之前在文章《你有懒癌?我有WebDriver~》中用Webdriver实现了在网页中模拟人类登录以及操作DOM的功能。其中比较难搞的就是模拟登录,以及cookie的存储和写入。文章发出后很多读者表示期待puppeteer版本。
笔者最近终于抽空用puppeteer重写了这个脚本。没想到用puppeteer处理登录和cookie要简单得多。虽然笔者现在已经用不着这个脚本了,但是作为puppeteer的入门示例还是很好的。
先解释一下puppeteer的实现原理。puppeteer的意思是操纵木偶的人。顾名思义,它使用DevTools协议来操纵浏览器( Chromium或者Chrome),从而允许开发者用它提供的API编程,用来实现Node.js爬虫程序、有/无UI的网页自动化测试、前端监控、生成PDF文件等功能。
下面就看看如何用puppeteer实现网页自动登录和操作DOM的功能。
首先,我们需要安装puppeteer或者puppeteer-core。其实这两者的差别不大,只是puppeteer的功能更全一点,它是基于puppeteer-core构建的。它们的主要区别如下:
puppeteer-core不会在安装过程中自动下载Chromium。puppeteer-core会忽略所有以PUPPETEER_开头的环境变量。
笔者选择puppeteer-core,因为笔者的需求场景不用额外安装Chromium,用本地安装的Chrome就能就解决问题。
安装puppeteer-core的方式很简单,用npm或者yarn即可。比如:
npm i puppeteer-core
官方文档的示例超极简单,先拿来跑跑看:
const puppeteer = require('puppeteer-core');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://so.com');
await page.screenshot({path: 'example.png'});
await browser.close();
})();
不出意外,报错了:
(node:10019) UnhandledPromiseRejectionWarning: Error: Chromium revision is not downloaded. Run "npm install" or "yarn install"
at Launcher.launch (/Users/huangxiaolu/Documents/webtasks/2019/puppeteer-test/node_modules/puppeteer-core/lib/Launcher.js:115:15)
因为以上代码没有指定Chromium的路径(用puppeteer则没有这个问题),所以这里需要用executablePath指定一下。
首先得知道自己的Chrome可执行文件在哪里。大多数人其实不关心也不了解这个问题。笔者在StackOverflow上查到的解决方案是在本地Chrome地址栏中输入chrome://version/,能看到可执行文件的路径。如下图所示:
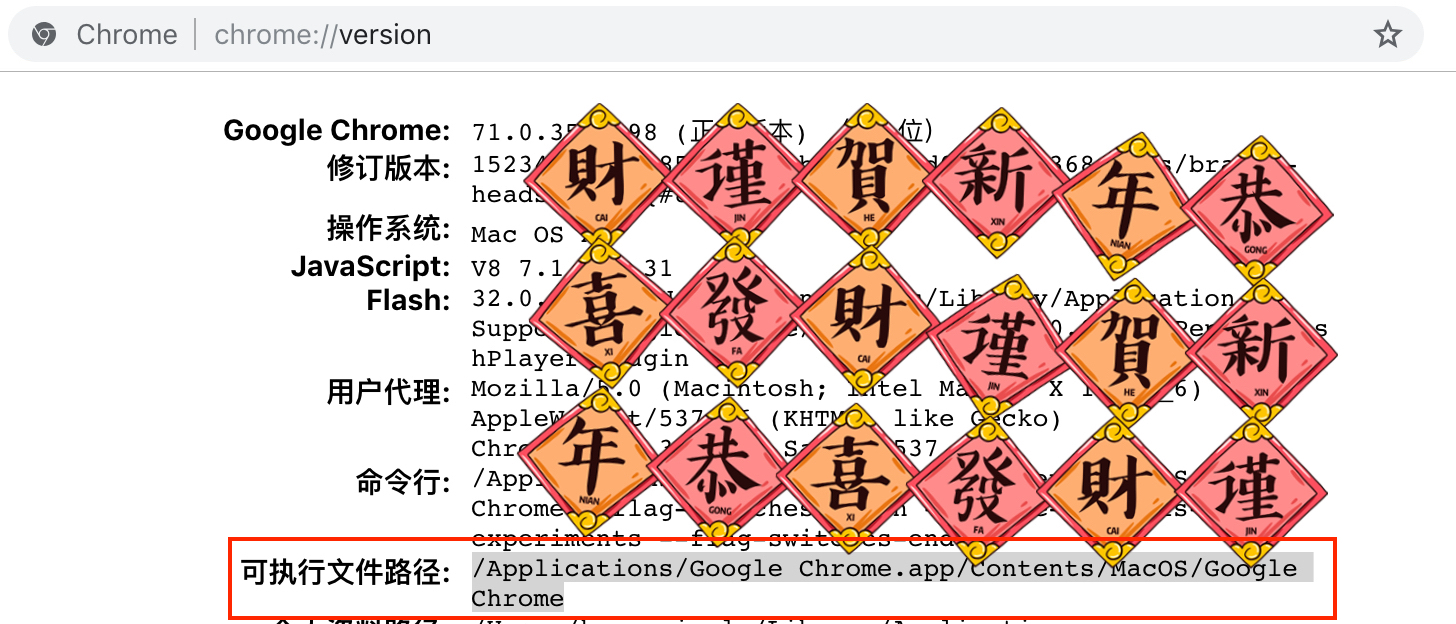
那么将以上代码的配置改为:
const browser = await puppeteer.launch({
executablePath: '/Applications/Google Chrome.app/Contents/MacOS/Google Chrome'
});
试运行一下,果然在项目根目录生成了一张360搜索首页的截图:
看起来好窄哦,没关系,下面会讲到调整视口大小。
试用完毕,开始处理实际需求。首先要解决登录cookie的问题。上次用Webdriver折腾登录流程的时候,需要用Webdriver的API填用户名密码,还要半自动地处理可能出现的验证码,然后等登录后,获取cookie,保存到本地文件中。
笔者这次没有再写一遍登录的流程,而是手动登录了一次。用户信息会自动保存下来,下次再执行程序的时候就会带上cookie。为什么笔者这么懒?因为登录只需要执行一次即可,重点是操作登录后的DOM。所以时间成本上很划算。下面看看如何实现保存用户信息。
先认识一下用户数据路径(User Data Directory)。这是Chrome或者Chromium用于保存用户各种数据(包括历史记录、书签、cookie、配置等)的目录,这个路径也可以用chrome://version/查看。
puppeteer的puppeteer.launch()方法可以配置userDataDir,即用户数据路径。笔者选择在脚本所在目录新建一个文件夹用于存放用户信息,和平时自用的目录互不干扰。同时为了方便直接观察登录状态,把headless置为false,顺便改下defaultViewport把视口放大一点(默认视口实在是太小了)。参数配置如下:
const browser = await puppeteer.launch({
...
userDataDir: 'test-profile-dir',
headless: false,
defaultViewport: {
width: 1000,
height: 800
}
});
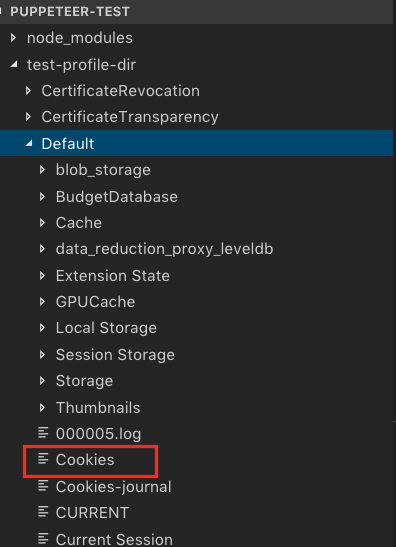
运行程序,会在脚本所在的目录创建“test-profile-dir”目录,同时会自动生成一些目录和文件,如下图所示,红框部分就是cookie了:
这时候打开目标网页会发现处于登出状态。手动输入用户名密码并登录之后,即可退出脚本程序。
理论上用户信息已经更新到“test-profile-dir”目录中。实测并不是很稳定,在笔者的Chrome上需要在登录后等一分钟左右再退出程序,才能保证下次运行时带上cookie。感觉最靠谱的方式还是用page.setCookie()等方法实现cookie的存取和设置啊。
Anyway,登录之后,就可以操纵指定的DOM了。实现逻辑跟上一篇文章用WebDriver实现的流程类似。也是等目标页面渲染后,点击页面元素。只是API略有不同,相比WebDriver的API简化不少。示例代码如下:
await page.goto('https://example.com/path');
await page.waitFor(3000);
await page.click('.target-selector'); // 点击指定元素
同样是点击页面指定元素,用WebDriver实现的代码就长多了:
driver.findElement(webdriver.By.css('.target-selector')).click();
对比下来感觉puppeteer的API更符合前端开发者的习惯。
其他的DOM操作API还有许多,大家可以根据自己的需求参考文档:page类。
本文用一个简单的场景介绍了puppeteer的安装和使用。其中可能会踩坑的地方在于用puppeteer-core的额外配置,比如Chrome的路径,cookie的存储目录等。总体来讲,puppeteer更符合前端开发习惯,推荐大家使用~