| title |
|---|
MySQL 主备延迟有哪些坑?主备切换策略 |
作者:Tom哥
公众号:微观技术
博客:https://offercome.cn
人生理念:知道的越多,不知道的越多,努力去学
作为一名开发同学,大家对 MySQL 一定不陌生,像常见的 事务特性、隔离级别 、索引等也都是老生常谈。
今天,我们就来聊个深度话题,关于 MySQL 的 高可用
维基百科定义:
高可用性(high availability,缩写 HA),指系统无中断地执行其功能的能力,代表系统的可用性程度。高可用性通常通过提高系统的容错能力来实现。
MySQL 的高可用是如何实现的呢?
首先,我们来看张图

过程:
- 开始时,处理流程主要是
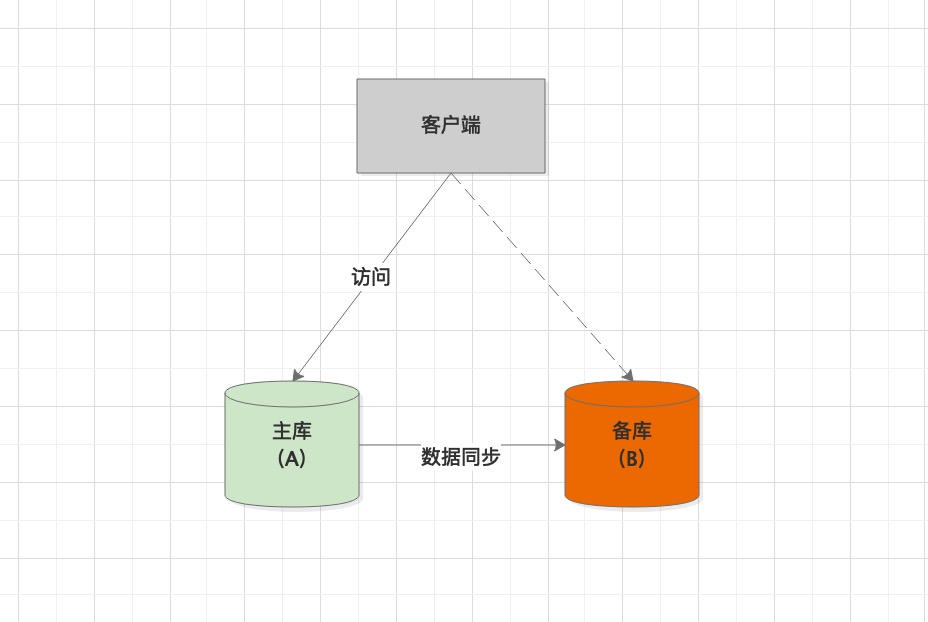
场景一 - 客户端
读、写,访问的是主库 - 主库通过某种机制,将数据实时同步给备库
- 当主库突然发生故障(如:磁盘损坏等),无法正常响应客户端的请求。此时会
自动主备切换,进入场景二 - 客户端读写,访问的是备库(此时备库升级为新主库)

看似天衣无缝,那是不是可以高枕无忧了呢???兄弟,想多了
主备切换,确实能满足高可用。但有个前提,主备库的数据要同步。
不过,数据同步是个异步操作,不可能做到实时,所以说主备延迟是一定存在的
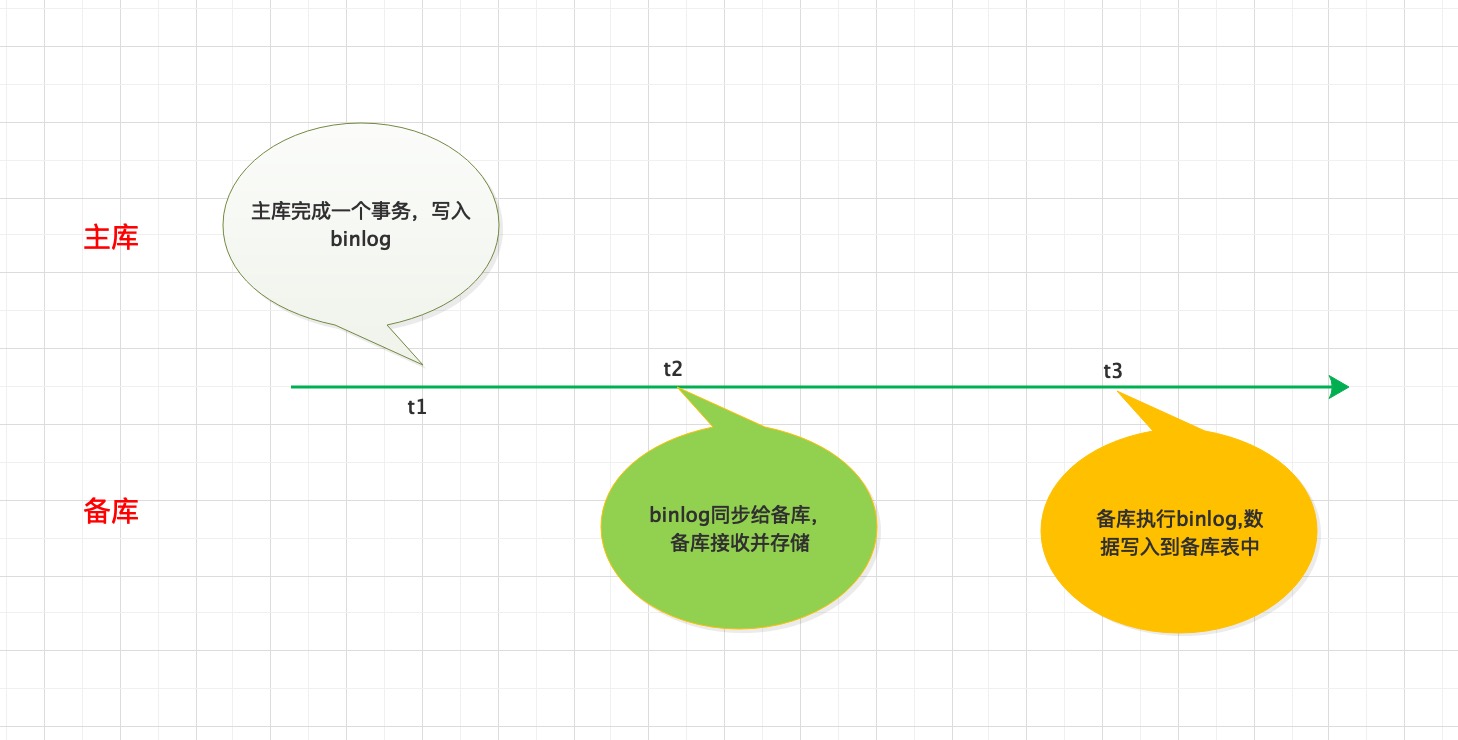
- 主库完成一个事务,写入binlog。binlog 中有一个时间字段,用于记录主库写入的时间【时刻 t1】
- binlog 同步给备库,备库接收并存储到中继日志 【时刻 t2】
- 备库SQL执行线程执行binlog,数据写入到备库表中 【时刻 t3】
主备延迟时间计算公式:
t3 - t1
有没有简单命令,直接查看。在备库执行 show slave status 命令
seconds_behind_master,表示当前备库延迟了多少秒
心细的同学会有疑问了, t3 和 t1 分属于两台机器,如果时钟不一致怎么办?
初始化时,备库连接到主库,会执行 SELECT UNIX_TIMESTAMP() 来获得当前主库的系统时间。
如果发现主库的系统时间与备库不一致,备库在计算 seconds_behind_master 会自动减掉这个差值。
注意:
binlog 数据传输的时间(t2 - t1)非常短,可以忽略。主要延迟花费在备库执行binlog日志
这个不难理解,“门当户对”、“志同道合”,如果主备机器的性能差别大,直接导致备库的同步速度跟不上主库的生产节奏。
就像跑步一样,落后差距会越来越大。
解决方案:
1、升级备库的机器配置
备库除了服务于正常的读业务外,是否有被其他特殊业务征用,如:运营数据统计等,这类操作非常消耗系统资源,也会影响数据同步速度。
解决方案:
可以借助大数据平台,数据异构,满足各种这些特殊的统计类查询。
我们知道 binglog 是在事务提交时才生成的。
如果是处理大事务,执行时间比较长(比如 5分钟)。虽然备库很快拿到 binlog,但是在备库回放执行也要花费差不多的时间,也要 5分钟 (备库中,只有这个事务执行完提交,备库才真正对外可见),从而导致主备延迟很大。
比如 delete 操作,慎用 delete from 表名,建议采用分批删除,减少大事务。
当主库A 发生故障不可用时,开始进入主备切换
- 首先,判断 B库
seconds_behind_master是否小于设定的阈值(比如 4 秒),如果满足条件 - 将 A库 改为只读状态,将 readonly 设置为 true。断掉 A 库的写入操作,保证不会有新的写流量进来
- 判断 B库的
seconds_behind_master,直到为 0 - 修改 B库 为
读、写状态 - 客户端的请求打到 B库
此时,主备切换完成。
优点:
数据不会丢失,所以我们称为可靠性高
缺点:
中间有个阶段,A库和B库都是只读状态,此时系统对外不能提供写服务。
当然我们也可以不用等主备数据同步完成,在一开始时就直接将流量切到备库。
这样备库的流量就可能有两个来源:
- 主库之前的剩余流量 binlog
- 客户端新请求进来的流量
两部分流量冲击,会对 数据一致性 造成一些影响。
我们来做个实验:
首次创建一个用户表:
CREATE TABLE `person` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(32) ,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
插入2条记录
insert into person(name) values ("tom");
insert into person(name) values ("jerry");
实验一:
将 binlog 的格式设为 binlog_format=row
说明: row 模式,写 binlog 时会记录所有字段的值
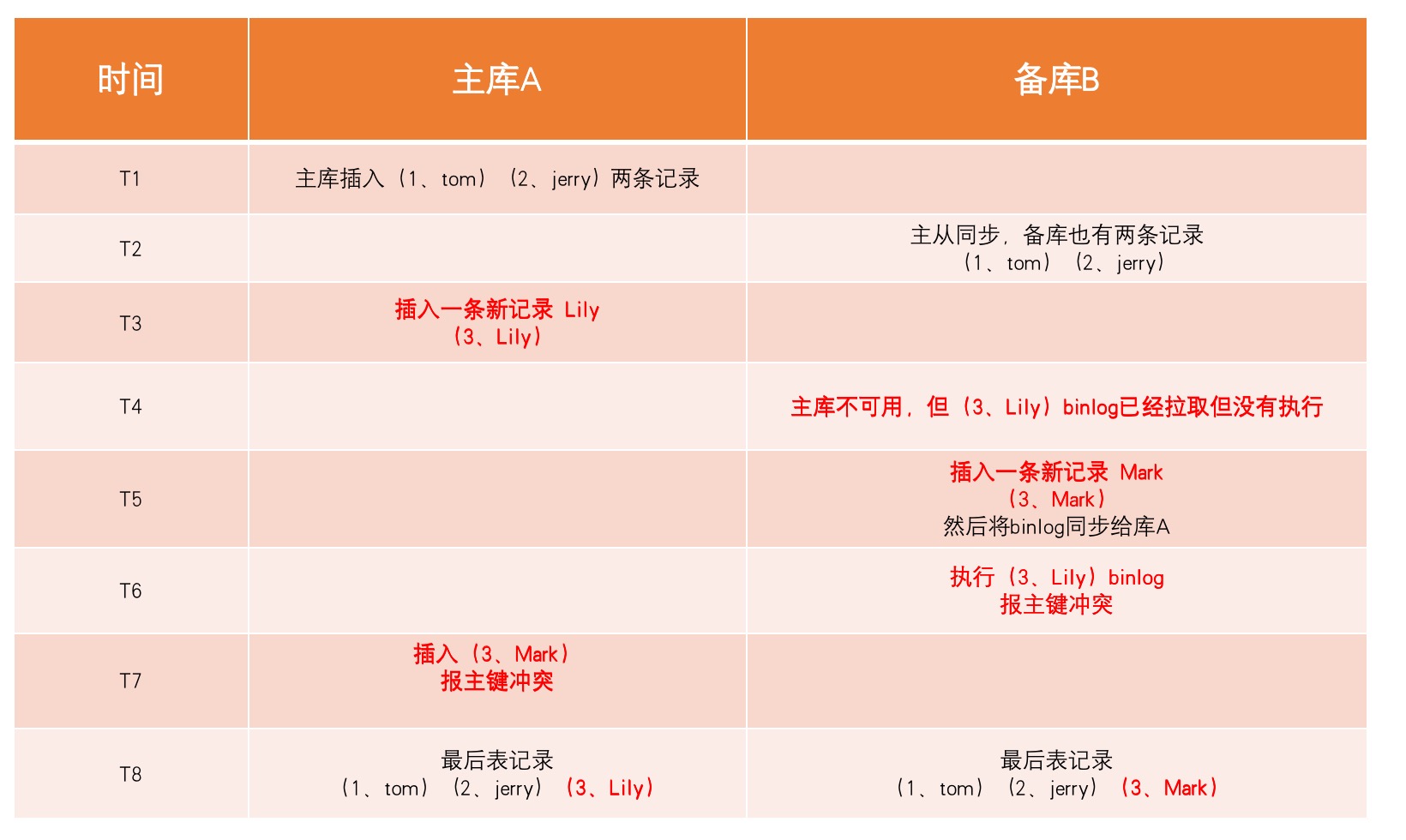
库A 、库B 在做数据同步时,都会报主键冲突,最后只有一行数据不一致,但是会丢数据。
优点:同步过程中,出现问题能够及时发现。
实验二:
将 binlog 格式设置为 statement 或者 mixed
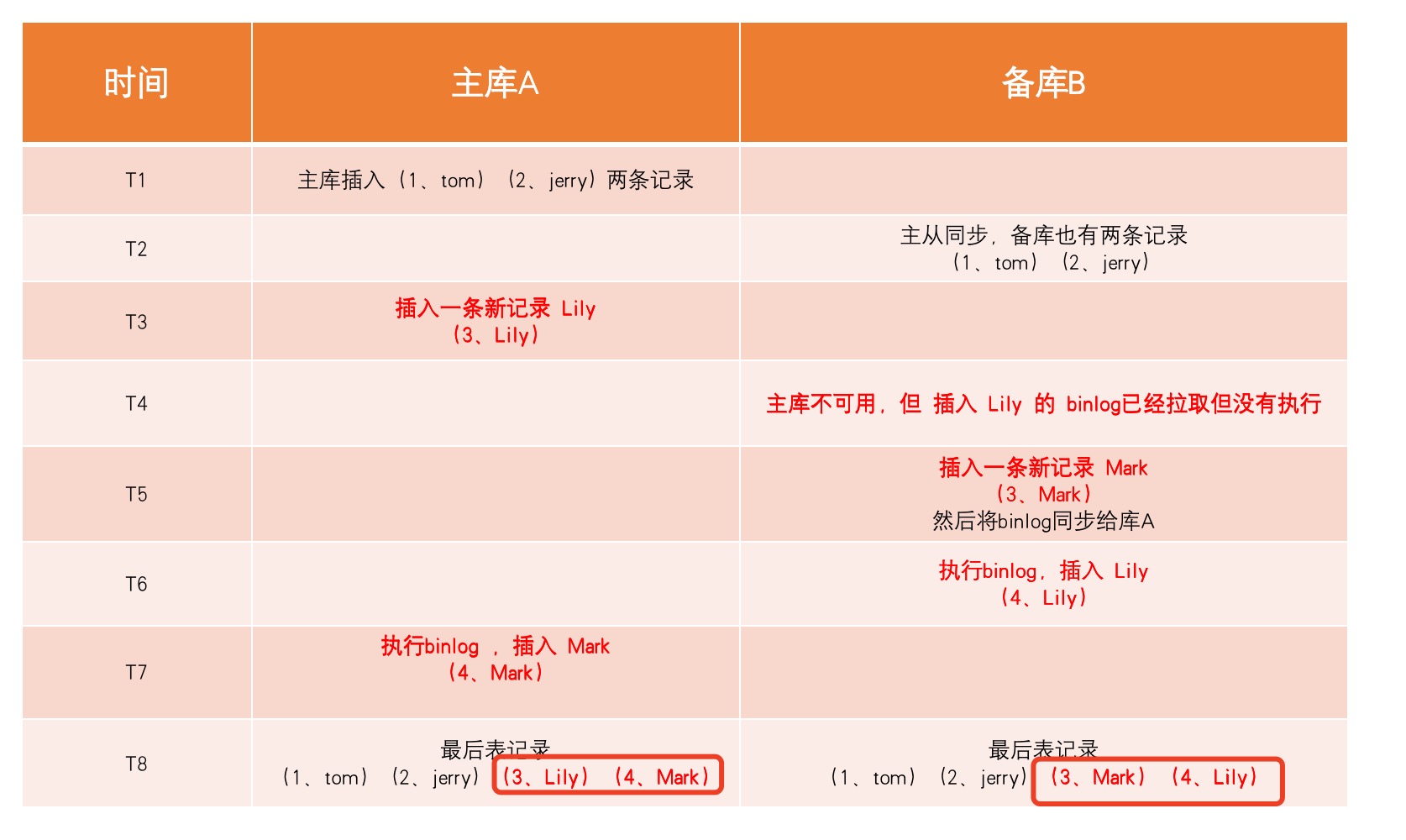
按照 SQL 原始语句同步 binlog,可以看到,数据条数不会少,但是主键id会出现混乱。
3、结论
本着 "攘外必先安内" ,保证内部的数据的正确性是我们的首选。所以,一般建议大家选择 可靠优先。
但是可靠优先可能会导致一定时间内,数据库不可用。这个时间值取决于主备延迟的时间大小。
所以,我们应尽可能缩短主备库的延迟时间大小,这样一旦主库发生故障,备库才会更快的同步完数据,主备切换才能完成,服务才能更快恢复。