🤗 Hugging Face • 🤖 ModelScope • 💬 WeChat

{kind=link}
- 📖 Models Introduction
- 📊 Benchmark Results 🥇🥇🔥🔥
- ⚙️ Inference and Deployment
- 🛠️ Fine-tuning the Model
- 💾 Intermediate Checkpoints 🔥🔥
- 👥 Community and Ecosystem
- 📜 Disclaimer, License and Citation
[2023.12.29] 🎉🎉🎉 We have released Baichuan2-13B-Chat v2 version. In this version:
- Significantly improved the model's overall capabilities, especially in mathematics and logical reasoning, and complex instruction following.
- Baichuan 2 is the new generation of open-source large language models launched by Baichuan Intelligent Technology. It was trained on a high-quality corpus with 2.6 trillion tokens.
- Baichuan 2 achieved the best performance of its size on multiple authoritative Chinese, English, and multi-language general and domain-specific benchmarks.
- This release includes Base and Chat versions for 7B and 13B, and a 4bits quantized version for the Chat model.
- All versions are fully open to academic research. Developers only need to apply via email and obtain official commercial permission to use it for free commercially.
- For more information, welcome reading our technical report Baichuan 2: Open Large-scale Language Models.
The specific released versions and download links are shown in the table below:
| Base Models | Aligned Models | Aligned Models 4bits Quantized | |
|---|---|---|---|
| 7B | 🤗 Baichuan2-7B-Base | 🤗 Baichuan2-7B-Chat | 🤗 Baichuan2-7B-Chat-4bits |
| 13B | 🤗 Baichuan2-13B-Base | 🤗 Baichuan2-13B-Chat | 🤗 Baichuan2-13B-Chat-4bits |
We conducted extensive testing on authoritative Chinese, English and multi-language datasets across six domains: general, legal, medical, mathematics, code, and multi-language translation.
In the general domain, we conducted 5-shot tests on the following datasets:
- C-Eval is a comprehensive Chinese basic model evaluation dataset, covering 52 disciplines and four levels of difficulty. We used the dev set of this dataset as the source for few-shot learning and tested on the test set. Our evaluation approach followed that of Baichuan-7B.
- MMLU is an English evaluation dataset comprising 57 tasks, encompassing elementary math, American history, computer science, law, etc. The difficulty ranges from high school level to expert level. It's a mainstream LLM evaluation dataset. We used its open-source evaluation approach.
- CMMLU is a comprehensive Chinese evaluation benchmark covering 67 topics, specifically designed to assess language models' knowledge and reasoning capabilities in a Chinese context. We adopted its official evaluation approach.
- Gaokao is a dataset utilizing China's college entrance examination questions to evaluate large language models' abilities, focusing on linguistic proficiency and logical reasoning. We retained only its single-choice questions and conducted random partitioning. Our evaluation method is similar to that of C-Eval.
- AGIEval aims to evaluate a model's general abilities in cognition and problem-solving related tasks. We retained only its four-option single-choice questions and did random partitioning. We used an evaluation scheme similar to C-Eval.
- BBH is a challenging task subset of Big-Bench. Big-Bench currently includes 204 tasks. Task themes involve linguistics, child development, mathematics, common sense reasoning, biology, physics, societal biases, software development, etc. BBH consists of benchmark tasks extracted from the 204 Big-Bench tasks in which large models did not perform well.
| C-Eval | MMLU | CMMLU | Gaokao | AGIEval | BBH | |
|---|---|---|---|---|---|---|
| 5-shot | 5-shot | 5-shot | 5-shot | 5-shot | 3-shot | |
| GPT-4 | 68.40 | 83.93 | 70.33 | 66.15 | 63.27 | 75.12 |
| GPT-3.5 Turbo | 51.10 | 68.54 | 54.06 | 47.07 | 46.13 | 61.59 |
| LLaMA-7B | 27.10 | 35.10 | 26.75 | 27.81 | 28.17 | 32.38 |
| LLaMA2-7B | 28.90 | 45.73 | 31.38 | 25.97 | 26.53 | 39.16 |
| MPT-7B | 27.15 | 27.93 | 26.00 | 26.54 | 24.83 | 35.20 |
| Falcon-7B | 24.23 | 26.03 | 25.66 | 24.24 | 24.10 | 28.77 |
| ChatGLM2-6B | 50.20 | 45.90 | 49.00 | 49.44 | 45.28 | 31.65 |
| Baichuan-7B | 42.80 | 42.30 | 44.02 | 36.34 | 34.44 | 32.48 |
| Baichuan2-7B-Base | 54.00 | 54.16 | 57.07 | 47.47 | 42.73 | 41.56 |
| C-Eval | MMLU | CMMLU | Gaokao | AGIEval | BBH | |
|---|---|---|---|---|---|---|
| 5-shot | 5-shot | 5-shot | 5-shot | 5-shot | 3-shot | |
| GPT-4 | 68.40 | 83.93 | 70.33 | 66.15 | 63.27 | 75.12 |
| GPT-3.5 Turbo | 51.10 | 68.54 | 54.06 | 47.07 | 46.13 | 61.59 |
| LLaMA-13B | 28.50 | 46.30 | 31.15 | 28.23 | 28.22 | 37.89 |
| LLaMA2-13B | 35.80 | 55.09 | 37.99 | 30.83 | 32.29 | 46.98 |
| Vicuna-13B | 32.80 | 52.00 | 36.28 | 30.11 | 31.55 | 43.04 |
| Chinese-Alpaca-Plus-13B | 38.80 | 43.90 | 33.43 | 34.78 | 35.46 | 28.94 |
| XVERSE-13B | 53.70 | 55.21 | 58.44 | 44.69 | 42.54 | 38.06 |
| Baichuan-13B-Base | 52.40 | 51.60 | 55.30 | 49.69 | 43.20 | 43.01 |
| Baichuan2-13B-Base | 58.10 | 59.17 | 61.97 | 54.33 | 48.17 | 48.78 |
In the legal domain, we used the JEC-QA dataset. The JEC-QA dataset originates from China's National Judicial Examination. We retained only the multiple-choice questions from it. Our evaluation method was similar to that of C-Eval.
In the medical domain, we used medical-related subjects from general domain datasets (C-Eval, MMLU, CMMLU), as well as MedQA and MedMCQA. We followed an evaluation scheme similar to C-Eval.
- For testing convenience, we used the val set from C-Eval for testing.
- The MedQA dataset comes from medical exams in the US and China. We tested the USMLE and MCMLE subsets from the MedQA dataset, and used a version with five candidates.
- The MedMCQA dataset originates from entrance exams of medical colleges in India. We retained only the multiple-choice questions. Since the test set doesn't have answers, we used the dev set for testing.
- Medical-related subjects included in the general domain datasets are as follows:
- C-Eval: clinical_medicine, basic_medicine
- MMLU: clinical_knowledge, anatomy, college_medicine, college_biology, nutrition, virology, medical_genetics, professional_medicine
- CMMLU: anatomy, clinical_knowledge, college_medicine, genetics, nutrition, traditional_chinese_medicine, virology
We conducted 5-shot tests on the above datasets.
| JEC-QA | CEval-MMLU-CMMLU | MedQA-USMLE | MedQA-MCMLE | MedMCQA | |
|---|---|---|---|---|---|
| 5-shot | 5-shot | 5-shot | 5-shot | 5-shot | |
| GPT-4 | 59.32 | 77.16 | 80.28 | 74.58 | 72.51 |
| GPT-3.5 Turbo | 42.31 | 61.17 | 53.81 | 52.92 | 56.25 |
| LLaMA-7B | 27.45 | 33.34 | 24.12 | 21.72 | 27.45 |
| LLaMA2-7B | 29.20 | 36.75 | 27.49 | 24.78 | 37.93 |
| MPT-7B | 27.45 | 26.67 | 16.97 | 19.79 | 31.96 |
| Falcon-7B | 23.66 | 25.33 | 21.29 | 18.07 | 33.88 |
| ChatGLM2-6B | 40.76 | 44.54 | 26.24 | 45.53 | 30.22 |
| Baichuan-7B | 34.64 | 42.37 | 27.42 | 39.46 | 31.39 |
| Baichuan2-7B-Base | 44.46 | 56.39 | 32.68 | 54.93 | 41.73 |
| JEC-QA | CEval-MMLU-CMMLU | MedQA-USMLE | MedQA-MCMLE | MedMCQA | |
|---|---|---|---|---|---|
| 5-shot | 5-shot | 5-shot | 5-shot | 5-shot | |
| GPT-4 | 59.32 | 77.16 | 80.28 | 74.58 | 72.51 |
| GPT-3.5 Turbo | 42.31 | 61.17 | 53.81 | 52.92 | 56.25 |
| LLaMA-13B | 27.54 | 35.14 | 28.83 | 23.38 | 39.52 |
| LLaMA2-13B | 34.08 | 47.42 | 35.04 | 29.74 | 42.12 |
| Vicuna-13B | 28.38 | 40.99 | 34.80 | 27.67 | 40.66 |
| Chinese-Alpaca-Plus-13B | 35.32 | 46.31 | 27.49 | 32.66 | 35.87 |
| XVERSE-13B | 46.42 | 58.08 | 32.99 | 58.76 | 41.34 |
| Baichuan-13B-Base | 41.34 | 51.77 | 29.07 | 43.67 | 39.60 |
| Baichuan2-13B-Base | 47.40 | 59.33 | 40.38 | 61.62 | 42.86 |
In the mathematics domain, we used the OpenCompass evaluation framework and conducted 4-shot tests on the GSM8K and MATH datasets.
- GSM8K is a dataset released by OpenAI, consisting of 8.5K high-quality linguistically diverse elementary school math application questions. It requires selecting the most reasonable solution based on a given scenario and two possible solutions.
- The MATH dataset contains 12,500 math problems (of which 7,500 belong to the training set and 5,000 to the test set). These problems are collected from math competitions like AMC 10, AMC 12, AIME.
For the code domain, we used the HumanEval and MBPP datasets. Using OpenCompass, we performed a 0-shot test on HumanEval and a 3-shot test on the MBPP dataset.
- Tasks in HumanEval include programming tasks encompassing language understanding, reasoning, algorithms, and basic math to evaluate the functional correctness of models and measure their problem-solving capability.
- MBPP consists of a dataset with 974 Python short functions, textual descriptions of programs, and test cases to check their functional correctness.
| GSM8K | MATH | HumanEval | MBPP | |
|---|---|---|---|---|
| 4-shot | 4-shot | 0-shot | 3-shot | |
| GPT-4 | 89.99 | 40.20 | 69.51 | 63.60 |
| GPT-3.5 Turbo | 57.77 | 13.96 | 52.44 | 61.40 |
| LLaMA-7B | 9.78 | 3.02 | 11.59 | 14.00 |
| LLaMA2-7B | 16.22 | 3.24 | 12.80 | 14.80 |
| MPT-7B | 8.64 | 2.90 | 14.02 | 23.40 |
| Falcon-7B | 5.46 | 1.68 | - | 10.20 |
| ChatGLM2-6B | 28.89 | 6.40 | 9.15 | 9.00 |
| Baichuan-7B | 9.17 | 2.54 | 9.20 | 6.60 |
| Baichuan2-7B-Base | 24.49 | 5.58 | 18.29 | 24.20 |
| GSM8K | MATH | HumanEval | MBPP | |
|---|---|---|---|---|
| 4-shot | 4-shot | 0-shot | 3-shot | |
| GPT-4 | 89.99 | 40.20 | 69.51 | 63.60 |
| GPT-3.5 Turbo | 57.77 | 13.96 | 52.44 | 61.40 |
| LLaMA-13B | 20.55 | 3.68 | 15.24 | 21.40 |
| LLaMA2-13B | 28.89 | 4.96 | 15.24 | 27.00 |
| Vicuna-13B | 28.13 | 4.36 | 16.46 | 15.00 |
| Chinese-Alpaca-Plus-13B | 11.98 | 2.50 | 16.46 | 20.00 |
| XVERSE-13B | 18.20 | 2.18 | 15.85 | 16.80 |
| Baichuan-13B-Base | 26.76 | 4.84 | 11.59 | 22.80 |
| Baichuan2-13B-Base | 52.77 | 10.08 | 17.07 | 30.20 |
We used the Flores-101 dataset to evaluate the multilingual capability of the models. Flores-101 covers 101 languages from around the world. Its data comes from various domains including news, travel guides, and books. We chose the official languages of the United Nations (Arabic, Chinese, English, French, Russian, and Spanish) as well as German and Japanese for testing. Using OpenCompass, we performed 8-shot tests on seven sub-tasks within Flores-101: Chinese-English, Chinese-French, Chinese-Spanish, Chinese-Arabic, Chinese-Russian, Chinese-Japanese, and Chinese-German.
| CN-EN | CN-FR | CN-ES | CN-AR | CN-RU | CN-JP | CN-DE | Average | |
|---|---|---|---|---|---|---|---|---|
| GPT-4 | 29.94 | 29.56 | 20.01 | 10.76 | 18.62 | 13.26 | 20.83 | 20.43 |
| GPT-3.5 Turbo | 27.67 | 26.15 | 19.58 | 10.73 | 17.45 | 1.82 | 19.70 | 17.59 |
| LLaMA-7B | 17.27 | 12.02 | 9.54 | 0.00 | 4.47 | 1.41 | 8.73 | 7.63 |
| LLaMA2-7B | 25.76 | 15.14 | 11.92 | 0.79 | 4.99 | 2.20 | 10.15 | 10.14 |
| MPT-7B | 20.77 | 9.53 | 8.96 | 0.10 | 3.54 | 2.91 | 6.54 | 7.48 |
| Falcon-7B | 22.13 | 15.67 | 9.28 | 0.11 | 1.35 | 0.41 | 6.41 | 7.91 |
| ChatGLM2-6B | 22.28 | 9.42 | 7.77 | 0.64 | 1.78 | 0.26 | 4.61 | 6.68 |
| Baichuan-7B | 25.07 | 16.51 | 12.72 | 0.41 | 6.66 | 2.24 | 9.86 | 10.50 |
| Baichuan2-7B-Base | 27.27 | 20.87 | 16.17 | 1.39 | 11.21 | 3.11 | 12.76 | 13.25 |
| CN-EN | CN-FR | CN-ES | CN-AR | CN-RU | CN-JP | CN-DE | Average | |
|---|---|---|---|---|---|---|---|---|
| GPT-4 | 29.94 | 29.56 | 20.01 | 10.76 | 18.62 | 13.26 | 20.83 | 20.43 |
| GPT-3.5 Turbo | 27.67 | 26.15 | 19.58 | 10.73 | 17.45 | 1.82 | 19.70 | 17.59 |
| LLaMA-13B | 21.75 | 16.16 | 13.29 | 0.58 | 7.61 | 0.41 | 10.66 | 10.07 |
| LLaMA2-13B | 25.44 | 19.25 | 17.49 | 1.38 | 10.34 | 0.13 | 11.13 | 12.17 |
| Vicuna-13B | 22.63 | 18.04 | 14.67 | 0.70 | 9.27 | 3.59 | 10.25 | 11.31 |
| Chinese-Alpaca-Plus-13B | 22.53 | 13.82 | 11.29 | 0.28 | 1.52 | 0.31 | 8.13 | 8.27 |
| XVERSE-13B | 29.26 | 24.03 | 16.67 | 2.78 | 11.61 | 3.08 | 14.26 | 14.53 |
| Baichuan-13B-Base | 30.24 | 20.90 | 15.92 | 0.98 | 9.65 | 2.64 | 12.00 | 13.19 |
| Baichuan2-13B-Base | 30.61 | 22.11 | 17.27 | 2.39 | 14.17 | 11.58 | 14.53 | 16.09 |
The model weights, source code, and configuration needed for inference have been released on Hugging Face. Download links can be found in the table at the beginning of this document. Below, we demonstrate various inference methods using Baichuan2-13B-Chat as an example. The program will automatically download the required resources from Hugging Face.
pip install -r requirements.txt>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> from transformers.generation.utils import GenerationConfig
>>> tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan2-13B-Chat", use_fast=False, trust_remote_code=True)
>>> model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-13B-Chat", device_map="auto", torch_dtype=torch.bfloat16, trust_remote_code=True)
>>> model.generation_config = GenerationConfig.from_pretrained("baichuan-inc/Baichuan2-13B-Chat")
>>> messages = []
>>> messages.append({"role": "user", "content": "解释一下“温故而知新”"})
>>> response = model.chat(tokenizer, messages)
>>> print(response)
"温故而知新"是一句中国古代的成语,出自《论语·为政》篇。这句话的意思是:通过回顾过去,我们可以发现新的知识和理解。换句话说,学习历史和经验可以让我们更好地理解现在和未来。
这句话鼓励我们在学习和生活中不断地回顾和反思过去的经验,从而获得新的启示和成长。通过重温旧的知识和经历,我们可以发现新的观点和理解,从而更好地应对不断变化的世界和挑战。>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan2-13B-Base", trust_remote_code=True)
>>> model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-13B-Base", device_map="auto", trust_remote_code=True)
>>> inputs = tokenizer('登鹳雀楼->王之涣\n夜雨寄北->', return_tensors='pt')
>>> inputs = inputs.to('cuda:0')
>>> pred = model.generate(**inputs, max_new_tokens=64, repetition_penalty=1.1)
>>> print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
登鹳雀楼->王之涣
夜雨寄北->李商隐In the above code snippets, the model loading specifies
device_map='auto', which will use all available GPUs. If you need to specify the device(s) to use, you can control it in a way similar toexport CUDA_VISIBLE_DEVICES=0,1(using the 0 and 1 graphics cards).
python cli_demo.pyWe do not support using this tool for Base Model because it is designed for Chat scenario.
Run the following command using streamlit. It will start a web service locally. You can access it by entering the address provided in the console into your browser. We do not support using this tool for Base Model because it is designed for Chat scenario.
streamlit run web_demo.pyCoding
用户:找到下列数组的中位数[3.1,6.2,1.3,8.4,10.5,11.6,2.1],请用python代码完成以上功能
Baichuan 2:def find_median(numbers):
numbers.sort()
length = len(numbers)
if length % 2 == 0:
return (numbers[length // 2 - 1] + numbers[length // 2]) / 2
else:
return numbers[length // 2]
numbers = [3.1, 6.2, 1.3, 8.4, 10.5, 11.6, 2.1]
print(find_median(numbers))
Math
用户:鸡和兔在一个笼子里,共有26个头,68只脚,那么鸡有多少只,兔有多少只?
Baichuan 2:我们可以用代数方法来解决这个问题。假设鸡的数量为x,兔子的数量为y。根据题目给出的信息,我们可以得到以下两个方程:
1. x + y = 26 (头的总数)
2. 2x + 4y = 68 (脚的总数)
现在我们需要解这个二元一次方程组。首先从第一个方程中解出x:
x = 26 - y
然后将x的表达式代入第二个方程:
2(26 - y) + 4y = 68
52 - 2y + 4y = 68
2y = 16
接下来我们求解y的值:
y = 16 / 2
y = 8
现在我们得到了兔子的数量是8只。将y的值代入x的表达式求得鸡的数量:
x = 26 - 8
x = 18
所以鸡有18只,兔子有8只。
Instruction Following
用户:从现在开始,请你将我接下来说的每一句话翻译成英语,准备好了吗?
Baichuan 2:I'm ready to translate every word you say next into English.
用户:你好
Baichuan 2:Hello
用户:我是Baichuan 2,很高兴认识大家
Baichuan 2:I am Baichuan 2, and I am very happy to meet everyone.
用户:希望通过大家的共同努力,早日迎接AGI时代的到来
Baichuan 2:I hope through the joint efforts of all of us, we can welcome the arrival of the AGI era as soon as possible.
Solving Quizzes
用户:以下物理常识题目,哪一个是错误的?A.在自然环境下,声音在固体中传播速度最快。B.牛顿第一定律:一个物体如果不受力作用,将保持静止或匀速直线运动的状态。C.牛顿第三定律:对于每个作用力,都有一个相等而反向的反作用力。D.声音在空气中的传播速度为1000m/s。
Baichuan 2:本题考查物理基本概念和原理的理解和应用能力。
A项:声音的传播需要介质,在固体、液体和气体的三种介质中,声音在固体中的传播速度是最快的,故A正确; B项:牛顿第一定律是惯性定律,其内容是:一个物体如果没有受到外力的作用,要么保持静止状态,要么保持匀速直线运动状态,直到有外力迫使它改变运动状态为止,故B正确; C项:牛顿第三定律的内容是:对于每一个作用力,都有一个大小相等、方向相反的反作用力,这两个力分别作用在两个相互作用的物体上,故C错误; D项:声音在空气中以波的形式传播,其传播速度与介质的温度、湿度等因素有关,一般情况下,声音在空气中的传播速度约为340m/s左右,而不是1000m/s,故D错误。 因此,本题的正确答案是 D 。
用户:I'm Mike 。I am going to have a busy weekend。On Saturday,I am going to learn how to swim。I will go with my father。Then we are going to have lunch in the restaurant。In the afternoon,we are going to the zoo。We are going to see the pandas。On Sunday,I will finish my homework in the morning。In the afternoon,my parents and I are going to visit my grandparents。We will have dinner together。
阅读短文,判断正确和错误!正确请写T,错误请写F:
1.Mike is going to have a busy weekend()
2.Mike is going to learn how to swim with his father()
3.They are going to have lunch at home()
Baichuan 2:1. T(正确的)
2. T(正确的)
3. F(错误的)
To allow different users and platforms to run the Baichuan 2 model, we have carried out quantization for the Baichuan 2 model (including Baichuan2-7B-Chat and Baichuan2-13B-Chat). This facilitates users to quickly and efficiently deploy the Baichuan 2 model on their respective platforms.
Baichuan 2 utilizes the widely-adopted community quantization method: the BitsAndBytes method. This method ensures that the performance remains largely unchanged after quantization. It has now been integrated into the transformers library and is widely used in the community. BitsAndBytes supports both 4bits and 8bits quantization. Within the 4bits option, it provides FP4 and NF4 formats, with Baichuan 2 selecting NF4 as its 4bits quantization data type.
Based on this quantization method, Baichuan 2 supports both online and offline quantization modes.
For online quantization, we support both 8bits and 4bits. The usage is similar to the method described in the Baichuan-13B project. One simply needs to first load the model into the CPU memory, then invoke the quantize() method, and finally call the cuda() function to copy the quantized weights to the GPU memory. The code for loading the entire model is straightforward. Let's take Baichuan2-7B-Chat as an example:
8bits online quantization:
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-7B-Chat", torch_dtype=torch.float16, trust_remote_code=True)
model = model.quantize(8).cuda() 4bits online quantization:
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-7B-Chat", torch_dtype=torch.float16, trust_remote_code=True)
model = model.quantize(4).cuda() It's worth noting that when using the from_pretrained interface, users typically add device_map="auto". However, when using online quantization, this parameter should be removed; otherwise, an error will occur.
To facilitate user adoption, we offer a pre-quantized 4bits version: Baichuan2-7B-Chat-4bits for download. Loading the Baichuan2-7B-Chat-4bits model is straightforward, just execute:
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-7B-Chat-4bits", device_map="auto", trust_remote_code=True)For 8bits offline quantization, we haven't provided a corresponding version since the Hugging Face transformers library offers the necessary API interfaces. This makes the saving and loading of 8bits quantized models very convenient. Users can implement the saving and loading of 8bits models in the following manner:
# Model saving: model_id is the original model directory, and quant8_saved_dir is the directory where the 8bits quantized model is saved.
model = AutoModelForCausalLM.from_pretrained(model_id, load_in_8bit=True, device_map="auto", trust_remote_code=True)
model.save_pretrained(quant8_saved_dir)
model = AutoModelForCausalLM.from_pretrained(quant8_saved_dir, device_map="auto", trust_remote_code=True)Comparison of memory usage before and after quantization (GPU Mem in GB):
| Precision | Baichuan2-7B | Baichuan2-13B |
|---|---|---|
| bf16 / fp16 | 14.0 | 25.9 |
| 8bits | 8.0 | 14.2 |
| 4bits | 5.1 | 8.6 |
The results on various benchmarks after quantization compared to the original version are as follows:
| Model 5-shot | C-Eval | MMLU | CMMLU |
|---|---|---|---|
| Baichuan2-13B-Chat | 56.74 | 57.32 | 59.68 |
| Baichuan2-13B-Chat-4bits | 56.05 | 56.24 | 58.82 |
| Baichuan2-7B-Chat | 54.35 | 52.93 | 54.99 |
| Baichuan2-7B-Chat-4bits | 53.04 | 51.72 | 52.84 |
C-Eval is tested on val set
It can be seen that the 4bits, compared to bfloat16, has a drop of around 1 ~ 2 percentage points.
Baichuan-13B supports CPU inference, but it should be emphasized that the inference speed on CPU will be very slow. Modify the model loading logic as follows:
# Taking BVaichuan2-7B-Chat as an example
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-7B-Chat", torch_dtype=torch.float32, trust_remote_code=True)Given that many users have made various optimizations on Baichuan 1 (Baichuan-7B, Baichuan-13B), such as compilation optimizations, quantization, etc., to seamlessly apply these enhancements to Baichuan 2, users can perform an offline conversion on the Baichuan 2 model. After this conversion, it can be treated as a Baichuan 1 model. Specifically, users only need to use the script below to offline normalize the last lm_head layer of the Baichuan 2 model and replace the "lm_head.weight". Once replaced, optimizations such as compilation can be applied to the converted model just like with the Baichuan 1 model.
import torch
import os
ori_model_dir = 'your Baichuan 2 model directory'
# To avoid overwriting the original model, it's best to save the converted model to another directory before replacing it
new_model_dir = 'your normalized lm_head weight Baichuan 2 model directory'
model = torch.load(os.path.join(ori_model_dir, 'pytorch_model.bin'))
lm_head_w = model['lm_head.weight']
lm_head_w = torch.nn.functional.normalize(lm_head_w)
model['lm_head.weight'] = lm_head_w
torch.save(model, os.path.join(new_model_dir, 'pytorch_model.bin'))git clone https://github.com/baichuan-inc/Baichuan2.git
cd Baichuan2/fine-tune
pip install -r requirements.txt- To use lightweight fine-tuning methods like LoRA, you must additionally install peft.
- To accelerate training with xFormers, you must additionally install xFormers.
Below, we provide an example of fine-tuning the Baichuan2-7B-Base on a single machine.
Training Data: data/belle_chat_ramdon_10k.json. This sample data was drawn from multiturn_chat_0.8M, consisting of a selection of 10,000 entries, and has been reformatted. The main purpose is to demonstrate how to train with multi-turn data, and effectiveness is not guaranteed.
hostfile=""
deepspeed --hostfile=$hostfile fine-tune.py \
--report_to "none" \
--data_path "data/belle_chat_ramdon_10k.json" \
--model_name_or_path "baichuan-inc/Baichuan2-7B-Base" \
--output_dir "output" \
--model_max_length 512 \
--num_train_epochs 4 \
--per_device_train_batch_size 16 \
--gradient_accumulation_steps 1 \
--save_strategy epoch \
--learning_rate 2e-5 \
--lr_scheduler_type constant \
--adam_beta1 0.9 \
--adam_beta2 0.98 \
--adam_epsilon 1e-8 \
--max_grad_norm 1.0 \
--weight_decay 1e-4 \
--warmup_ratio 0.0 \
--logging_steps 1 \
--gradient_checkpointing True \
--deepspeed ds_config.json \
--bf16 True \
--tf32 TrueFor multi-machine training, you only need to provide the hostfile, the content of which is similar to follows:
ip1 slots=8
ip2 slots=8
ip3 slots=8
ip4 slots=8
....
At the same time, specify the path of the hostfile in the training script:
hostfile="/path/to/hostfile"
deepspeed --hostfile=$hostfile fine-tune.py \
--report_to "none" \
--data_path "data/belle_chat_ramdon_10k.json" \
--model_name_or_path "baichuan-inc/Baichuan2-7B-Base" \
--output_dir "output" \
--model_max_length 512 \
--num_train_epochs 4 \
--per_device_train_batch_size 16 \
--gradient_accumulation_steps 1 \
--save_strategy epoch \
--learning_rate 2e-5 \
--lr_scheduler_type constant \
--adam_beta1 0.9 \
--adam_beta2 0.98 \
--adam_epsilon 1e-8 \
--max_grad_norm 1.0 \
--weight_decay 1e-4 \
--warmup_ratio 0.0 \
--logging_steps 1 \
--gradient_checkpointing True \
--deepspeed ds_config.json \
--bf16 True \
--tf32 TrueThe code already supports lightweight fine-tuning such as LoRA. If you need to use it, simply add the following parameters to the script mentioned above.
--use_lora TrueSpecific configurations for LoRA can be found in the fine-tune.py script.
After fine-tuning with LoRA, you can load the model using the command below:
from peft import AutoPeftModelForCausalLM
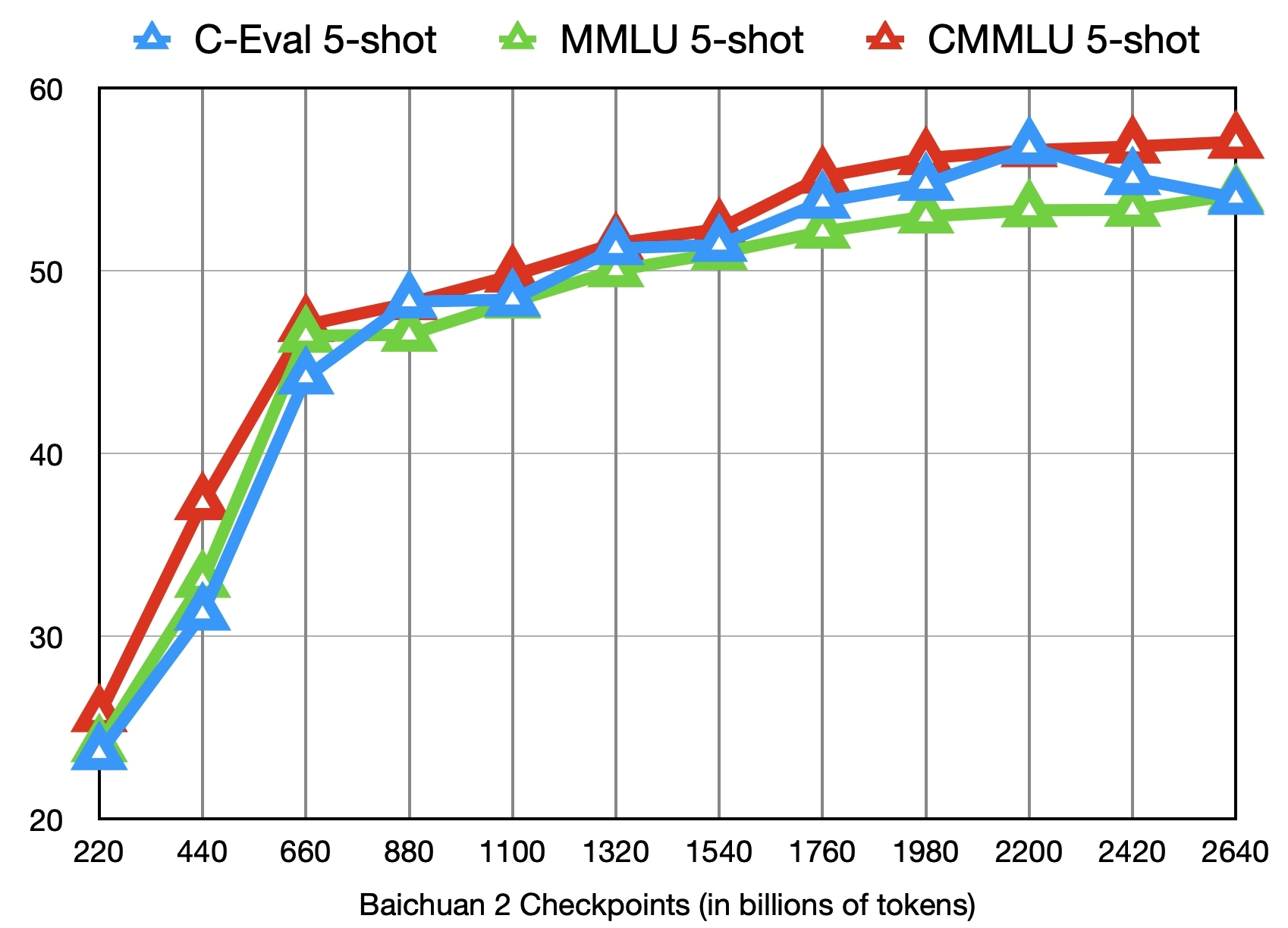
model = AutoPeftModelForCausalLM.from_pretrained("output", trust_remote_code=True)In addition to the Baichuan2-7B-Base model with 2.6 trillion tokens, we also provide 11 intermediate checkpoints (ranging approximately from 0.2 to 2.4 trillion tokens) from before this for community research (Download link). The chart below shows the performance changes of these checkpoints on the C-Eval, MMLU, and CMMLU benchmarks:
📢📢📢 We will continuously update the support for Baichuan 2 from the community and ecosystem here 😀😀😀
When deploy on Core™/Xeon® Scalable Processors or with Arc™ GPU to deploy BaiChuan2 - 7B/Chat and BaiChuan2 - 13B/Chat model.
BigDL-LLM to (CPU, GPU) is recommended to take full advantage of better inference performance.
Model Fine-tuning: Baichuan 2 (7B) already supports PyTorch(2.1.0)+ Transformers(4.36.0)+ DeepSpeed(0.12.4)+ Accelerate(0.25.0)model fine-tuning based on Ascend NPU natively, and can be used without additional adaptation.
Inference Deployment: Baichuan 2 (7B) already supports inference with the Ascend NPU natively, and can be used without additional adaptation.
MindFormers is a comprehensive development suite based on the MindSpore framework that supports large model training, fine-tuning, evaluation, inference, and deployment. Baichuan2-7B / 13B has been integrated into this suite, supporting users in model fine-tuning and deployment. For specific usage, please see the README.
Ascend Large Model Platform based on Ascend's MindSpore AI framework, MindFormers large model development suite, and Ascend hardware computing power, has opened the capabilities of the Baichuan2-7B large model to the public. Everyone is welcome to experience it online.
We hereby declare that our team has not developed any applications based on Baichuan 2 models, not on iOS, Android, the web, or any other platform. We strongly call on all users not to use Baichuan 2 models for any activities that harm national / social security or violate the law. Also, we ask users not to use Baichuan 2 models for Internet services that have not undergone appropriate security reviews and filings. We hope that all users can abide by this principle and ensure that the development of technology proceeds in a regulated and legal environment.
We have done our best to ensure the compliance of the data used in the model training process. However, despite our considerable efforts, there may still be some unforeseeable issues due to the complexity of the model and data. Therefore, if any problems arise due to the use of Baichuan 2 open-source models, including but not limited to data security issues, public opinion risks, or any risks and problems brought about by the model being misled, abused, spread or improperly exploited, we will not assume any responsibility.
The community usage of Baichuan 2 model requires adherence to Apache 2.0 and Community License for Baichuan2 Model. The Baichuan 2 model supports commercial use. If you plan to use the Baichuan 2 model or its derivatives for commercial purposes, please ensure that your entity meets the following conditions:
- The Daily Active Users (DAU) of your or your affiliate's service or product is less than 1 million.
- Neither you nor your affiliates are software service providers or cloud service providers.
- There is no possibility for you or your affiliates to grant the commercial license given to you, to reauthorize it to other third parties without Baichuan's permission.
Upon meeting the above conditions, you need to submit the application materials required by the Baichuan 2 Model Community License Agreement via the following contact email: opensource@baichuan-inc.com. Once approved, Baichuan will hereby grant you a non-exclusive, global, non-transferable, non-sublicensable, revocable commercial copyright license.
If you wish to cite our work, please use the following reference:
@article{baichuan2023baichuan2,
title={Baichuan 2: Open Large-scale Language Models},
author={Baichuan},
journal={arXiv preprint arXiv:2309.10305},
url={https://arxiv.org/abs/2309.10305},
year={2023}
}