
df.swifter.apply(lambda x: float(np.angle(x)))