- Live Site Review (LSR) — разбор инцидентов
- Архитектурный комитет — ревью архитектуры приложений и сервисов
- Team maturity model — Модель зрелости: как мы оцениваем и растим инженерные команды
Нам важно, чтобы Авито стабильно и надёжно работал. Но бывает, что, несмотря на наши усилия, что-то ломается. Это может быть железо или какой-то архитектурный компонент под высокой нагрузкой. В этом случае важно починить возникшую проблему как можно быстрее. Для этого у нас есть развесистая система мониторинга и алертов, а также служба круглосуточных дежурных.
Помимо того, чтобы быстро восстановить работу сервиса, важно избежать повторения проблем там, где это возможно. А там, где предотвратить аварии совсем нельзя, — минимизировать ущерб как для пользователей, так и для сотрудников.
Поэтому кроме круглосуточного мониторинга у нас есть процесс разбора инцидентов. И сами пожары на проде, и работы по анализу проблем мы называем live site review или LSR. Практика позаимствована у инженеров Google, вот ссылка на книгу по теме.
- Мониторинг в Grafana — общий дашборд по пользовательским событиям.
- Сообщения в специальном канале в Slack.
- Алерты от синтетического мониторинга.
- Алерты от мониторингов сервисов.
Работу с LSR в Авито начали в 2017 году. Процесс несколько раз менялся, и сейчас выглядит так:
- Когда возникает проблема, дежурные видят её в системе мониторинга.
- Дежурные сами чинят проблему или привлекают ответственных от команд.
- Автоматика фиксирует в Jira продолжительность инцидента, затронутую функциональность и недополученную прибыль. Это называется Auto LSR.
- Автоматика же отмечает критичность инцидента в случае больших финансовых потерь или большого количества жалоб от пользователей.
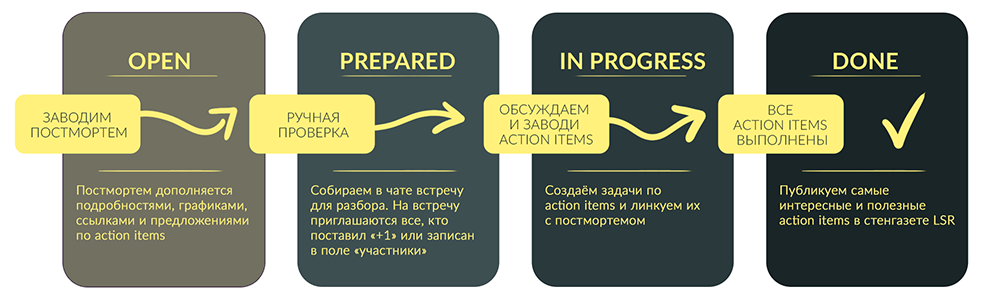
- Мы заводим постмортем тикет в Jira c описанием проблемы, которая вызвала инцидент, если такого еще нет. К нему линкуются Auto LSR.
- Проводим встречу с командой и экспертами и детально разбираем проблему.
- Выполняем все нужные действия по предотвращению подобных инцидентов в будущем.
- Закрываем тикет и дополняем базу знаний.
Простые и понятные проблемы мы разбираем внутри команд или в слак-чатиках. А кросс-командные встречи проводим для серьёзных и бизнес-критичных проблем: инфраструктурных, процессных и тех, которые затронули сразу несколько команд. Встречи открытые, их анонс мы публикуем в отдельном канале, и прийти на них может любой человек в компании.
За работоспособностью всего Авито следит команда с названием «Мониторинг 24/7». Она всегда доступна и смотрит за всеми сервисами. Если случается «взрыв на проде», эта команда первой отправляется тушить пожар и привлекает дежурных разработчиков при необходимости.
Когда сбой устранили, ответственная за функциональность команда выясняет его корневые причины, и любой участник процесса заводит постмортем тикет.

После того, как постмортем тикет заведен, его дополняют данными все желающие. В описание мы вносим любую информацию, которая кажется полезной. Есть единственное правило — описание должно быть таким, чтобы через полгода можно было прочитать и понять написанное. Например, если мы пишем о конкретном дне, то нужна точная дата — «22 сентября», а не «вчера». Если прикладываем ссылку на график, то следим, чтобы не потерялся таймстемп.
В постмортем тикете есть фиксированный набор полей.
Summary (обязательное) — это заголовок. Заголовок мы стараемся заполнять так, чтобы увидев его в календаре или в квартальном отчёте, можно было вспомнить, о чём идёт речь.
Description (обязательное) — здесь описываем суть проблемы, ключевую причину инцидента и любую другую информацию, которая может быть полезна при разборе. Также сюда команды пишут пожелания по разбору, например «обсудим сами внутри кластера» или «обязательно позовите на встречу Васю».
Priority (обязательное) — приоритет тикета. У нас их четыре:
- Critical — проблема из-за которой недоступен весь Авито.
- Major — проблема с высокой вероятностью повторения, недоступна часть функциональности.
- Normal — проблема с невысокой вероятностью повторения, недоступна часть функциональности.
- Minor — проблема с невысокой вероятностью повторения, недоступна часть функциональности без значимого ущерба для пользователей.
Slack link — ссылка на обсуждение инцидента в слаке. Если обсуждений было несколько в разных каналах, то в поле мы вносим наиболее ценное. Остальные в этом случае добавляем в Description.
Команда (обязательное) — проставляем сюда только одну команду, которая стала виновником торжества.
Пострадавшие сервисы — в этом поле перечисляем все сервисы, которые сломались, а также, где была ошибка. Поле нужно для того, чтобы видеть неявные зависимости сервисов и отмечать места, где нужно поработать над graceful degradation.
Участники — здесь указываем всех, кого стоит позвать на встречу с разбором инцидента. В их календари потом придёт приглашение.
Были ли раньше такие проблемы — когда заводится новый постмортем, в поле ставим «нет». Если происходит второй подобный инцидент, линкуем его тикет с постмортемом и меняем описание на «да».
Вероятность повторного возникновения в ближайшие полгода — экспертная оценка того, кто заполняет тикет.
Action items — до проведения встречи пишем сюда идеи, предложения и пожелания по инциденту. Так при обсуждении LSR будет меньше шансов про них забыть. Во время обсуждения это поле редактируется.
Link from Helpdesk — добавляет саппорт, если были обращения пользователей.
HD count — количество пользователей, которые обратились с проблемами по инциденту в HelpDesk. Это поле заполняется и обновляется автоматически, если заполнено поле выше.
Продолжительность — абсолютное значение продолжительности инцидента в минутах.
Когда пожар потушен и тикет заполнен, событие переходит к ответственному из QA-команды. Тот внимательно смотрит на него и разбирается, что происходило, медленно или быстро мы нашли проблему, сразу позвали ответственных дежурных или сначала разбудили непричастных. Ответственный проверяет, хватило ли нам графиков для анализа ситуации, что было написано в логах.
После мы создаём встречу для разбора в специальном LSR-календаре. Во встречах участвуют команды, в сервисе которых возникла проблема, те, кто её устранял, и эксперты по технологиям, в которых проявилась проблема.
На разборах постмортемов мы оцениваем влияние инцидента на работу компании, смотрим на проблему с разных сторон и вырабатываем по ней решение. Если предотвратить возникновение проблемы в будущем невозможно, то придумываем, как уменьшить потери от её возникновения. Обычно ответственный заранее обозначает повестку встречи, и мы идём по списку подготовленных вопросов.
Вот список типовых вопросов, которые стоит обсудить при разборе LSR:
- В чём была проблема и какова её первопричина? Если это баг в коде, то полезно посмотреть на процессы тестирования и понять, почему его не поймали. Если сбой произошёл из-за возросшей нагрузки, то стоит подумать про регулярное нагрузочное тестирование.
- Как быстро и откуда узнали о проблеме? Можно ли узнавать быстрее? Возможно, нужны дополнительные мониторинги или алерты. Или стоит отдать имеющиеся команде мониторинга 24/7.
- Как быстро смогли понять, в чём именно проблема? Возможно, стоит почистить Sentry или добавить логирование.
- Затронула ли проблема основную функциональность сайта и можно ли уменьшить такое влияние? Например, если сломался счётчик количества объявлений, то страницы сайта ломаться не должны. Тут стоит подумать про graceful degradation.
- Может ли проблема повториться в других модулях или компонентах системы? Что сделать, чтобы этого не произошло? Например, актуализировать таймауты, добавить обработку долгого ответа.
- Есть ли платформенное решение, которое помогает избегать таких проблем? Возможно пора начать им пользоваться? В решении таких проблем часто помогают тестохранилка или PaaS.
- Может ли необходимые для решения проблемы действия сделать команда или нужен отдельный проект, объединяющий несколько команд?
Основная ценность, которую мы получаем от встреч — это action items, то есть действия, направленные на то, чтобы проблема не возникала в дальнейшем или чтобы мы раньше её замечали и быстрее чинили. Это могут быть как правки в коде, так и проекты по улучшению инструментов или процессов, предложения новых best practices и информационные рассылки на всю инженерную команду.
Хорошие action items:
- могут быть задачей или проектом, но не процессом;
- всегда имеют ответственного и ожидаемый срок завершения;
- будут сделаны в ближайшие полгода.
Плохие action items:
- похожи на высказывания Капитана Очевидность, например: «нужно лучше тестировать» или «перестать делать глупые баги»;
- точно не будут сделаны в ближайшие полгода.
Мы договариваемся о кусочках, которые надо сделать обязательно, и таких, которые сделать желательно. Когда action items сформулированы, мы заносим их в Jira — это тикеты в разных проектах, слинкованные с постмортемом. В начале описания необязательных задач ставим вопросительный знак, чтобы их можно было сразу отличить. По остальным считаем, что их желательно сделать в течение месяца. Чтобы это работало, отдельный человек следит за выполнением всех action items и периодически проходится с напоминаниями по людям, которым они назначены.
Самые интересные или общественно полезные постмортемы и список рекомендаций по ним мы вносим в базу знаний. Ответственный из QA-команды отбирает их вручную и раз в две недели публикует в общем канале разработки под заголовком «стенгазета LSR». Все выпуски стенгазеты также собраны в Confluence, чтобы можно было быстро найти, как решались те или иные инциденты.
Благодаря стенгазете многие делают исправления в своих сервисах до того, как они сломались. В итоге LSR с одними и теми же причинами в разных командах становится заметно меньше.
Архитектурный комитет – это команда экспертов Авито, которая готова провести ревью архитектуры вашего приложения или высоконагруженного сервиса. Комитет собирается по наличию заявок, но не чаще 2-х раз в неделю. Каждая встреча длится 1.5 часа. Встреча открытая, на нее может прийти любой сотрудник Авито.
- Помочь командам правильно спроектировать сервис или архитектуру.
- Повысить культуру проектирования и осмысленность принятия архитектурных решений.
- Обеспечить место, где
- разработчикам на примере их задач будут подсказывать правильные на текущий момент архитектурные решения;
- можно провалидировать свои решения широким кругом толковых специалистов.
- Снизить риски нестабильной работы Авито в будущем.
В процессе подготовки к презентации команды задумываются над вещами, которые часто упускаются из виду при проектировании. Это помогает точнее спрогнозировать профиль использования и оценить возможные проблемы. В результате мы получаем более качественное решение, которое не придется переделывать сразу после релиза в продакшен.
- Идёт выпил из монолита одного сервиса или группы сервисов, входящих в один из бизнес-критичных путей.
- Делается новое платформенное решение, которое будет использовать кто-то кроме вашего юнита, например:
- Делается высоконагруженный сервис. Основные признаки:
- больше 500 rps или больше 100 тяжелых запросов / сек (по времени исполнения или количеству ресурсов);
- сложная работа с данными, обеспечение их целостности;
- сложная схема масштабирования или ограничения по масштабированию;
- большое количество внешних зависимостей и риски большого latency.
Техлиды отвечают за то, что все необходимые технические решения пройдут защиту архитектурного комитета. У нас действует правило - не уверен, нужен комитет или нет, спроси в специальном чате.
- Нужно проработать и описать решение. Для подготовки нужно использовать один из чек-листов (Описание архитектуры приложения, чек-лист для микросервисов, чек-лист для client-side проектов).
- Когда в календаре появится приглашение на встречу, нужно переслать его всем кому важно знать детали реализации:
- стейкхолдеры;
- потребители;
- смежные команды, которые затронет решение.
- За 2 рабочих дня до встречи нужно прислать слайды презентации и другие полезные документы и ссылки для ознакомления в канал в слаке.
- Практика показывает, что лучше позвать на встречу отдельного члена команды, который будет только записывать фидбек, не участвуя в обсуждении.
- После встречи нужно подготовить и прислать в канал слака выводы и план действий по ним.
- После выводов и планов модератор прошедшей встречи в течение 1-2 рабочих дней собирает дополнительные рекомендации комитета и отправляет команде.
- Если необходимо, модератор организует дополнительную встречу комитета для обсуждения плана действий или результатов его реализации.
- Если архитектурный комитет не пройден, то идёт проработка замечаний и повторная встреча.
Состав участников комитета заранее определён и периодически обновляется, в него входит около 40 человек, представляющие все важные функции и кластеры разработки. Присутствие всех членов комитета на встрече не требуется, состав подбирается модераторами для каждого конкретного кейса. Два человека выполняют роль Модераторов.
Внутри Авито под моделью зрелости мы понимаем список разных инженерных и продуктовых практик. Мы хотим, чтобы разные команды находились по этим практикам на едином базовом уровне или выше. Например, чтобы мы точно понимали, что все команды стремятся к пирамиде тестирования и регулярно проводят ретроспективы.
Чётко прописанная модель зрелости помогает быстро синхронизироваться и находить зоны роста команд. Её задача — выровнять в большом количестве инженерных команд одновременно глубину проникновения и полноту технологий и процессов, которые мы считаем нужными.
Техническому директору важно понимать, в каком состоянии зрелости находятся инженерные команды компании, где нужно усиливать культуру и какие области требуют повышенного внимания. У нас есть задача системно прокачивать команды, и делать это на основе прозрачных и понятных правил.
Нам нужен был инструмент, который описывает базовые вещи по процессам необходимым для работы команды, и практики, которые мы хотим сознательно внедрять. Этот инструмент также должен был помочь математически корректно измерить, насколько каждая команда близка к ожидаемому уровню зрелости.
Мы хотели создать модель, которая помогла бы избежать ряда проблем в будущем:
- Развитие инженерных команд происходит, но понимание базового уровня у всех разное.
- Одни команды знают, что прокачивать, и им нужно лишь задать вектор. Другие команды считают, что они знают, что прокачивать, но качают не то, что нужно компании.
- Есть и команды, которые не хотят прокачиваться, — нет времени точить пилу, потому что надо пилить.
- Когда нет общего стандарта, одни команды могут убежать далеко вперед, а другие — стоять на месте. Через какое-то время им станет тяжело находить общий язык и скоординированно достигать результатов.
- Если ничего не делать, то со временем будут увеличиваться расходы компании на качество. Внесение изменений будет становиться всё дороже и дороже. В итоге пострадает технический или продуктовый бренд.
- Мало кому интересно работать в незрелой команде. Хочется использовать последние технологии и лучшие практики.
Модель зрелости — это техническое задание на то, какой в идеале должна быть инженерная культура компании. Маяк, к которому нужно стремиться, и набор лучших практик. Наша модель зрелости описана в гугл таблице по ссылке ниже.
В первой вкладке документа собраны секции, по которым мы оцениваем свои команды. Секции написаны экспертами в своей области: они определяют базовые уровни и до утверждения финальной формулировки проводят фокус-группы с командами, чтобы не улететь в космос по ожиданиями.
Мы оцениваем зрелость инженерных команд по шести основным блокам:
- Информационная безопасность;
- Обеспечение качества;
- Перформанс;
- Фронтенд;
- Бэкенд;
- Продакт-delivery.
Delivery — процесс от продуктового бэклога до внедрения задачи в продакшен.
Когда мы запускаем новую команду, она изучает модель зрелости и сразу определяет, какие направления надо подтянуть. Уже действующим командам описания уровней дают возможность понять, как им стать круче и быстрее.
Компаниям, которые хотят адаптировать наш документ под себя, рекомендуем сначала написать от одной до трёх секций и попилотировать их в боевом режиме. Когда появится отлаженный процесс, можно будет добавить и другие секции в вашу модель.
В строках вкладки прописан критерий, за который ставится оценка. Каждый столбец — название команды. В каждой ячейке для оценки есть выбор из шести значений. Вот что они значат:
- 0 - Команда на уровне 0 по критериям оценки.
- 1 - Команда на уровне 1 по критериям оценки.
- 2 - Команда на базовом уровне.
- 3 - Команда на уровне 3 по критериям оценки.
- ? - Команда не знает, какую оценку поставить. Нужно оценить уровень на встрече с экспертом.
- N/A - Not applicable — пункт неприменим к конкретной команде. Например, команда инфраструктуры поиска в Авито не ставит себе оценки в секции по фронтенду, так как им не занимается.
Процесс оценки устроен следующим образом:
- Команда встречается раз в квартал, смотрит на свои текущие показатели по модели зрелости и оценивает, насколько они изменились.
- Если произошли изменения, то команда назначает встречу с экспертом по секции. Эксперт комментирует обновлённые оценки и те задачи, которые команда поставила себе на будущее. При желании можно решить вопросы с экспертом асинхронно в чатах. Если команда на 100% уверена в новой оценке, эксперта она не зовёт. Это возможно, когда есть чёткое понимание и стабильный ритм роста по модели.
Каждый квартал мы создаём новую вкладку с оценками. Команды собирают данные, заносят свои оценки в актуальную вкладку и ставят себе новые задачи по росту. Этот процесс повторяется циклично. На выходе мы получаем в таблице единую картину по всем командам и динамику по зрелости квартал к кварталу.
У нас много разных команд, и модель помогает всем, несмотря на различия. Это происходит за счёт того, что мы можем не ставить оценки по конкретным пунктам. В начале пути у нас были мнения, что для продуктовых команд и для технической платформы модели должны быть разными, но в итоге мы решили это противоречие через оценку N/A. Причём может быть так, что внутри одной секции половина пунктов к команде применима, а половина — нет. Ничего страшного в этой ситуации нет, оценка подтверждается через консультацию с экспертом, и в новых кварталах команда на такой пункт модели уже не смотрит.
Также могут быть команды, которые не хотят следовать стандартам в силу своих причин. Такие сложные ситуации должны точечно обрабатывать эксперты: их задача — прийти и выяснить, почему команда считает так, а не иначе. Если стандарты действительно не подходят, то для конкретной команды модель зрелости мы не применяем. Но важно, чтобы это подтвердил эксперт, так как именно он отвечает за установленные технологии и процессы.
Модель зрелости — это своего рода световой меч. Он может быть в руках повстанцев и в руках Империи. Для нас — это ориентир, который помогает командам расти. Они сами определяют, что важно прокачать в первую очередь, что во вторую, и берут эти цели себе в OKR. Мы надеемся, что вы тоже будете использовать модель зрелости во благо.
Неправильно понимать модель зрелости как способ оценить, кто в компании лучше, кто хуже, а потом составить рейтинг, плохих поставить в угол, а хороших — премировать. Мы никого не сравниваем и не наказываем команды за уровни ниже базового.
Не нужно затягивать в секции модели практики, которых ещё вообще нет в компании и использовать её как инструмент масштабирования процессов или практик. Это инструмент для выравнивания и улучшения того, что уже есть в компании. Он не подходит для раскатки нового.
Основная задача технического директора — сделать так, чтобы доставка фичей до клиентов работала как часы, а команда перформила с определённой скоростью и определённым качеством.
Выполнить задачу помогает зафиксированное техническое задание на то, какой должна быть инженерная культура. Модель зрелости это решает и позволяет понимать, что сотрудники действительно делают так, как написано в техническом задании. Это оцифрованная версия того, как работают все команды компании: на базовом уровне или нет. Причём как только команда достигают базового уровня, нужно повысить планку, чтобы у команд снова была мотивация расти.
Для самих команд модель зрелости — это инструмент для поддержки постоянного развития, измеримое понимание, куда стремиться и какого уровня мастерства нужно достичь. Если раньше чётких критериев у нас не было, то теперь легко понять, что значит крепкая инженерка. К списку секций любая команда Авито по желанию может добавить свои критерии и дополнительно стремиться к ним.
Конечная цель внедрения инструмента — сильная инженерная культура. Это просто способ, который позволяет системно прокачивать команды.
Бонусы модели зрелости — коммуникация между командами становится лучше, потому что они следуют одним и тем же стандартам. Нет зоопарка в технологиях и зоопарка в плане процессов. Благодаря общим правилам, всем инженерам компании комфортнее работать друг с другом.
Чтобы модель зрелости работала и приносила компании пользу, нужны:
- Эксперты и их вовлечённость в процесс. Это ключ к росту и динамике.
- Мягкие коммиты от команд, чтобы они сами говорили, что будут прокачивать и когда.
- Контроль процесса и его прозрачность. Нужно, чтобы всё было визуализировано в JIRA, Google Docs или любых других инструментах.
- Эпизодический пересмотр секций и повышение базового уровня.
- Ответственный за саму модель, который сделает так, чтобы шестерёнки проекта крутились на уровне компании.