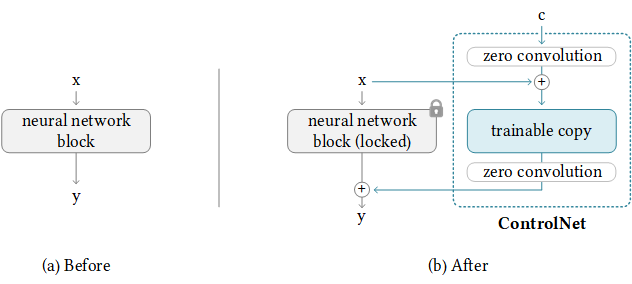
ControlNet 是一种通过添加额外条件来控制扩散模型的神经网络结构。
在运行这部分代码前,我们需要安装develop分支的ppdiffusers库:
cd ppdiffusers
python setup.py install此外我们还需要安装相关依赖:
pip install -r requirements.txt除文本提示外,ControlNet还需要一个控制图作为控制条件。每个预训练模型使用不同的控制方法进行训练,其中每种方法对应一种不同的控制图。例如,Canny to Image要求控制图像是Canny边缘检测的输出图像,而Pose to Image要求控制图是OpenPose骨骼姿态检测图像。目前我们支持如下控制方式及预训练模型。
采用Canny边缘检测图片作为控制条件。
python gradio_canny2image.py

采用Hed边缘检测图片作为控制条件。
python gradio_hed2image.py

采用OpenPose姿态图片作为控制条件。
python gradio_pose2image.py

采用ADE20K分割协议的图片作为控制条件。
python gradio_seg2image_segmenter.py

采用Depth深度检测图片作为控制条件。注意执行该任务需要paddlepaddle-gpu==2.4.2。
python gradio_depth2image.py

采用Normal检测图片作为控制条件。
python gradio_normal2image.py

采用HoughLine检测图片作为控制条件。
python gradio_hough2image.py

(ControlNet V1.1) InstructPix2Pix根据指令修改图像
python gradio_ip2p2image.py

(ControlNet V1.1) Shuffle打乱图像进行重构。
python gradio_shuffle2image.py

作为案例,我们将使用 Fill50K 数据集,带领大家训练 ControlNet 模型。首先我们需要下载数据集。
wget https://paddlenlp.bj.bcebos.com/models/community/junnyu/develop/fill50k.zip
unzip -o fill50k.zip注意:下面的代码需要在32G V100上才可以正常运行。
export FLAGS_conv_workspace_size_limit=4096
python -u train_txt2img_control_trainer.py \
--do_train \
--output_dir ./sd15_control \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 1 \
--learning_rate 1e-5 \
--weight_decay 0.02 \
--lr_scheduler_type "constant" \
--warmup_steps 0 \
--sd_locked True \
--max_steps 10000000 \
--logging_steps 50 \
--image_logging_steps 400 \
--save_steps 2000 \
--save_total_limit 2 \
--seed 23 \
--dataloader_num_workers 4 \
--pretrained_model_name_or_path runwayml/stable-diffusion-v1-5 \
--max_grad_norm -1 \
--file_path ./fill50k \
--recompute True \
--overwrite_output_dirtrain_txt2img_control_trainer.py代码可传入的参数解释如下:
--vae_name_or_path: 预训练vae模型名称或地址,runwayml/stable-diffusion-v1-5/vae,程序将自动从BOS上下载预训练好的权重。--text_encoder_name_or_path: 预训练text_encoder模型名称或地址,runwayml/stable-diffusion-v1-5/text_encoder,程序将自动从BOS上下载预训练好的权重。--unet_name_or_path: 预训练unet模型名称或地址,runwayml/stable-diffusion-v1-5/unet,程序将自动从BOS上下载预训练好的权重。--pretrained_model_name_or_path: 加载预训练模型的名称或本地路径,如runwayml/stable-diffusion-v1-5,pretrained_model_name_or_path的优先级高于vae_name_or_path,text_encoder_name_or_path和unet_name_or_path。--per_device_train_batch_size: 训练时每张显卡所使用的batch_size批量,当我们的显存较小的时候,需要将这个值设置的小一点。--gradient_accumulation_steps: 梯度累积的步数,用户可以指定梯度累积的步数,在梯度累积的step中。减少多卡之间梯度的通信,减少更新的次数,扩大训练的batch_size。--learning_rate: 学习率。--weight_decay:AdamW优化器的weight_decay。--max_steps: 最大的训练步数。--save_steps: 每间隔多少步(global step步数),保存模型。--save_total_limit: 最多保存多少个模型。--lr_scheduler_type: 要使用的学习率调度策略。默认为constant。--warmup_steps: 用于从 0 到learning_rate的线性 warmup 的步数。--image_logging_steps: 每隔多少步,log训练过程中的图片,默认为1000步,注意image_logging_steps需要是logging_steps的整数倍。--logging_steps: logging日志的步数,默认为50步。--output_dir: 模型保存路径。--seed: 随机种子,为了可以复现训练结果,Tips:当前paddle设置该随机种子后仍无法完美复现。--dataloader_num_workers: Dataloader所使用的num_workers参数。--file_path: 训练数据文件夹所在的地址,上述例子我们使用了fill50k目录。--num_inference_steps: 推理预测时候使用的步数。--model_max_length:tokenizer中的model_max_length参数,超过该长度将会被截断。--tokenizer_name: 我们需要使用的tokenizer_name,我们可以使用英文的分词器bert-base-uncased,也可以使用中文的分词器ernie-1.0。--use_ema: 是否对unet使用ema,默认为False。--max_grad_norm: 梯度剪裁的最大norm值,-1表示不使用梯度裁剪策略。--use_paddle_conv_init: 是否使用paddle的卷积初始化策略,当我们开启该策略后可以很快发现在fill50k数据集上,模型很快就收敛了,默认值为False。--recompute: 是否开启重计算,(bool, 可选, 默认为False),在开启后我们可以增大batch_size。--fp16: 是否使用 fp16 混合精度训练而不是 fp32 训练。(bool, 可选, 默认为False)--fp16_opt_level: 混合精度训练模式,可为O1或O2模式,默认O1模式,默认O1. 只在fp16选项开启时候生效。--is_ldmbert: 是否使用ldmbert作为text_encoder,默认为False,即使用clip text_encoder。
Tips:
结合
paddle文档和torch文档可知,paddle卷积层初始化是Xavier Normal,torch卷积层初始化是Uniform,初始化方法边界值是(-sqrt(groups/(in_channels*prod(*kernal_size))), sqrt(groups/(in_channels*prod(*kernal_size))))。


export FLAGS_conv_workspace_size_limit=4096
python -u -m paddle.distributed.launch --gpus "0,1,2,3,4,5,6,7" train_txt2img_control_trainer.py \
--do_train \
--output_dir ./sd15_control \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 1 \
--learning_rate 1e-5 \
--weight_decay 0.02 \
--lr_scheduler_type "constant" \
--warmup_steps 0 \
--sd_locked True \
--max_steps 10000000 \
--logging_steps 50 \
--image_logging_steps 400 \
--save_steps 2000 \
--save_total_limit 2 \
--seed 23 \
--dataloader_num_workers 4 \
--pretrained_model_name_or_path runwayml/stable-diffusion-v1-5 \
--max_grad_norm -1 \
--file_path ./fill50k \
--recompute True \
--overwrite_output_dir待模型训练完毕,会在output_dir保存训练好的模型权重,我们可以使用如下的代码进行推理
from ppdiffusers import StableDiffusionControlNetPipeline, ControlNetModel
from ppdiffusers.utils import load_image
controlnet = ControlNetModel.from_pretrained("./sd15_control/checkpoint-12000/controlnet")
pipe = StableDiffusionControlNetPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", controlnet = controlnet, safety_checker=None)
canny_edged_image = load_image("https://user-images.githubusercontent.com/50394665/221844474-fd539851-7649-470e-bded-4d174271cc7f.png")
img = pipe(prompt="pale golden rod circle with old lace background", image=canny_edged_image, guidance_scale=9, num_inference_steps=50).images[0]
img.save("demo.png")

