Inspired from the following blog post: Kudos to Srinath Perera for writing this 👍
Four common classes of machine learning applications:
a. classification
b. predicting next value [also known as regression]
c. anamoly detection
d. discovering data strucuture
As the name suggests, the core focus of anamoly detection is to identify data points that deos not align with the rest of the data. In statistics, these data points are also referred as outliers
Having outliers have significant effect on the mean and the standard deviation of your data and hence your results are skewed if they are not dealt properly
Here are some of the examples where anamoly detection is heavily employed:
a. fraud detection
b. surveillance
c. diagnosis
d. data cleanup
e. monitring predicitive maintenance [IoT devices]
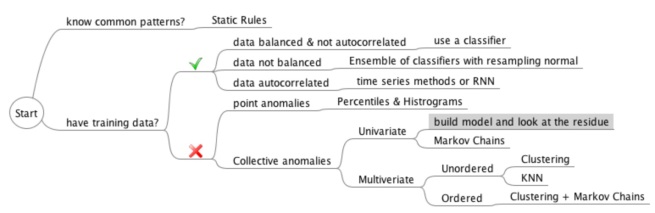
This assumption is correct as long as the following three conditions hold good:
a. Training data present with us is labelled
b. Anomalous and non-anomalous classes are balanced (at least 1:5 proportion)
c. Present data point is not dependent on paast data points [not suitable for time series]
a. Hard to obtain labelled training data all the time
b. Real-life scenarios have heavily imbalanced classes, for e.g. fraud detection in credit cards can have the distribution of 1:10^x where x can go from 3 to 6
c. One more caveat is that of precision and recall scores for such classifiers ? What is the cost of missing a false positive or a false negative ?
[Precision governs of how many anomalies detected by classifiers are truly anamolies]
[Recall governs of how many anomalies the classifier is able to capture]
a. Point Anomalies: Individual instance of data is considered as anomalous with respect to rest of data (e.g. purchase with a large transaction value)
b. Contexual Anomalies: The instance of data is considered as anomalous with respect to the context, but not otherwise (e.g. large spike in a trend at middle of night)
c. Collective Anomalies: Unlike the previous two, here we consider a collection of data instances making up for an anomaly with respect to the rest of data
i. Events that are actually ordered but showing a degree of disorder (e.g. rhythm in ECG)
ii. Unexpected value comnbinations (e.g. buying a large number of expensive items)