Prosograph helps visualize acoustic and prosodic information of long speech segments together with their transcript. Its interactive interface makes it easy to listen to any portion of the displayed speech to accommodate auditory analysis.
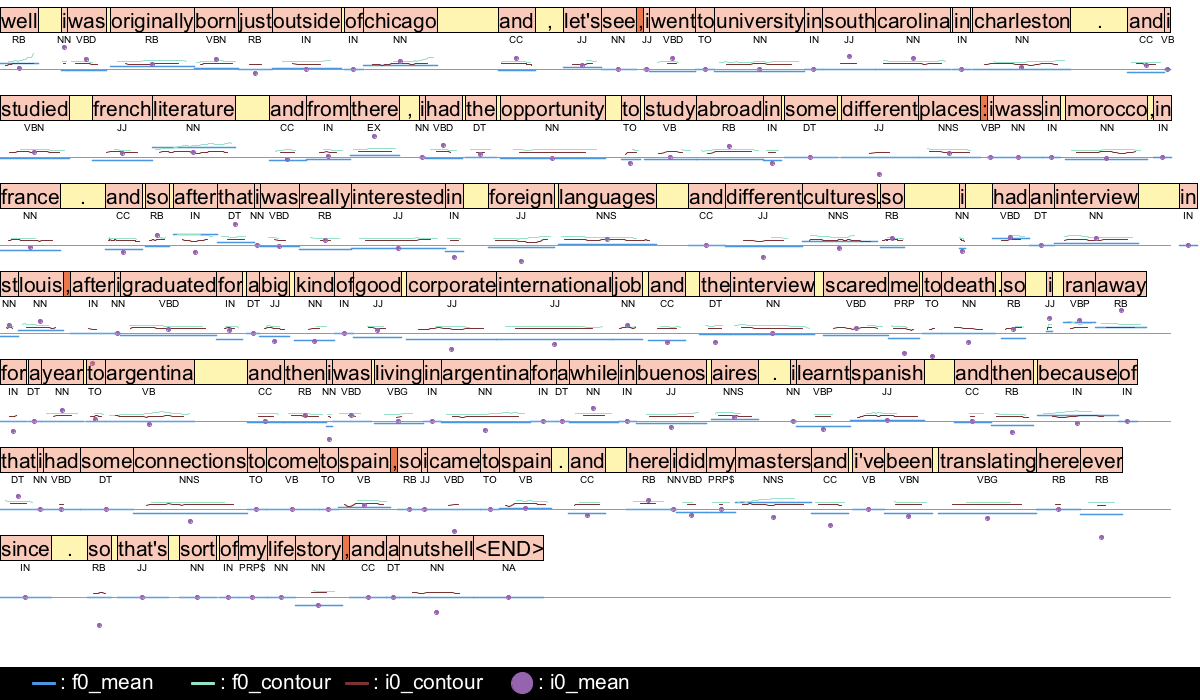
More information on Prosograph can be found in our publication.
Prosograph is written in Python mode of Processing. Once you downloaded and installed Processing, put it in Python mode and then open the main script Prosograph.pyde to run.
minim library needs to be installed for playback. You can do this directly from Processing.
Prosograph reads Proscript files. Two sample datasets are provided in data directory.
Data specific configurations are set in dataconfig_<dataset>.py. Inside this script you need to define DATASET as the path to your proscript file or the directory containing your proscript files. You also need to specify the keys used in your proscript files. The configuration file needs to be imported in main .pyde file on line:
import dataconfig_ted as dataconfig #Specify here which dataconfig you want to use
To view sample datasets, make sure you change DATASET to the exact directory where the dataset resides.
Visual configurations are set in config.py.
Prosograph is operated with the following hotkeys:
N- Skip ahead samplesB- Skip back samplesP- Play/pauseR- Refresh viewS- Save current view as image to diskC- Change colour paletteX,Q- Exit
For playback, audio file needs to be in the same directory and with same name as the proscript file. To play, a section needs to be selected first using left-clicking on wordboxes.
Samples in this repository are taken from the following corpora:
- PANTED corpus - 250 hour speech corpus from TED talks
- Heroes corpus - Parallel English-Spanish speech corpus of dubbed movie segments
To create your own proscript files, please refer to Proscript python library.
If you use this software, please give attribution. If you want to cite it in your work, you can use the following bibliography entries.
Öktem, A., Farrús, M. & Bonafonte, A.
Corpora compilation for prosody-informed speech processing.
Lang Resources & Evaluation 55, 925–946 (2021).
https://doi.org/10.1007/s10579-021-09556-2
Öktem A, Farrús M, Wanner L.
Prosograph: A tool for prosody visualisation of large speech corpora
In: Interspeech 2017; 2017 Aug. 20-24. Stockholm, Sweden.
ISCA; 2017. p. 809-10.