diff --git a/README.md b/README.md
index 6a92d630f..f81b50026 100644
--- a/README.md
+++ b/README.md
@@ -22,8 +22,10 @@ AMIDST provides tailored parallel (powered by Java 8 Streams) and distributed (p
#Features
-* **Probabilistic Graphical Models**: Specify your model using probabilistic graphical models with latent variables
-and temporal dependencies.
+* **Probabilistic Graphical Models**: Specify your model using probabilistic graphical models with [latent variables](http://amidst.github.io/toolbox/examples/bnetworks.html)
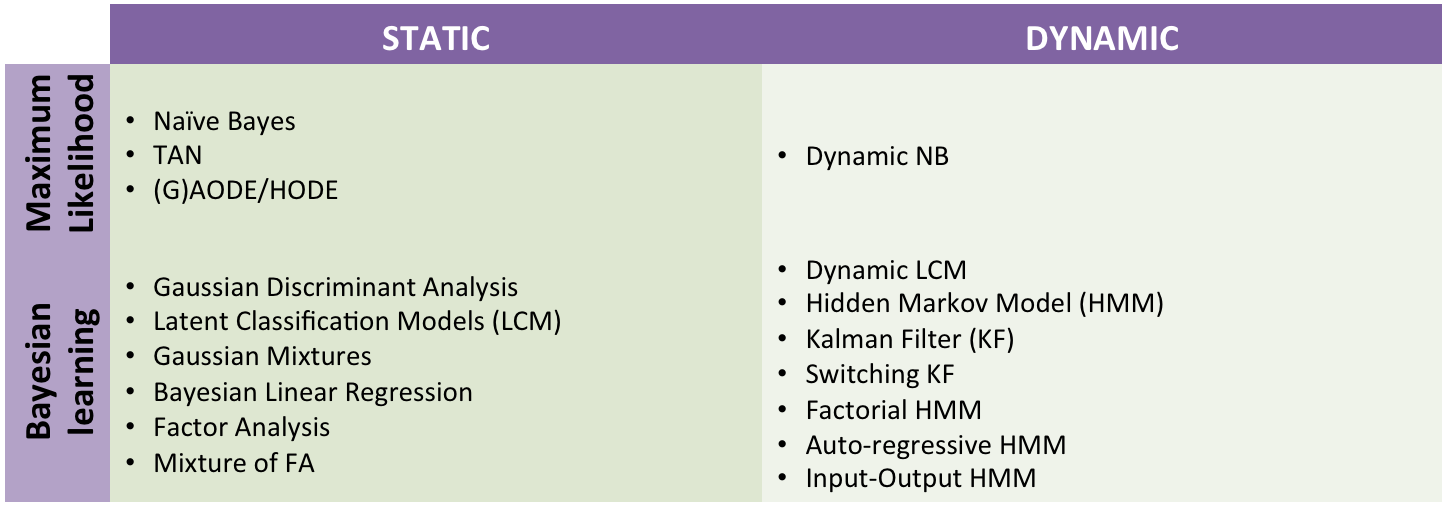
+and [temporal dependencies](http://amidst.github.io/toolbox/DynamicCodeExamples.html). AMIDST contains a large list of predefined latent variable models:
+
+
* **Scalable inference**: Perform inference on your probabilistic models with powerful approximate and
scalable algorithms.
@@ -32,13 +34,13 @@ scalable algorithms.
appropriate for learning from (massive) data streams.
* **Large-scale Data**: Use your defined models to process massive data sets in a distributed
-computer cluster using Apache Flink or (soon) **Apache Spark**.
+computer cluster using **Apache Flink** or (soon) **Apache Spark**.
* **Extensible**: Code your models or algorithms within AMiDST and expand the toolbox functionalities.
Flexible toolbox for researchers performing their experimentation in machine learning.
* **Interoperability**: Leverage existing functionalities and algorithms by interfacing
-to other software tools such as Hugin, MOA, Weka, R, etc.
+to other software tools such as [Hugin](http://amidst.github.io/toolbox/examples/bnetworks.html#sec:bns:huginlink), [MOA](http://amidst.github.io/toolbox/examples/bnetworks.html#sec:bns:moalink), Weka, R, etc.
#Simple Code Example
@@ -148,15 +150,12 @@ architecture and 32 cores. The size of the processed data set was measured accor
-## Distributed Scalablity using [Apache Flink](http://flink.com)
+## Distributed Scalablity using Apache Flink
If your data is really big and can not be stored in a single laptop, you can also learn
your probabilistic model on it by using the AMIDST distributed learning engine based on
-a novel and state-of-the-art [distributed message passing scheme](http://amidst.github.io/toolbox/docs/dVMP.pdf).
-As detailed in this [paper](http://amidst.github.io/toolbox/docs/dVMP.pdf), we learn a probabilistic
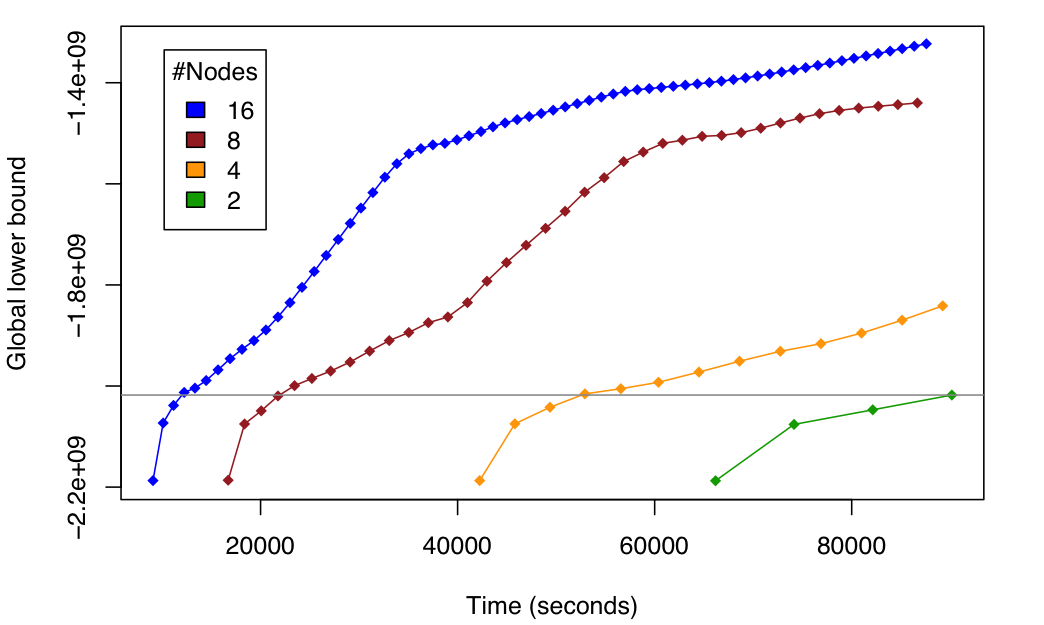
-model similar to the one detailed in the above section from 42 million samples in an Amazon's cluster with
-2, 4, 8 and 16 nodes, each node containing 8 processing units. The following figure shows the scalability of
-our approach under these settings.
+a novel and state-of-the-art [distributed message passing scheme](http://amidst.github.io/toolbox/docs/dVMP.pdf) implemented on top
+of [Apache Flink](http://flink.com). As detailed in this [paper](http://amidst.github.io/toolbox/docs/dVMP.pdf), we were able to perform inference in a billion node (i.e. 10^9) probabilistic model in an Amazon's cluster with 2, 4, 8 and 16 nodes, each node containing 8 processing units. The following figure shows the scalability of our approach under these settings.